
اكتشف السمية في التعليقات باستخدام الذكاء الاصطناعي
نهاية Perspective: ما الذي حدث
في أكتوبر 2024، أعلن Google أن Perspective API — الخدمة المجانية الأكثر استخدامًا في العالم لاكتشاف المحتوى السام — ستُوقف رسميًا في ديسمبر 2026. المنصات التي تعتمد عليها (Reddit، New York Times، The Guardian، وآلاف المنتديات) لديها عامان للهجرة.
المشكلة: كان Perspective مجانيًا. أما البدائل التجارية مثل Azure Content Safety وAWS Comprehend فتبدأ أسعارها من دولار واحد لكل 1,000 تحليل. بالنسبة لمنتدى كبير يستقبل 100,000 تعليق يوميًا، يعني ذلك 3,000 دولار شهريًا على الإشراف وحده.
تقدم Brainiall حلول إشراف باستخدام نماذج Detoxify وUnitary تعمل محليًا عبر ONNX على المعالج (CPU)، بتكلفة أقل من 0.001 ريال لكل تحليل — أرخص بـ 100 مرة.
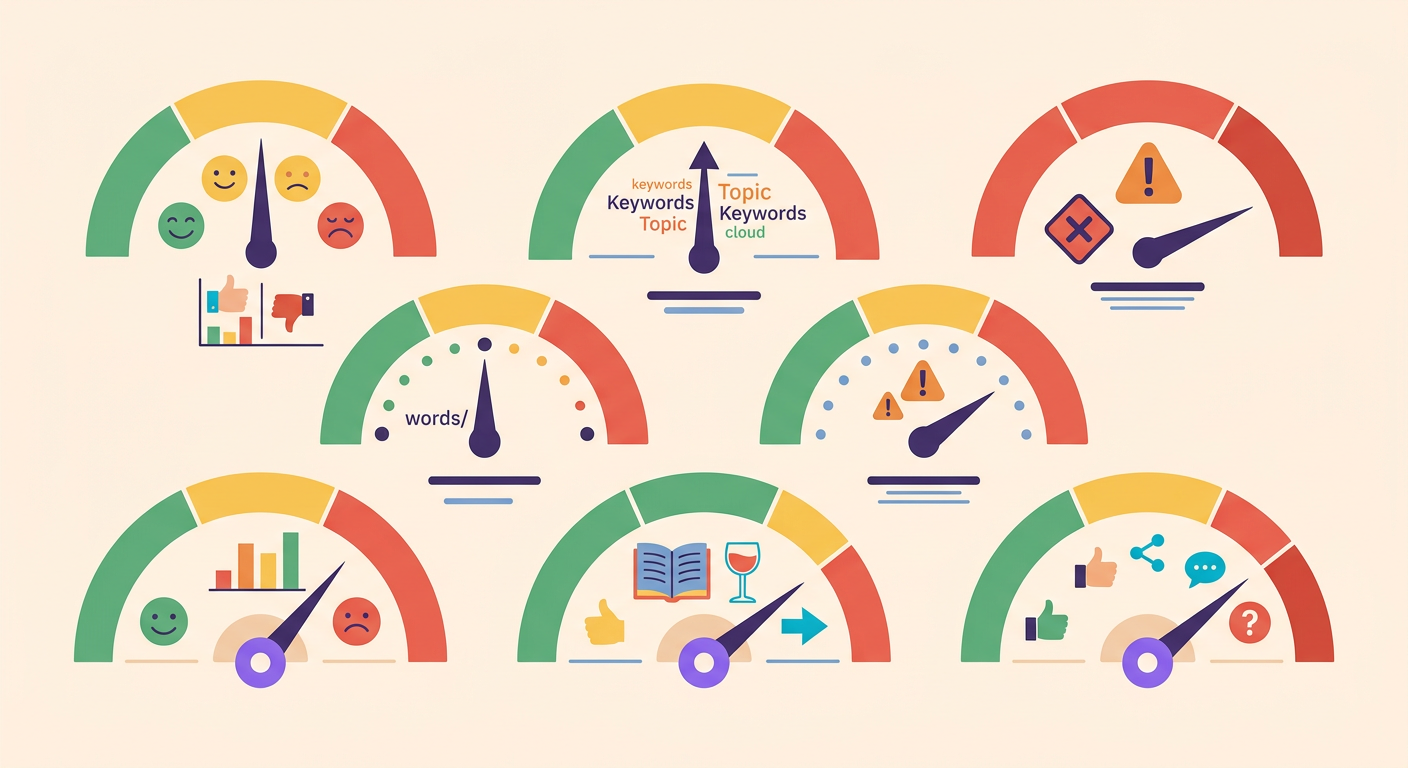
الفئات السبع التي تهمك
يصنّف Detoxify النصوص في 7 أبعاد بدرجة تتراوح بين 0 و1:
1. Toxicity: الإهانة العامة والعدوانية
2. Severe toxicity: التهديد والكراهية الشديدة
3. Obscene: الألفاظ النابية واللغة البذيئة
4. Threat: التهديد بالعنف الجسدي
5. Insult: الهجوم الشخصي المباشر
6. Identity hate: التمييز القائم على الانتماء (العرق، الجنس، الدين)
7. Sexual explicit: المحتوى الجنسي الصريح
سياستك هي التي تحدد العتبات. مثال شائع: الحجب إذا كان severe_toxicity > 0.5 أو identity_hate > 0.6 أو threat > 0.3. الألفاظ النابية المنفردة (obscene > 0.8) تمر عادةً بتحذير دون حجب.
تحدي اللغة العربية
تم تدريب Detoxify على اللغة الإنجليزية، وتصل دقته إلى 95%+ مع التعليقات الإنجليزية. أما مع اللغات الأخرى كالعربية، فقد تنخفض الدقة إلى 75-85%، إذ تُربك المصطلحات المحلية والعامية الخاصة النموذجَ.
في Brainiall نستخدم طبقة إضافية: مصنّف هجين يجمع بين:
- Detoxify متعدد اللغات (70% من القرار)
- قائمة كلمات خاصة بالمنطقة المستهدفة (20%)
- LLM صغير (Gemma 3 أو ما يماثله) للحالات الحدية (10%)
يرفع هذا الدقة إلى 92%+ مع الحفاظ على زمن استجابة أقل من 80ms.
حين يُخطئ الذكاء الاصطناعي بشكل خطير
- السخرية: "أحببت كيف دمّرت حياتي، شكرًا!" — درجة إيجابية، لكن النص عدائي
- الساخر المشروع: النقد السياسي الفكاهي قد يُصنَّف كهجوم
- السياق الطبي: "سأقتل المريض من كثرة العمل" (عامل صحي منهك) — إيجابي كاذب
- الاقتباسات: مقال يقتبس منشورًا عنصريًا لانتقاده يُحلَّل كأنه المنشور العنصري نفسه
- تبديل الشفرات: من يمزج لغات متعددة مع الرموز التعبيرية يُربك النموذج
الحل العملي: ادمج الدرجة التلقائية مع الإشراف اللطيف (طلب التأكيد قبل النشر) بدلًا من الحجب الفوري للحالات الحدية.
التكامل مع منصتك
التدفق الموصى به:
1. يكتب المستخدم تعليقًا ← أرسل طلب POST /api/toxicity مع { text }
2. تعيد API النتيجة: { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. يقرر كودك: الحجب، التحذير، أو الموافقة
4. في حالة التحذير، اعرض "راجع — قد يُسيء لبعض المستخدمين" قبل النشر
5. في حالة الحجب، سجّل الحدث وأبلغ فريق الإشراف البشري
لا تعتمد على الإشراف التلقائي بنسبة 100%. احتفظ دائمًا بطابور بشري للحالات الحدية.
جرّبه الآن
في محادثة Brainiall، اطلب "حلّل سمية هذا التعليق: [الصق هنا]". أو عبر API على المسار /api/nlp/toxicity. تشمل خطة Pro 10,000 تحليل شهريًا؛ وتوفر خطة Business طابور أولوية ومعالجة دفعية لملايين التعليقات.