
Sprechen Sie per Sprache (STT → LLM → TTS Pipeline)
Die Anatomie eines Sprachgesprächs
Sprachkonversation mit KI ist eine Kette aus 3 APIs:
`
[Sie sprechen] → Mikrofon → STT (Whisper) → Text
↓
LLM (Claude/GPT)
↓
[Sie hören] ← Lautsprecher ← TTS (pf_dora) ← Text`
Jede Stufe hat Latenz. Damit das Erlebnis natürlich wirkt (menschliches Gespräch), muss die Gesamtzeit unter 1,5 Sekunden bleiben. Im Jahr 2026 ist das erreichbar, erfordert jedoch sorgfältige Entwicklungsarbeit.
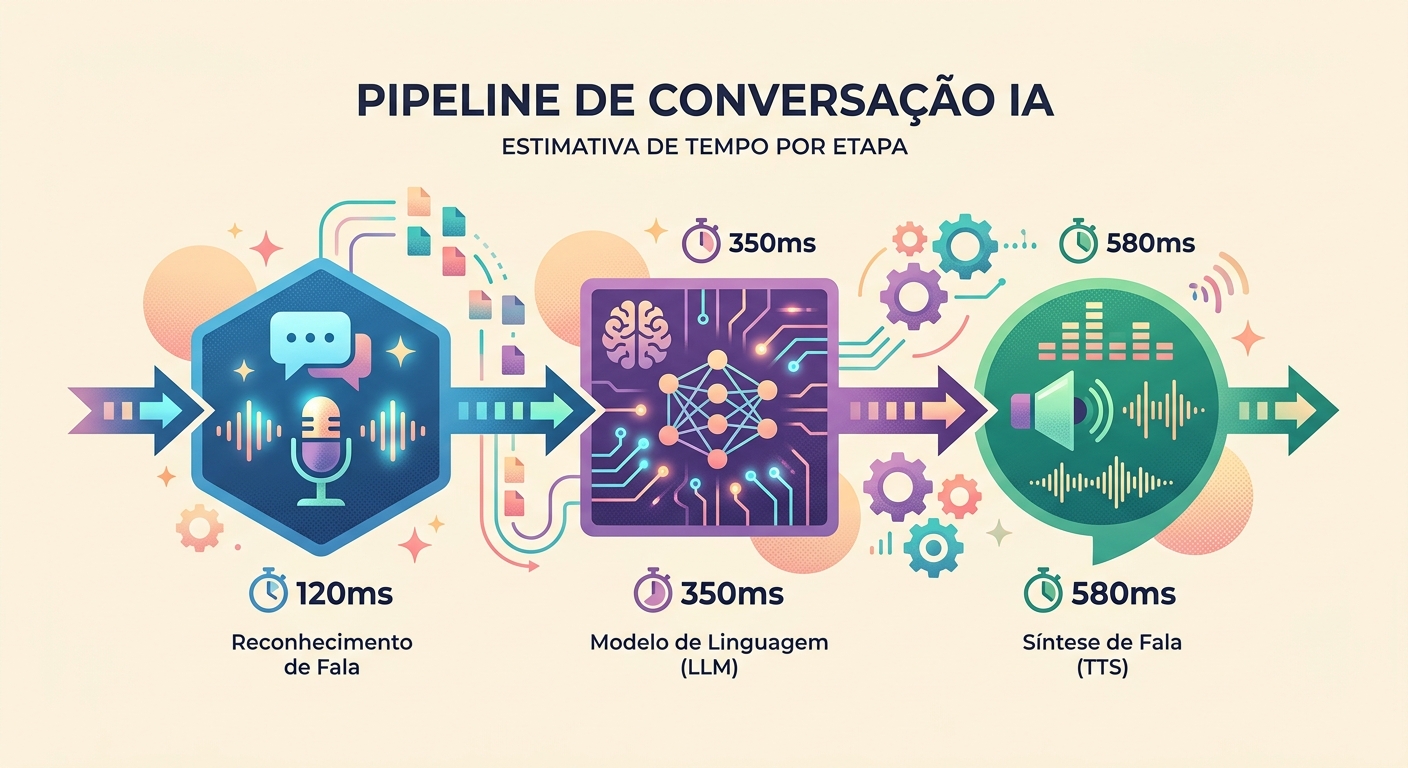
Realistische Latenz im Jahr 2026
Messung in einem echten Gespräch in Brainiall:
- Audioaufnahme (Mikrofon → WAV): ~100ms (abhängig von der Hardware)
- STT (Whisper Large v3): 300-600ms für einen Satz von 3-5s
- LLM (Claude Haiku für Geschwindigkeit): 400-900ms erstes Token
- TTS (pf_dora via unified-API): 300-500ms für 3-5s Audio
- Wiedergabe (Lautsprecher-Latenz): ~50ms
Gesamt first-token-to-speech: 1150-2150ms. Akzeptabel, wenn das Modell früh beginnt zu „sprechen" (Streaming).
Streaming ist alles
Ohne Streaming wartet jeder Schritt auf den Abschluss des vorherigen: 600ms + 900ms + 500ms = mindestens 2000ms.
Mit Streaming:
- STT kann mit der Transkription beginnen, während Sie noch sprechen (VAD — Voice Activity Detection)
- LLM beginnt mit der Token-Generierung, bevor STT abgeschlossen ist (mit einer gewissen Vorhersage der Absicht)
- TTS beginnt die ersten Wörter zu sprechen, während LLM noch die letzten generiert
Die effektive Latenz sinkt auf 400-700ms. Es wirkt natürlich.
VAD: wenn aufgehört wird zu hören
Das subtilste Problem: erkennen, wann Sie aufgehört haben zu sprechen. Stoppt man zu früh, wird der Satz abgeschnitten. Stoppt man zu spät, entsteht eine Latenz von 500ms.
Techniken:
- Absolute Stille für 600ms: einfach, aber kommt nicht mit natürlichen Denkpausen zurecht
- Silero VAD: neuronales Modell, das das Satzende mit ~95% Genauigkeit in <50ms erkennt
- Confidence from STT: Whisper gibt einen Konfidenzwert zurück; sinkt dieser, ist die Aussage wahrscheinlich beendet
- Interruption detection: Benutzer spricht erneut → bricht laufende TTS ab, startet den Zyklus neu
Brainiall verwendet Silero VAD + dynamischen Stille-Schwellenwert (passt sich an die Umgebung an).
Auswahl des Modells für Latenz vs. Qualität
Im Voice-Modus lohnt es sich in der Regel, etwas LLM-Qualität zugunsten von Geschwindigkeit zu opfern:
- Claude Haiku 4.5: ~400ms erstes Token, direkte Antworten, R$ 2/1M Tokens
- GPT-5 mini: ~350ms, kreativer als Haiku, R$ 3/1M Tokens
- Gemini 3 Flash: ~250ms, ausgezeichnet für kurze Antworten, R$ 2/1M Tokens
Für Gespräche, bei denen Qualität > Latenz gilt (z. B. detaillierter Sprachtutor), wechseln Sie zu Claude Sonnet 4.6 oder dem vollständigen GPT-5.
Anwendungsfälle, die der Voice-Modus gut löst
- Konversationstraining in Sprachen: Üben Sie Englisch mit einer KI zu sprechen, die natürlich antwortet
- Hands-free-Assistent: beim Fahren, Kochen, Sport treiben
- Barrierefreiheit: Personen mit Schwierigkeiten beim Tippen
- Brainstorming beim Spazierengehen: Ideen sprechen statt schreiben
- Nachhilfe: Frage + schnelle Antwort, natürlicherer didaktischer Fluss
- Unternehmen — Telefonservice: dumme Sprachdialogsysteme durch natürliche Konversation ersetzen
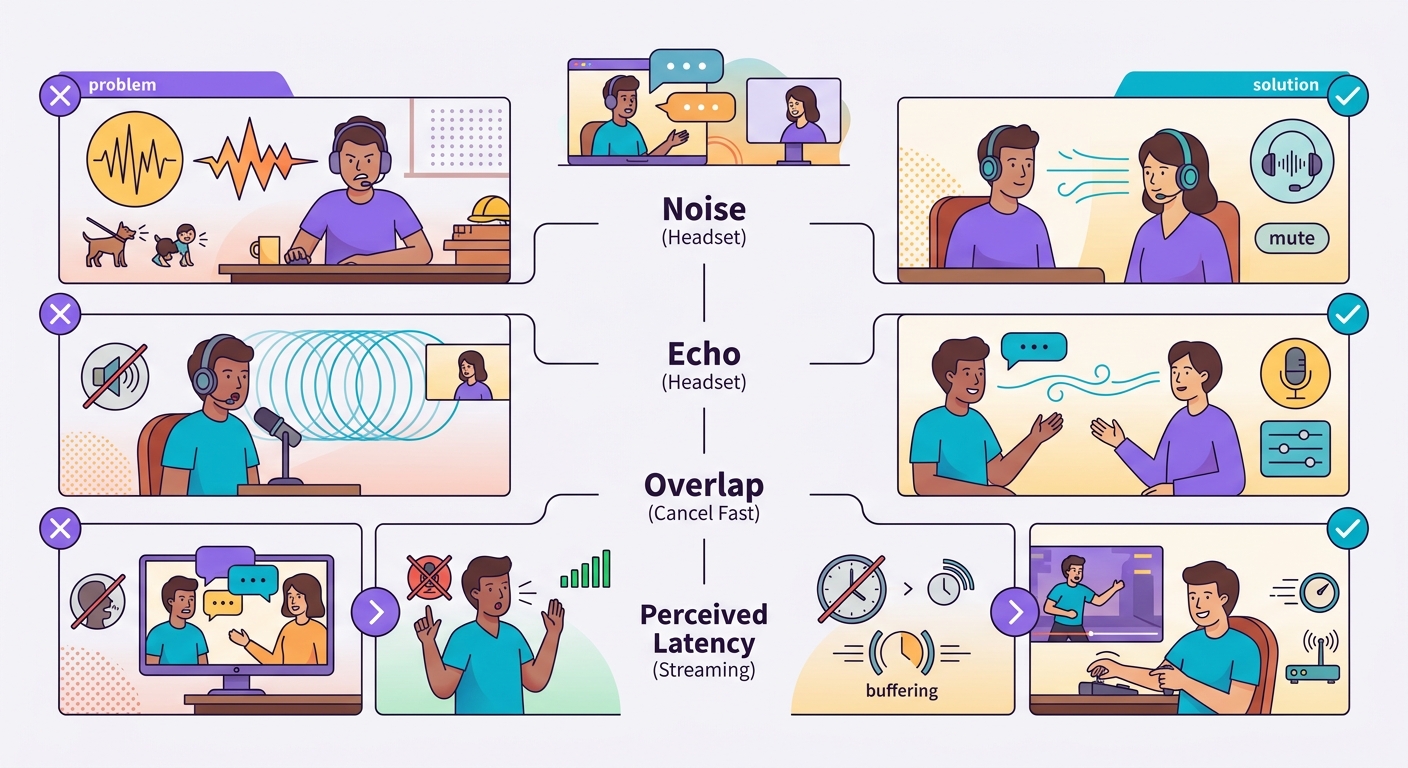
Häufige Fallstricke
- Hintergrundgeräusche: Umgebungsaufnahme lässt VAD versagen; verwenden Sie ein Headset oder ein Richtmikrofon
- Echo des eigenen TTS: Wenn der Lautsprecher der Laptop-Lautsprecher ist, kann das Mikrofon den TTS aufnehmen und zurücktranskribieren; verwenden Sie ein Headset
- Überlappende Sprache: Benutzer unterbricht, System reagiert langsam = Frustration; schnelle Abbruchfunktion implementieren
- Wahrgenommene vs. tatsächliche Latenz: Eine Latenz von 1s wirkt bei Text akzeptabel, bei Sprache jedoch langsam; optimieren Sie auf <500ms wenn möglich
Grundlegende Implementierung im Browser
Für schnelles Experimentieren:
`javascript
// 1. Aufnahme
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Sendet Chunks alle 500ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. Sendet an LLM, empfängt Antwort
// 4. Sendet Antwort an /api/tts, spielt Ergebnis ab
};
mediaRecorder.start(500);`
Brainiall bietet dies bereits fertig im Chat an: Klicken Sie auf das Mikrofon und halten Sie es gedrückt.
Teste jetzt gleich
Im Brainiall-Chat klicken Sie auf das Mikrofon-Symbol und halten Sie es gedrückt. Sprechen Sie, lassen Sie los, erhalten Sie eine Antwort in Text + Audio. Pro für €5,49 beinhaltet vollständige Sprachfunktion; Business schaltet Premium-Stimmen + Priority-Latenz frei.