
Conversez par la voix (pipeline STT → LLM → TTS)
L'anatomie d'une conversation vocale
Converser avec une IA par la voix, c'est enchaîner 3 API :
`
[Vous parlez] → Microphone → STT (Whisper) → texte
↓
LLM (Claude/GPT)
↓
[Vous écoutez] ← Haut-parleur ← TTS (pf_dora) ← texte`
Chaque étape introduit de la latence. Pour que l'expérience paraisse naturelle (comme une conversation humaine), le total doit rester en dessous de 1,5 seconde. En 2026, c'est atteignable, mais cela demande une ingénierie soignée.
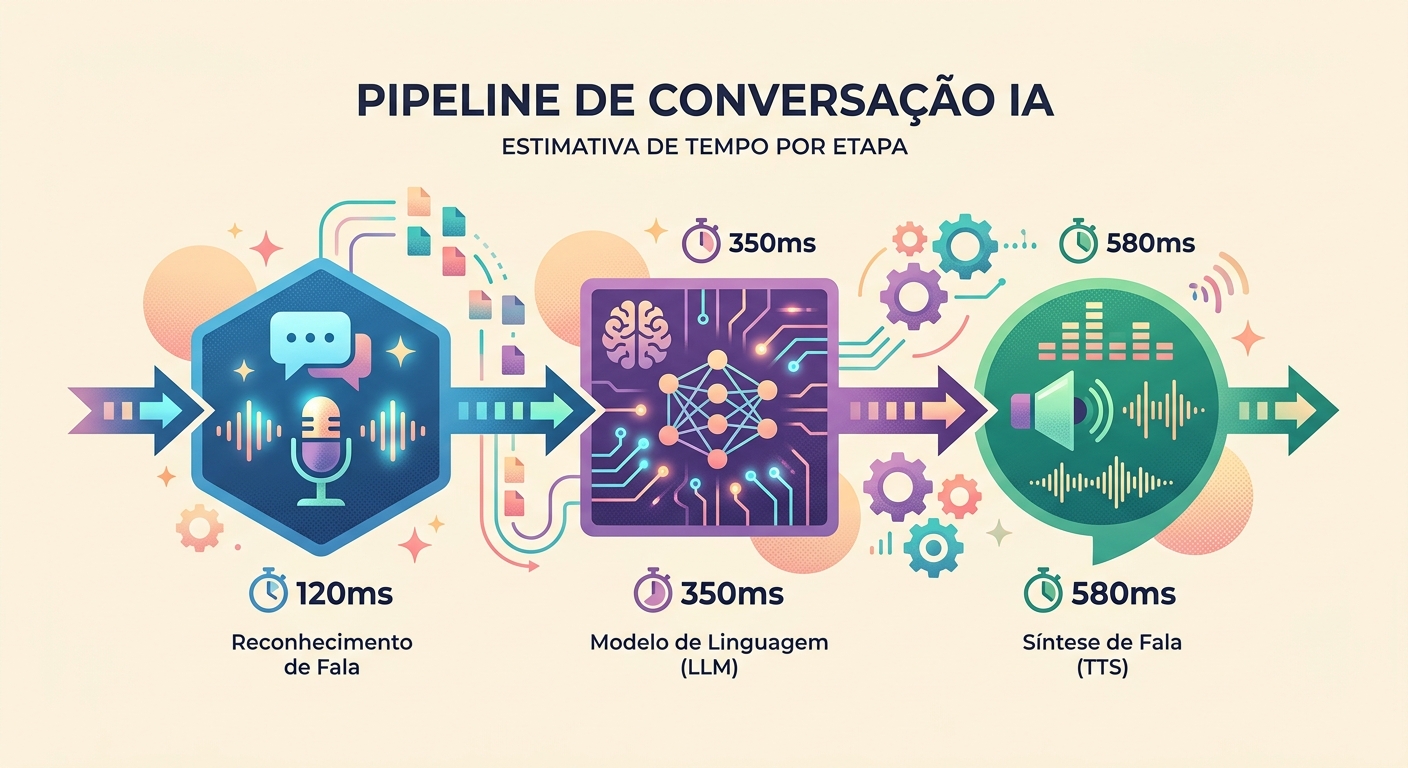
Latence réaliste en 2026
Mesures relevées lors de vraies conversations sur Brainiall :
- Capture audio (micro → WAV) : ~100 ms (selon le matériel)
- STT (Whisper Large v3) : 300-600 ms pour une phrase de 3-5 s
- LLM (Claude Haiku pour la vitesse) : 400-900 ms au premier token
- TTS (pf_dora via unified-api) : 300-500 ms pour 3-5 s d'audio
- Lecture (latence haut-parleur) : ~50 ms
Total first-token-to-speech : 1150-2150 ms. Acceptable si le modèle commence à « parler » tôt (streaming).
Le streaming, c'est tout
Sans streaming, chaque étape attend que la précédente se termine : 600 ms + 900 ms + 500 ms = 2000 ms minimum.
Avec le streaming :
- Le STT peut commencer à transcrire pendant que vous parlez encore (VAD — Voice Activity Detection)
- Le LLM commence à générer des tokens avant que le STT ait terminé (avec une anticipation de l'intention)
- Le TTS commence à narrer les premiers mots pendant que le LLM génère encore les derniers
La latence effective tombe à 400-700 ms. Le résultat semble naturel.
VAD : quand arrêter d'écouter
Le défi le plus subtil : détecter que vous avez arrêté de parler. Si l'on coupe trop tôt, votre phrase est tronquée. Si l'on coupe trop tard, on ajoute 500 ms de latence.
Techniques :
- Silence absolu pendant 600 ms : simple, mais ne gère pas les pauses naturelles de réflexion
- Silero VAD : modèle neuronal qui détecte la fin d'une phrase avec ~95 % de précision en moins de 50 ms
- Confidence du STT : Whisper retourne un score de confiance ; s'il chute, la phrase est probablement terminée
- Détection d'interruption : l'utilisateur reprend la parole → annule le TTS en cours, relance le cycle
Brainiall utilise Silero VAD combiné à un seuil de silence dynamique (ajusté selon l'environnement).
Choisir le bon modèle : latence vs qualité
En mode vocal, il vaut généralement la peine de sacrifier un peu de qualité LLM pour gagner en vitesse :
- Claude Haiku 4.5 : ~400 ms au premier token, réponses directes, R$ 2/1M tokens
- GPT-5 mini : ~350 ms, plus créatif que Haiku, R$ 3/1M tokens
- Gemini 3 Flash : ~250 ms, excellent pour les réponses courtes, R$ 2/1M tokens
Pour les conversations où la qualité prime sur la latence (ex. : tuteur de langues détaillé), passez à Claude Sonnet 4.6 ou GPT-5 complet.
Cas d'usage où le mode vocal excelle
- Entraînement à la conversation en langues étrangères : pratiquez l'anglais oral avec une IA qui répond naturellement
- Assistant mains libres : en conduisant, en cuisinant, en faisant du sport
- Accessibilité : pour les personnes ayant des difficultés à taper
- Brainstorming en marchant : capturez vos idées à la voix plutôt qu'à l'écrit
- Tutorat : questions et réponses rapides, un flux pédagogique plus naturel
- Entreprise — accueil téléphonique : remplacer un SVI rigide par une conversation naturelle
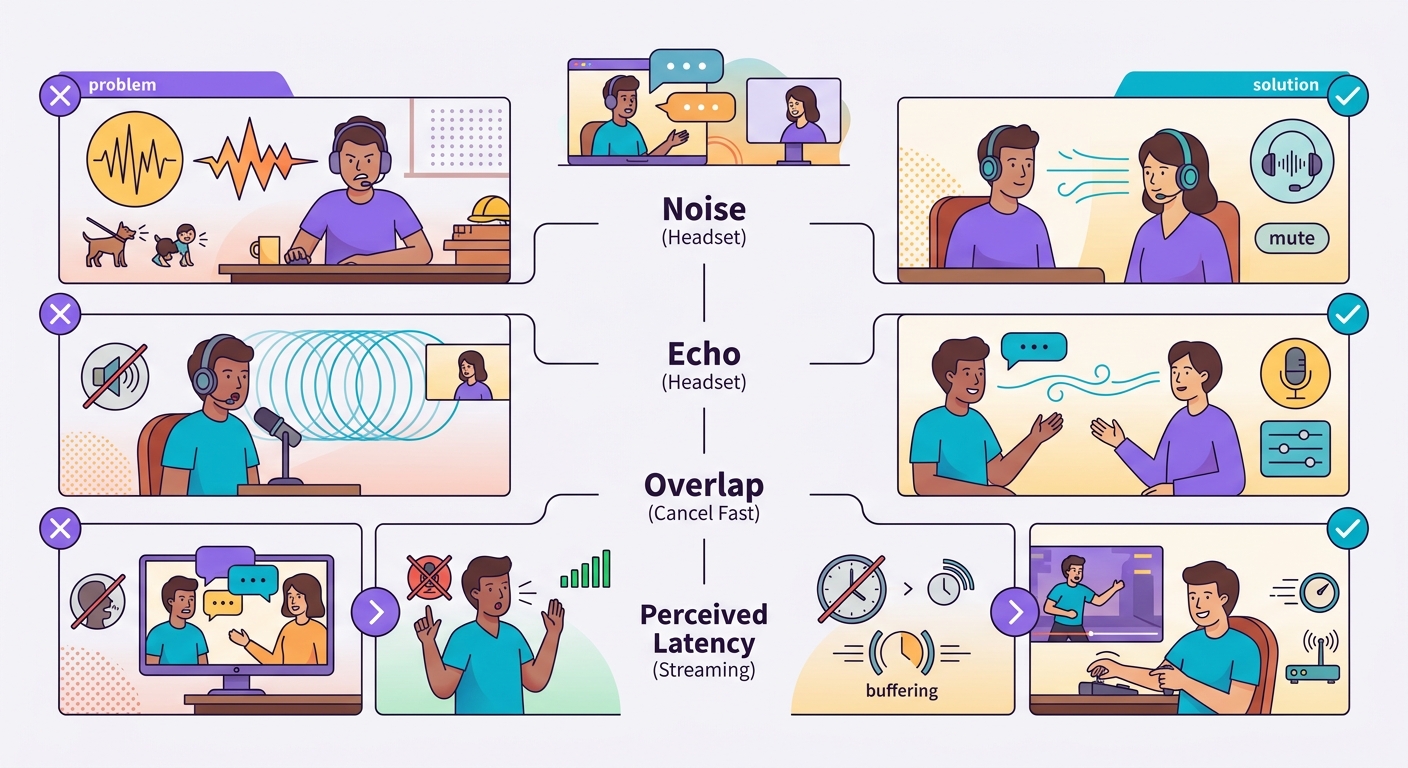
Les pièges courants
- Bruit de fond : un environnement bruyant fait échouer le VAD ; utilisez un casque ou un micro directionnel
- Écho du TTS : si le haut-parleur est celui de l'ordinateur, le micro peut capter le TTS et le retranscrire en boucle ; utilisez un casque
- Chevauchement de parole : l'utilisateur interrompt, le système tarde à réagir = frustration ; implémentez une annulation rapide
- Latence perçue vs réelle : 1 s de latence passe bien en texte, mais semble lente à l'oral ; optimisez pour moins de 500 ms quand c'est possible
Implémentation de base dans le navigateur
Pour une expérimentation rapide :
`javascript
// 1. Capture
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Envoie des chunks toutes les 500 ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. Envoie au LLM, reçoit la réponse
// 4. Envoie la réponse à /api/tts, joue le résultat
};
mediaRecorder.start(500);`
Brainiall propose déjà cette fonctionnalité directement dans le chat : cliquez sur le microphone et maintenez appuyé.
Testez dès maintenant
Dans le chat Brainiall, cliquez sur l'icône de microphone et maintenez appuyé. Parlez, relâchez, et recevez une réponse en texte et en audio. Le plan Pro à €5,49 inclut la voix complète ; le plan Business débloque les voix premium et la latence prioritaire.