
Conversa por voz (STT → LLM → TTS pipeline)
La anatomía de una conversación por voz
Conversar por voz con IA es una cadena de 3 APIs:
`
[Hablas] → Micrófono → STT (Whisper) → texto
↓
LLM (Claude/GPT)
↓
[Escuchas] ← Altavoz ← TTS (pf_dora) ← texto`
Cada etapa tiene latencia. Para que la experiencia parezca natural (como una conversación humana), el total debe mantenerse por debajo de 1.5 segundos. En 2026, esto es alcanzable, pero requiere una ingeniería cuidadosa.
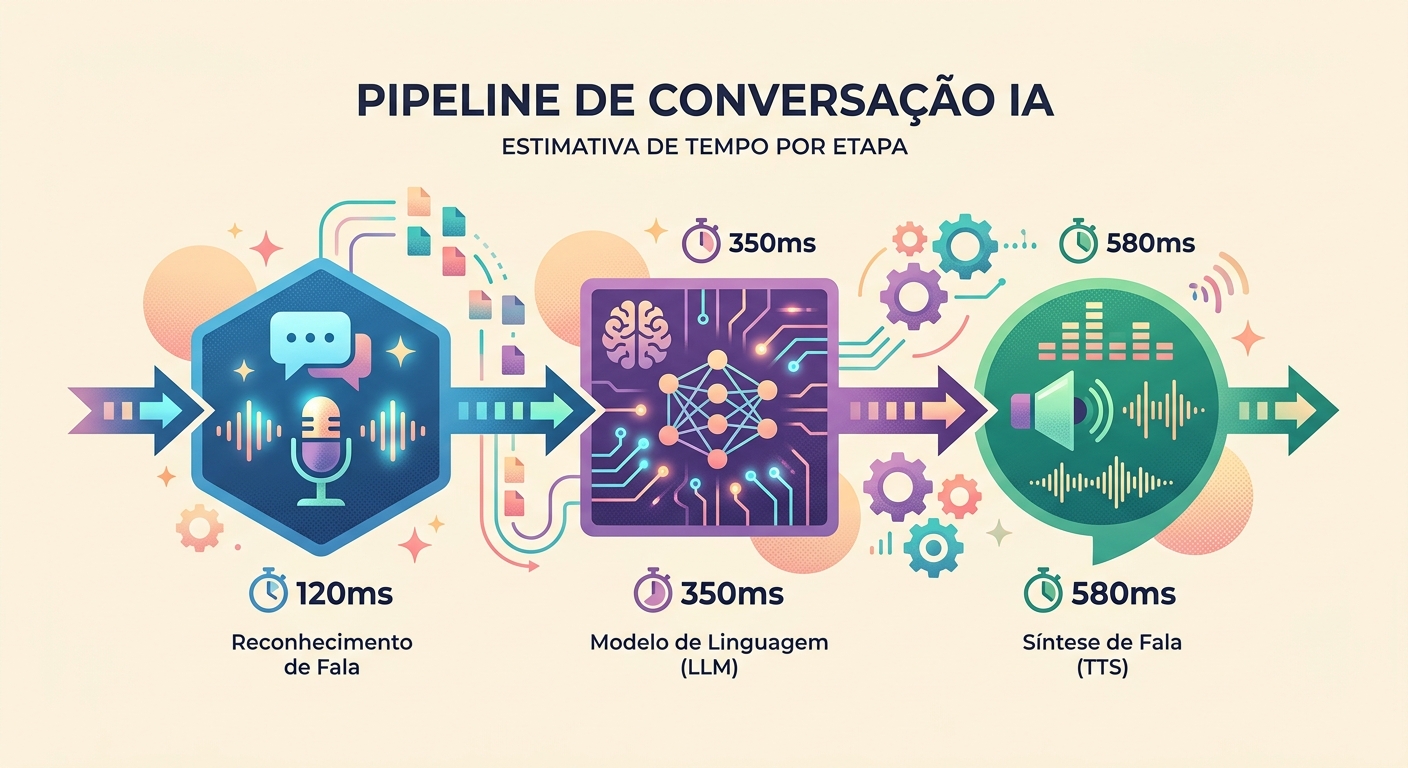
Latencia realista en 2026
Medición en una conversación real en Brainiall:
- Captura de audio (mic → WAV): ~100ms (depende del hardware)
- STT (Whisper Large v3): 300-600ms para una frase de 3-5s
- LLM (Claude Haiku para velocidad): 400-900ms primer token
- TTS (pf_dora vía unified-api): 300-500ms para 3-5s de audio
- Playback (latencia del altavoz): ~50ms
Total first-token-to-speech: 1150-2150ms. Aceptable si el modelo empieza a "hablar" pronto (streaming).
El streaming lo es todo
Sin streaming, cada etapa espera a que termine la anterior: 600ms + 900ms + 500ms = 2000ms como mínimo.
Con streaming:
- STT puede comenzar a transcribir mientras aún estás hablando (VAD — Voice Activity Detection)
- LLM empieza a generar tokens antes de que STT termine (con cierta predicción de la intención)
- TTS comienza a narrar las primeras palabras mientras LLM aún genera las últimas
La latencia efectiva cae a 400-700ms. Suena natural.
VAD: cuándo dejar de escuchar
El problema más sutil: detectar que dejaste de hablar. Si se detiene demasiado pronto, corta tu frase. Si se detiene tarde, añade 500ms de latencia.
Técnicas:
- Silencio absoluto por 600ms: simple, pero no maneja las pausas naturales de pensamiento
- Silero VAD: modelo neuronal que detecta el fin de frase con ~95% de precisión en <50ms
- Confidence from STT: Whisper devuelve confidence; si cae, probablemente terminaste
- Interruption detection: el usuario vuelve a hablar → cancela el TTS en curso, reinicia el ciclo
Brainiall usa Silero VAD + umbral dinámico de silencio (se ajusta según el entorno).
Elección del modelo: latencia vs. calidad
En modo de voz, generalmente vale la pena sacrificar un poco de calidad del LLM para ganar velocidad:
- Claude Haiku 4.5: ~400ms primer token, respuestas directas, R$ 2/1M tokens
- GPT-5 mini: ~350ms, más creativo que Haiku, R$ 3/1M tokens
- Gemini 3 Flash: ~250ms, excelente para respuestas cortas, R$ 2/1M tokens
Para conversaciones donde calidad > latencia (ej: tutor de idiomas detallado), sube a Claude Sonnet 4.6 o GPT-5 completo.
Casos de uso que el modo de voz resuelve muy bien
- Entrenamiento de conversación en idiomas: practica hablar inglés con una IA que responde de forma natural
- Asistente manos libres: mientras conduces, cocinas o haces ejercicio
- Accesibilidad: personas con dificultad para escribir
- Brainstorming en caminatas: registra ideas hablando en lugar de escribir
- Tutoría: pregunta + respuesta rápida, un flujo didáctico más natural
- Empresas — atención telefónica: reemplaza la IVR tradicional por una conversación natural
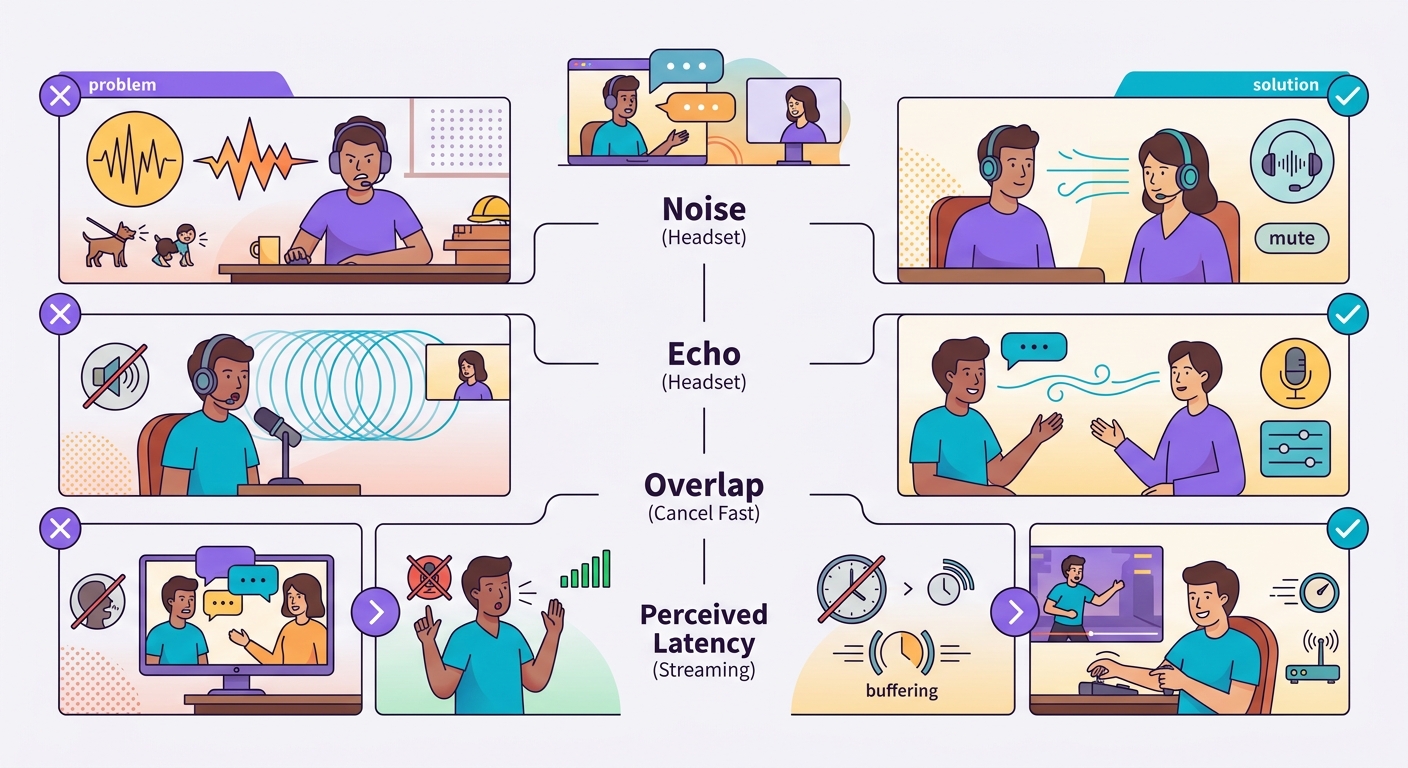
Errores comunes
- Ruido de fondo: el ambiente capturado hace fallar el VAD; usa auriculares o un micrófono direccional
- Eco del propio TTS: si el altavoz es el del laptop, el micrófono puede captar el TTS y transcribirlo de vuelta; usa auriculares
- Superposición de voz: el usuario interrumpe y el sistema tarda en reaccionar = frustración; implementa cancelación rápida
- Latencia percibida vs. real: 1s de latencia parece bien en texto, pero lento en voz; optimiza para <500ms cuando sea posible
Implementación básica en el navegador
Para experimentación rápida:
`javascript
// 1. Captura
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Envía chunks cada 500ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. Envía al LLM, recibe respuesta
// 4. Envía respuesta a /api/tts, reproduce el resultado
};
mediaRecorder.start(500);`
Brainiall ya ofrece esto listo en el chat: haz clic en el micrófono y mantén presionado.
Pruébalo ahora mismo
En el chat de Brainiall, haz clic en el ícono del micrófono y mantenlo presionado. Habla, suéltalo y recibe la respuesta en texto + audio. El plan Pro US$5.99 incluye voz completa; el plan Business desbloquea voces premium + latencia prioritaria.