
تحدث بالصوت (STT → LLM → TTS pipeline)
تشريح المحادثة الصوتية
المحادثة الصوتية مع الذكاء الاصطناعي هي سلسلة من 3 APIs:
`
[تتكلم] → الميكروفون → STT (Whisper) → نص
↓
LLM (Claude/GPT)
↓
[تسمع] ← السماعة ← TTS (pf_dora) ← نص`
كل خطوة تضيف تأخيرًا. لكي تبدو التجربة طبيعية (كمحادثة بشرية)، يجب أن يبقى الإجمالي أقل من 1.5 ثانية. في عام 2026، هذا قابل للتحقيق لكنه يتطلب هندسة دقيقة.
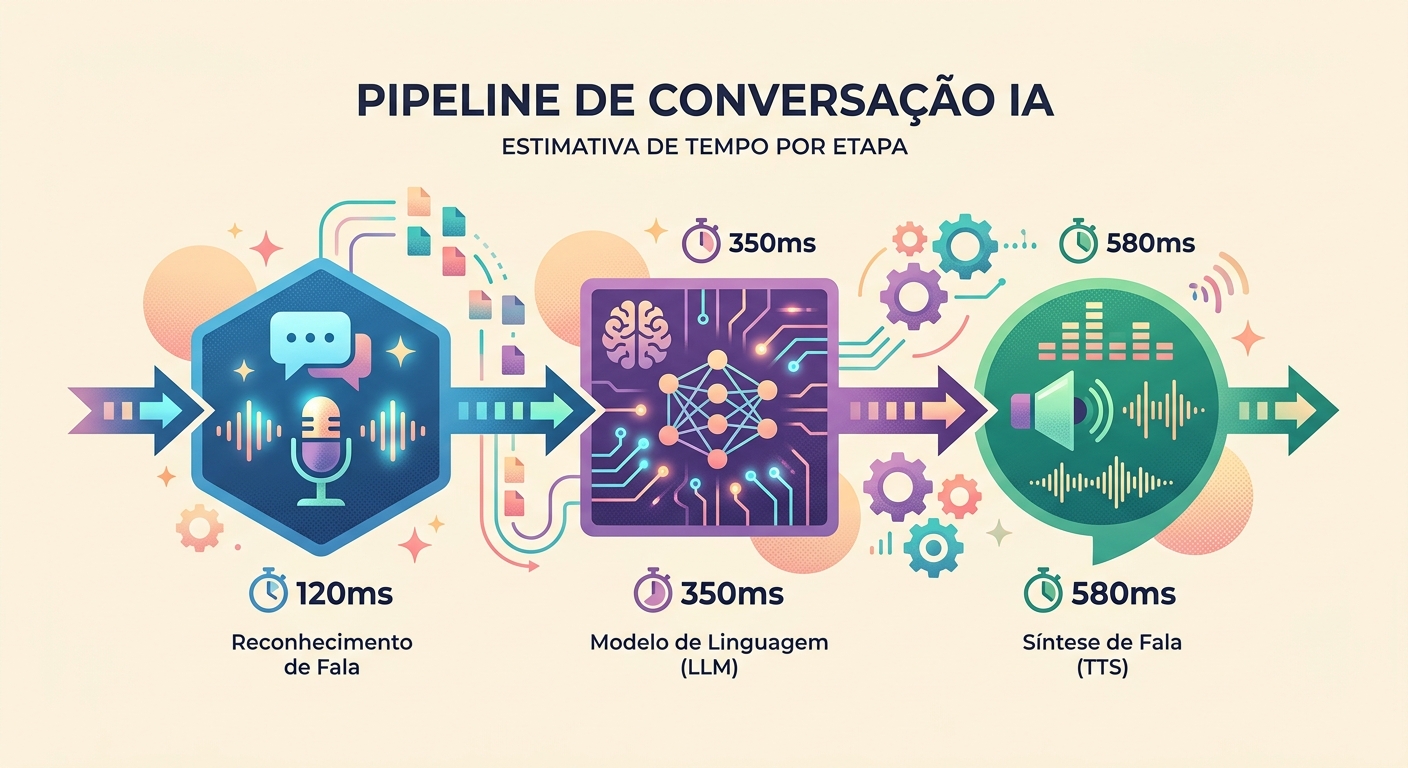
التأخير الواقعي في 2026
قياسات من محادثة حقيقية على Brainiall:
- التقاط الصوت (ميكروفون → WAV): ~100ms (يعتمد على الجهاز)
- STT (Whisper Large v3): 300-600ms لجملة مدتها 3-5 ثوانٍ
- LLM (Claude Haiku للسرعة): 400-900ms للرمز الأول
- TTS (pf_dora عبر unified-api): 300-500ms لصوت مدته 3-5 ثوانٍ
- تشغيل الصوت (تأخير السماعة): ~50ms
إجمالي first-token-to-speech: 1150-2150ms. مقبول إذا بدأ النموذج "بالكلام" مبكرًا (streaming).
Streaming هو كل شيء
بدون streaming، تنتظر كل خطوة انتهاء السابقة: 600ms + 900ms + 500ms = 2000ms كحد أدنى.
مع streaming:
- يمكن لـ STT البدء بالنسخ بينما لا تزال تتكلم (VAD — Voice Activity Detection)
- يبدأ LLM بتوليد الرموز قبل انتهاء STT (مع بعض التنبؤ بالنية)
- يبدأ TTS بنطق الكلمات الأولى بينما لا يزال LLM يولّد الأخيرة
ينخفض التأخير الفعلي إلى 400-700ms. يبدو طبيعيًا تمامًا.
VAD: متى تتوقف عن الاستماع
المشكلة الأكثر دقة: اكتشاف أنك توقفت عن الكلام. إذا توقفت مبكرًا جدًا، تُقطع جملتك. وإذا توقفت متأخرًا، يُضاف 500ms من التأخير.
التقنيات المستخدمة:
- صمت مطلق لمدة 600ms: بسيط لكنه لا يتعامل مع توقفات التفكير الطبيعية
- Silero VAD: نموذج عصبي يكتشف نهاية الجملة بدقة ~95% في أقل من 50ms
- Confidence من STT: يُعيد Whisper قيمة الثقة؛ إذا انخفضت، فالكلام انتهى على الأرجح
- Interruption detection: إذا عاد المستخدم للكلام → يُلغى TTS الجاري ويبدأ الدورة من جديد
تستخدم Brainiall Silero VAD مع عتبة صمت ديناميكية (تتكيف مع بيئة الصوت).
اختيار النموذج: التأخير مقابل الجودة
في وضع الصوت، عادةً ما يستحق التضحية ببعض جودة LLM مقابل السرعة:
- Claude Haiku 4.5: ~400ms للرمز الأول، ردود مباشرة، R$ 2/1M رمز
- GPT-5 mini: ~350ms، أكثر إبداعًا من Haiku، R$ 3/1M رمز
- Gemini 3 Flash: ~250ms، ممتاز للردود القصيرة، R$ 2/1M رمز
للمحادثات التي تُقدّم الجودة على السرعة (مثل: مدرّس لغات تفصيلي)، انتقل إلى Claude Sonnet 4.6 أو GPT-5 الكامل.
حالات الاستخدام التي يُتقنها وضع الصوت
- تدريب المحادثة في اللغات: تدرّب على التحدث بالإنجليزية مع ذكاء اصطناعي يرد بشكل طبيعي
- مساعد بدون يدين: أثناء القيادة، الطهي، أو ممارسة الرياضة
- إمكانية الوصول: للأشخاص الذين يجدون صعوبة في الكتابة
- العصف الذهني أثناء المشي: تسجيل الأفكار بالكلام بدلًا من الكتابة
- التدريس: سؤال وجواب سريع، تدفق تعليمي أكثر طبيعية
- الشركات — خدمة العملاء الهاتفية: استبدال الأنظمة الصوتية التقليدية بمحادثة طبيعية
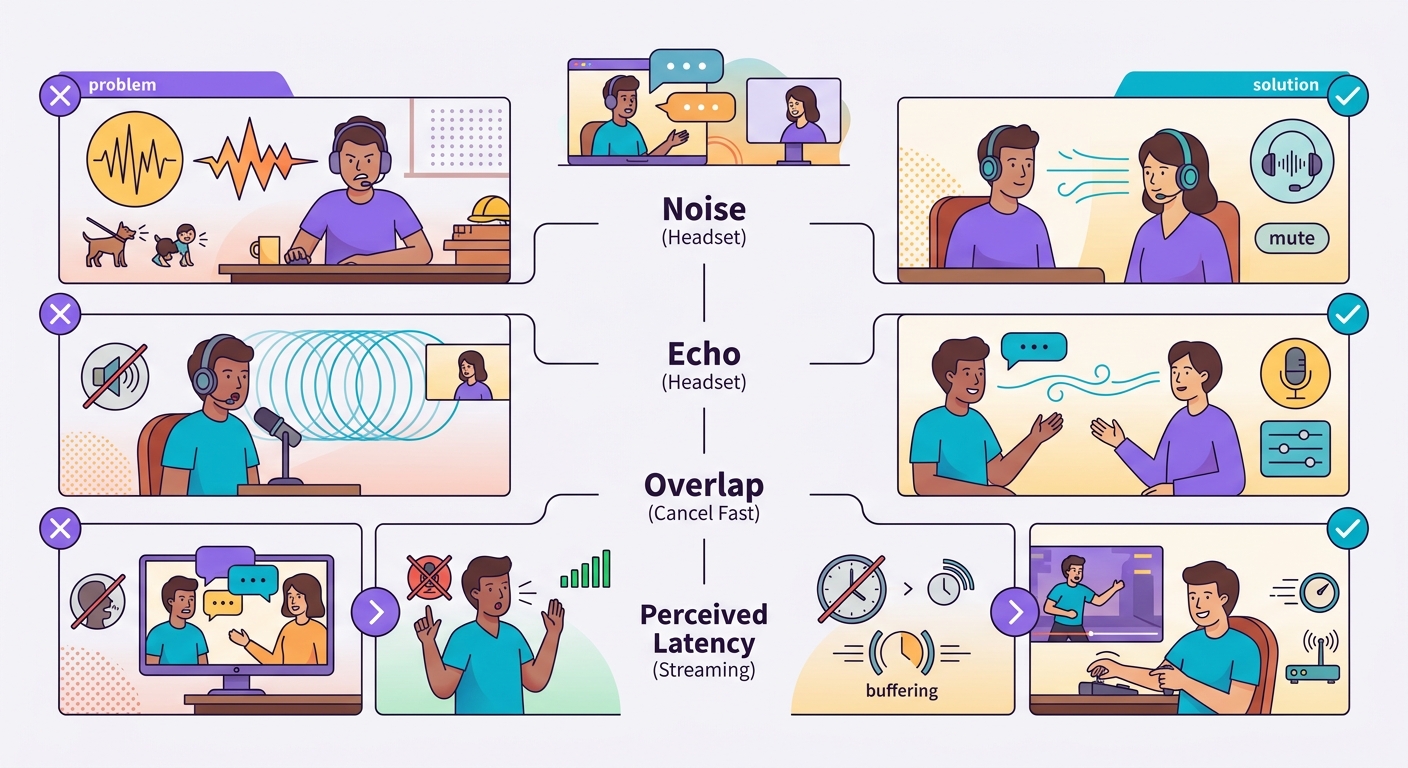
الأخطاء الشائعة
- ضوضاء الخلفية: التقاط الأصوات المحيطة يُفشل VAD؛ استخدم سماعة رأس أو ميكروفون اتجاهي
- صدى TTS: إذا كانت السماعة مدمجة في اللابتوب، قد يلتقط الميكروفون صوت TTS ويُعيد نسخه؛ استخدم سماعة رأس
- تداخل الكلام: المستخدم يقاطع والنظام يتأخر في الاستجابة = إحباط؛ طبّق إلغاء سريعًا
- التأخير المُدرَك مقابل الحقيقي: تأخير 1 ثانية يبدو مقبولًا في النص، لكنه يبدو بطيئًا في الصوت؛ حسّنه ليصل إلى أقل من 500ms كلما أمكن
التطبيق الأساسي في المتصفح
للتجربة السريعة:
`javascript
// 1. الالتقاط
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. إرسال مقاطع كل 500ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. إرسال النص إلى LLM واستقبال الرد
// 4. إرسال الرد إلى /api/tts وتشغيل النتيجة
};
mediaRecorder.start(500);`
توفر Brainiall هذا جاهزًا في الدردشة: انقر على أيقونة الميكروفون واضغط مع الاستمرار.
جرّبه الآن
في دردشة Brainiall، انقر على أيقونة الميكروفون واضغط مع الاستمرار. تحدث، ثم أفلت، واستقبل الرد نصًا وصوتًا. خطة Pro بـ $5.99 تشمل الصوت الكامل؛ وخطة Business تُتيح أصواتًا مميزة مع أولوية في التأخير.