
Clone sua voz com 10 segundos de áudio
Por que 10 segundos bastam hoje (não bastavam há 2 anos)
Até 2023, clonar uma voz exigia de 30 minutos a algumas horas de gravação limpa, em estúdio, lendo um corpus específico. Hoje, modelos modernos de clonagem de voz fazem o mesmo trabalho com 6 a 15 segundos de áudio de referência, em qualquer contexto razoavelmente silencioso.
O que mudou? Arquitetura. Os modelos modernos separam o que você diz (conteúdo) do como você diz (timbre, prosódia, ritmo). Um encoder pequeno extrai seu "perfil vocal" em poucas centenas de milissegundos; depois, qualquer texto pode ser sintetizado usando esse perfil. O modelo de síntese em si já sabe como falar português, inglês ou outro idioma — ele só está "pintando" o texto com sua voz.
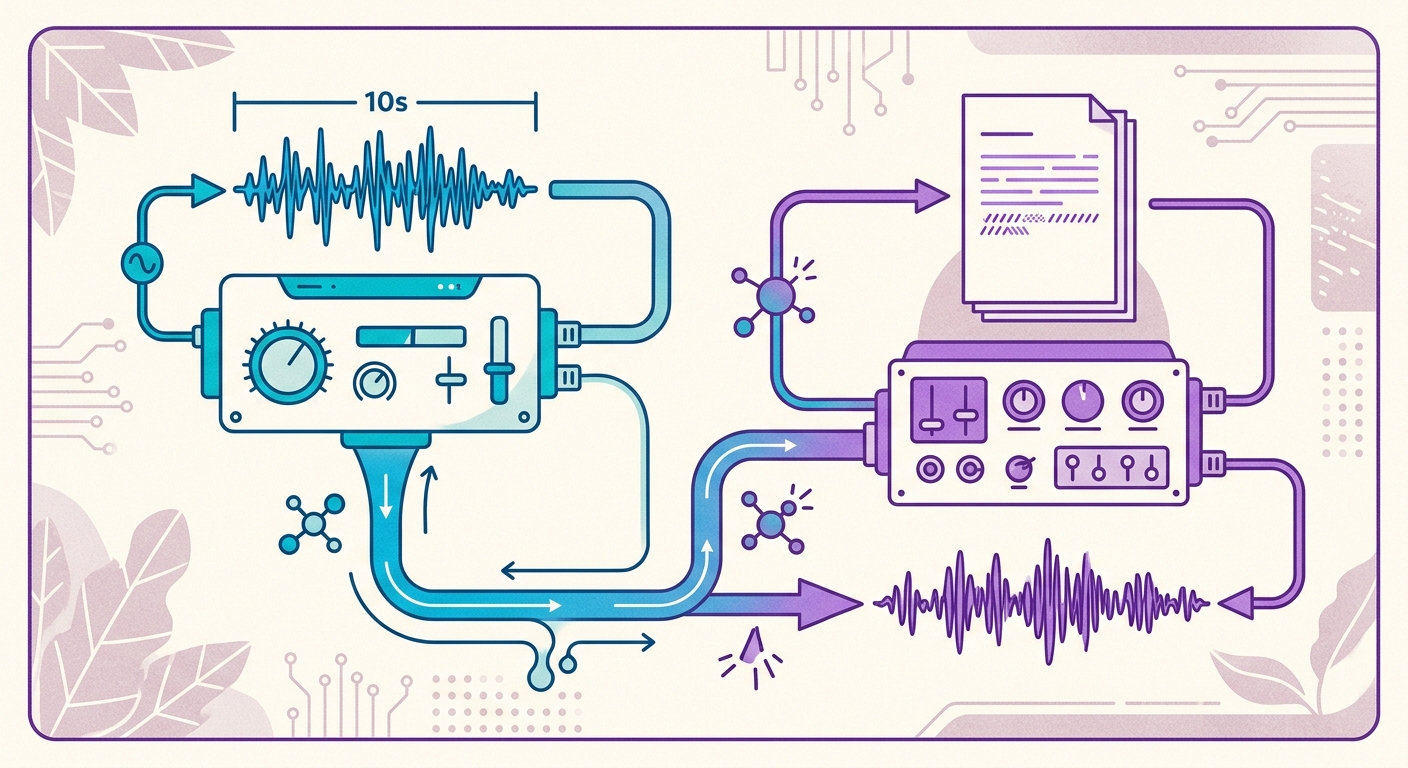
O pipeline da Brainiall na prática
Na Brainiall você tem 54 vozes prontas em 9 idiomas — incluindo 3 vozes em português brasileiro — além de poder clonar a sua própria. Para clonar uma voz nova, o fluxo é:
1. Você grava 10 segundos falando qualquer coisa em português (por exemplo, lendo este parágrafo)
2. O encoder extrai seu "voice embedding" — um vetor de 512 números
3. O synthesizer recebe o texto que você quer narrar + seu embedding
4. Você recebe um MP3 de volta em 2-4 segundos (tempo real < 1, ou seja, a síntese é mais rápida que o áudio final)
🎧 Ouça a narração completa (vídeo demo em produção)
Quando fica natural, quando ainda soa robótico
Fica excelente quando:
- Seu áudio de referência é limpo (ruído de fundo baixo, sem eco)
- Você fala em tom neutro, sem risos ou interjeições extremas
- O texto a ser narrado está no mesmo idioma da amostra
- Frases curtas a médias (até 30 palavras por frase)
Ainda falha quando:
- Você pede emoções muito específicas (raiva explosiva, choro)
- O texto tem muitos nomes estrangeiros ou jargões técnicos raros
- A amostra original tinha ruído ambiente — o modelo copia o ruído junto
- Áudios muito longos (>2 minutos) começam a "drift" prosodicamente
Os limites éticos (importante)
Clonar voz sem consentimento é problema jurídico e ético sério. Na Brainiall:
- Vozes clonadas são associadas à sua conta e só você pode usá-las
- Nunca clonamos voz de terceiros a partir de áudios públicos sem permissão explícita do dono
- Conteúdo gerado passa por moderação antes de ser entregue (detectamos tentativas de impersonação política ou de celebridades)
- Você pode deletar seu voice embedding a qualquer momento em Meus dados (LGPD)
Voice cloning tem usos legítimos poderosos: narrar livros em sua própria voz, criar conteúdo em múltiplos idiomas mantendo sua identidade, acessibilidade para pessoas que perderam a fala. Use com responsabilidade.
Teste agora mesmo
No chat Brainiall, clique no microfone no campo de input, grave 10 segundos (qualquer conteúdo), e em seguida escreva um texto para narrar. A clonagem em si é gratuita até 3 tentativas por mês. O plano Pro R$29 desbloqueia 100 imagens e 10 vídeos/mês, além das 54 vozes prontas — muitas delas já soam mais naturais que uma voz clonada de amador.