
Erzählen Sie beliebige Texte in 9 Sprachen mit 54 neuronalen Stimmen
Die Entwicklung von TTS in 5 Jahren
Bis 2020 klang Text-to-Speech roboterhaft — die Generation der ursprünglichen Siri. Von 2021 bis 2023 lernten wir, WaveNet- und Tacotron-Modelle zu verwenden, um natürliche Sprache zu erreichen. Ab 2024 brachten Modelle einer neuen Größenordnung (XTTS, Kokoro, VALL-E) drei entscheidende Fortschritte:
1. Geringe Größe: Kokoro hat nur 82 Millionen Parameter — 100× kleiner als die alten Giganten, aber gleiche Qualität
2. Echtzeit-Inferenz: RTF (Real-Time Factor) < 0,2 auf einer Einsteiger-GPU; das heißt, 1 Minute Audio wird in weniger als 12 Sekunden synthetisiert
3. Natürliche Prosodie: Intonation, Betonung, Rhythmus — nicht mehr „monoton mit Komma
Die 9 Sprachen von Brainiall
- Brasilianisches Portugiesisch: pf_dora (weiblich, erwachsen), pm_alex, pm_santa (männlich)
- Amerikanisches Englisch: af_heart, af_bella, af_nicole, am_adam, am_michael
- Britisches Englisch: bf_emma, bm_george, bm_lewis
- Spanisch: ef_lucia, em_carlos
- Französisch: ff_juliette, fm_louis
- Deutsch: gf_sophia, gm_max
- Italienisch: if_chiara, im_marco
- Mandarin-Chinesisch: zf_mei, zm_wei
- Japanisch: jf_haruka, jm_kenji
Jede Stimme hat ihre eigene Persönlichkeit: pf_dora ist klar und lehrreich (wir verwenden sie in den Kursen der Brainiall Academy), am_adam ist professionell und geschäftlich, af_heart hat einen emotionaleren Ton.
Wie man die richtige Stimme für den Kontext auswählt
- E-Learning / Tutorials: neutrale und artikulierte Stimmen (pf_dora, am_adam)
- Marketing / Werbung: dynamischere und ausdrucksstärkere Stimmen (af_heart, am_michael)
- Hörbücher: warme und erzählerische Stimmen (af_bella, bm_george)
- Nachrichten: formelle und klare Stimmen (pm_santa, am_adam)
- Chatbots / Assistenten: freundliche und schnelle Stimmen (af_nicole, pm_alex)
Praktischer Tipp: Generieren Sie 3–5 Sekunden Testaufnahmen mit 3 Kandidatenstimmen, bevor Sie einen langen Text synthetisieren. Die Präferenz ist immer subjektiv.
Geschwindigkeit und Tonhöhe steuern
Die nützlichsten Parameter:
- speed: 0,25 bis 4,0 — Standard 1,0. Verwende 0,85 für Hörbücher (ruhige Erzählung), 1,15 für Bildungsinhalte, 1,3+ nur für schnelle Vorschauen
- format: mp3, wav, ogg. MP3 ist Standard (beste Komprimierung); WAV für den Fall, dass du das Audio danach bearbeiten möchtest; OGG für Web-Streaming
- pitch: einige Modelle akzeptieren dies, Anpassung in Halbtönen (-5 bis +5)
Gehe nicht in Extreme: speed > 2,0 wird unverständlich, < 0,5 klingt künstlich.
Technische und Nutzungsgrenzen
- Maximum pro Request: 4000 Zeichen — ungefähr 4 Absätze. Lange Texte erfordern Chunking
- Gemischte Sprachen: Jede Stimme spricht ihre Hauptsprache gut; Mischen (z. B. PT-Text mit englischen Wörtern) kann zu zögernder Aussprache führen
- Fremdsprachige Eigennamen: Schreiben Sie diese im Prompt phonetisch — „Maicrosoft" statt „Microsoft"
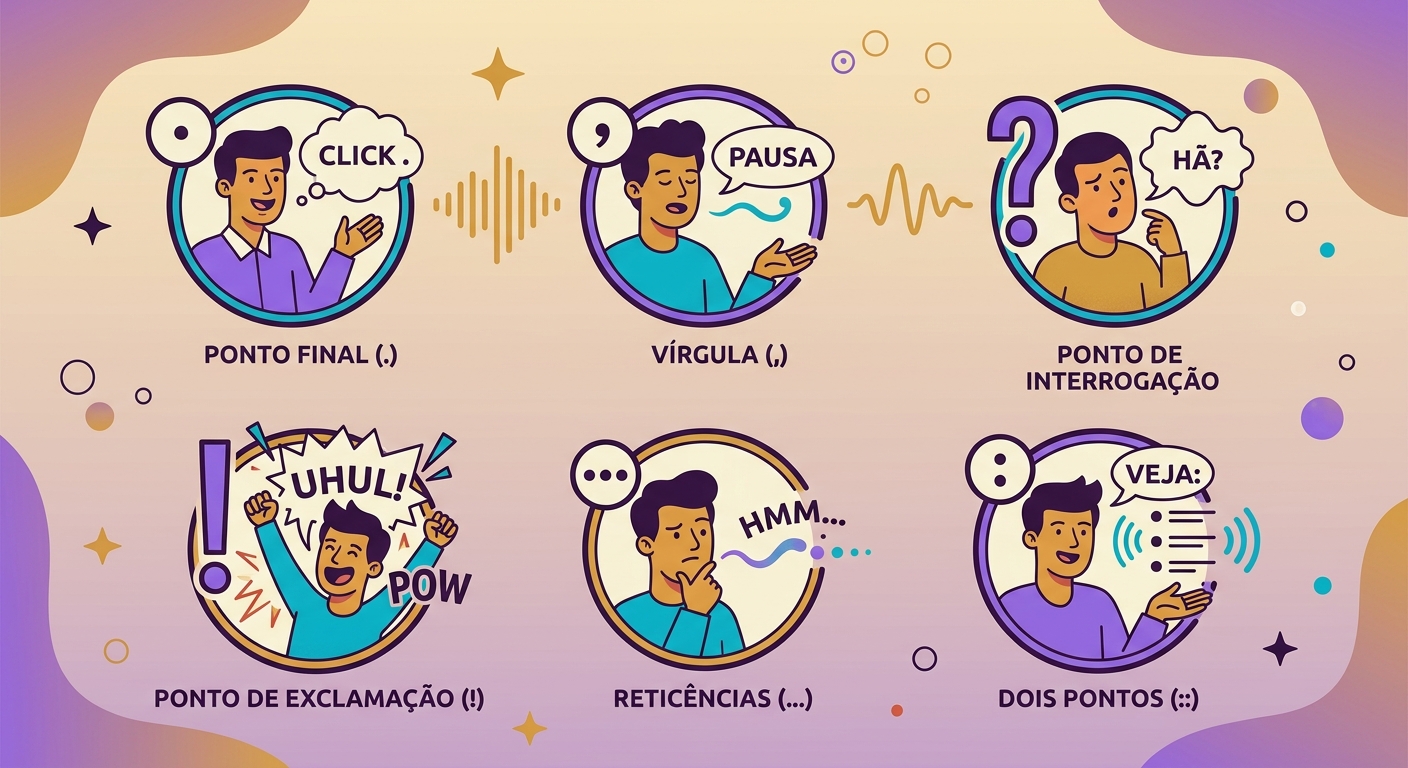
- Interpunktion ist wichtig: Kommas = kurze Pause, Auslassungspunkte = lange Pause, Punkt = Tonabfall
- Emojis: Die meisten Modelle ignorieren sie oder lesen sie als Wort („lächelnd") — entfernen Sie sie vorher
Praktische Anwendungsfälle
- Kursvertonung: wie wir es in der Academy machen — schnell, günstig, konsistent
- Heimische Hörbücher: konvertieren Sie PDFs/EPUBs in MP3, um sie im Auto zu hören
- Barrierefreiheit: konvertieren Sie Ihren Blog in Audio für Leser mit Leseschwierigkeiten
- Automatische Podcasts: konvertieren Sie Newsletter in das Podcast-Format zur Verbreitung
- Stimme für Videos: ersetzen Sie teures Voice-over durch TTS, wenn das Timing nicht kritisch ist
Teste jetzt gleich
Im Brainiall-Chat senden Sie eine Nachricht und klicken Sie auf das Symbol 🔊 in der Antwort, um es mit TTS anzuhören. Oder über die Route /api/tts via API. Der Pro-Plan €5,49 ermöglicht eine großzügige Nutzung von TTS; Business €18 beinhaltet API-Guthaben für externe Integrationen.