
Bicara dengan suara (STT → LLM → TTS pipeline)
Anatomi sebuah percakapan suara
Percakapan suara dengan AI adalah rantai 3 API:
`
[Anda bicara] → Mikrofon → STT (Whisper) → teks
↓
LLM (Claude/GPT)
↓
[Anda dengar] ← Speaker ← TTS (pf_dora) ← teks`
Setiap tahap memiliki latensi. Agar pengalaman terasa natural (seperti percakapan manusia), totalnya harus di bawah 1,5 detik. Di tahun 2026, ini bisa dicapai namun membutuhkan rekayasa yang cermat.
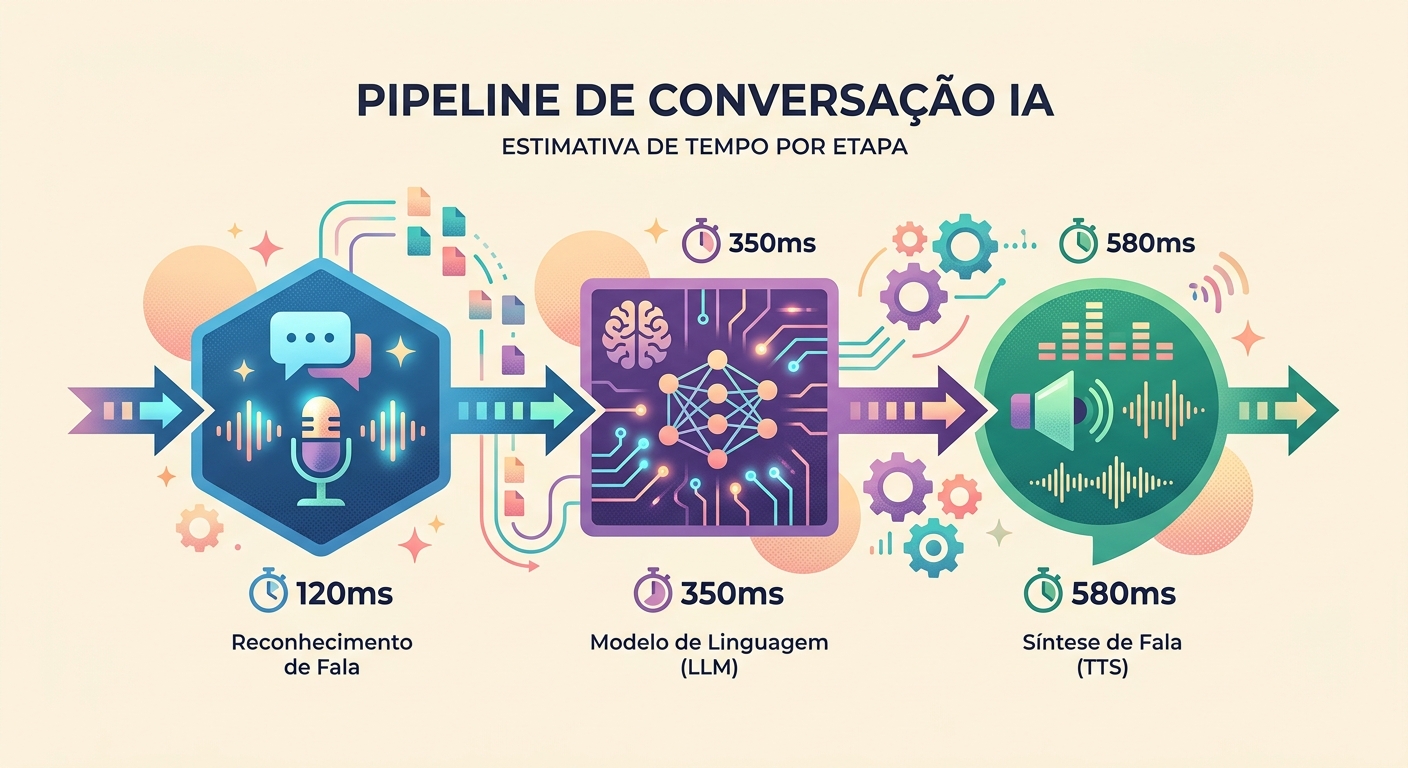
Latensi realistis di tahun 2026
Pengukuran dalam percakapan nyata di Brainiall:
- Perekaman audio (mic → WAV): ~100ms (tergantung perangkat keras)
- STT (Whisper Large v3): 300-600ms untuk kalimat 3-5 detik
- LLM (Claude Haiku untuk kecepatan): 400-900ms token pertama
- TTS (pf_dora via unified-api): 300-500ms untuk audio 3-5 detik
- Playback (latensi speaker): ~50ms
Total first-token-to-speech: 1150-2150ms. Dapat diterima jika model mulai "berbicara" lebih awal (streaming).
Streaming adalah segalanya
Tanpa streaming, setiap tahap menunggu tahap sebelumnya selesai: 600ms + 900ms + 500ms = minimal 2000ms.
Dengan streaming:
- STT dapat mulai mentranskrip sementara Anda masih berbicara (VAD — Voice Activity Detection)
- LLM mulai menghasilkan token sebelum STT selesai (dengan sedikit prediksi niat)
- TTS mulai melafalkan kata-kata pertama sementara LLM masih menghasilkan kata-kata terakhir
Latensi efektif turun menjadi 400-700ms. Terasa natural.
VAD: kapan berhenti mendengarkan
Masalah paling halus: mendeteksi bahwa Anda telah berhenti berbicara. Jika berhenti terlalu cepat, kalimat Anda terpotong. Jika terlalu lambat, menambah 500ms latensi.
Teknik-tekniknya:
- Keheningan absolut selama 600ms: sederhana namun tidak menangani jeda berpikir yang natural
- Silero VAD: model neural yang mendeteksi akhir kalimat dengan ~95% akurasi dalam <50ms
- Confidence from STT: Whisper mengembalikan confidence; jika turun, kemungkinan sudah selesai
- Interruption detection: pengguna mulai bicara lagi → membatalkan TTS yang sedang berjalan, memulai ulang siklus
Brainiall menggunakan Silero VAD + threshold keheningan dinamis (menyesuaikan berdasarkan lingkungan).
Pilihan model untuk latensi vs kualitas
Dalam voice mode, biasanya sepadan untuk sedikit mengorbankan kualitas LLM demi kecepatan:
- Claude Haiku 4.5: ~400ms token pertama, respons langsung, R$ 2/1M token
- GPT-5 mini: ~350ms, lebih kreatif dari Haiku, R$ 3/1M token
- Gemini 3 Flash: ~250ms, sangat baik untuk respons singkat, R$ 2/1M token
Untuk percakapan di mana kualitas > latensi (mis: tutor bahasa yang mendetail), gunakan Claude Sonnet 4.6 atau GPT-5 lengkap.
Kasus penggunaan yang cocok untuk voice mode
- Latihan percakapan bahasa: berlatih berbicara bahasa Inggris dengan AI yang merespons secara natural
- Asisten hands-free: saat mengemudi, memasak, berolahraga
- Aksesibilitas: bagi orang yang kesulitan mengetik
- Brainstorming saat berjalan: merekam ide dengan berbicara alih-alih menulis
- Tutoring: tanya jawab cepat, alur belajar yang lebih natural
- Bisnis — layanan telepon: menggantikan IVR yang kaku dengan percakapan yang natural
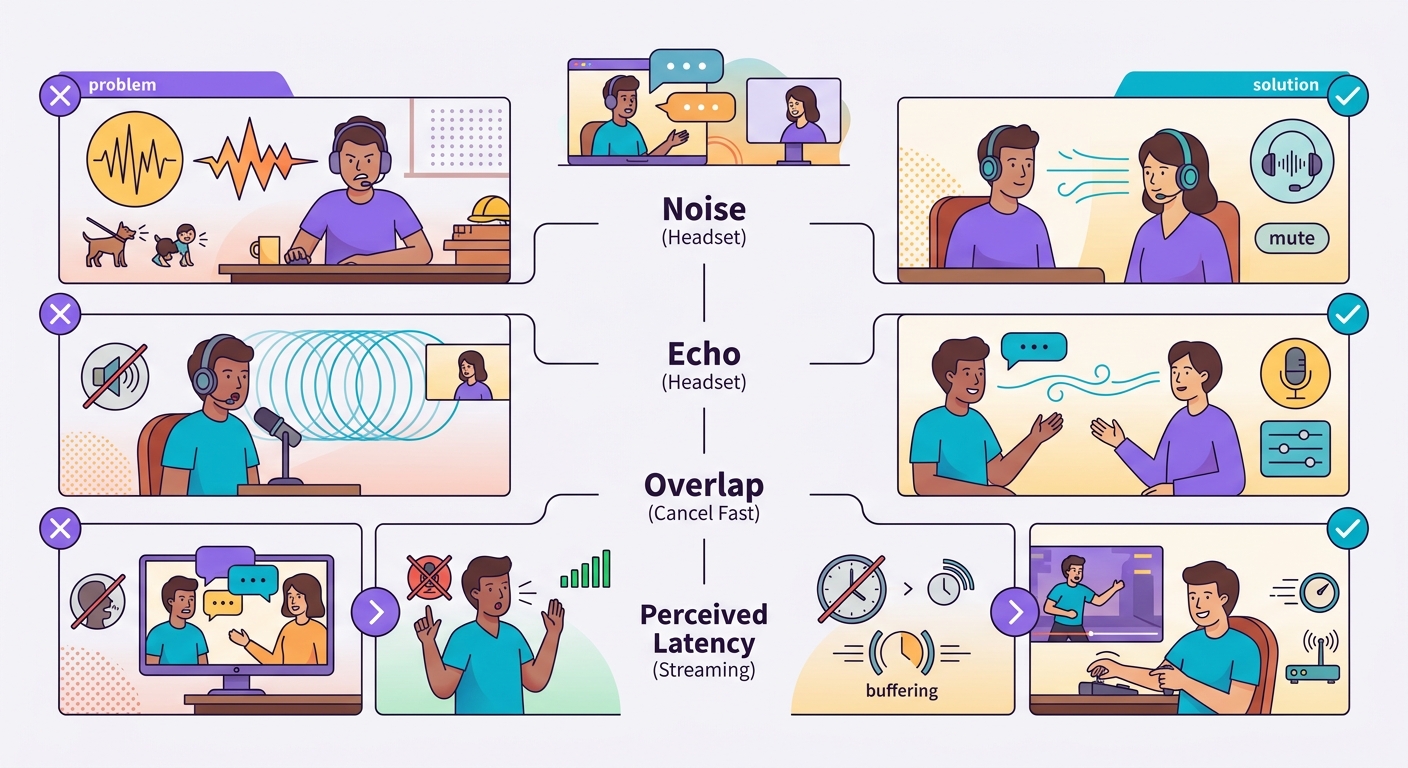
Jebakan umum yang perlu diwaspadai
- Kebisingan latar belakang: suara lingkungan membuat VAD gagal; gunakan headset atau mikrofon terarah
- Gema dari TTS itu sendiri: jika speaker adalah speaker laptop, mikrofon bisa menangkap TTS dan mentranskrip ulang; gunakan headset
- Tumpang tindih pembicaraan: pengguna menyela, sistem lambat bereaksi = frustrasi; implementasikan pembatalan yang cepat
- Latensi yang dirasakan vs nyata: latensi 1 detik terasa oke dalam teks, terasa lambat dalam suara; optimalkan ke <500ms jika memungkinkan
Implementasi dasar di browser
Untuk eksperimen cepat:
`javascript
// 1. Perekaman
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Kirim chunks setiap 500ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. Kirim ke LLM, terima respons
// 4. Kirim respons ke /api/tts, putar hasilnya
};
mediaRecorder.start(500);`
Brainiall sudah menyediakan ini langsung di chat: klik ikon mikrofon dan tahan (press-and-hold).
Coba sekarang juga
Di chat Brainiall, klik ikon mikrofon dan tahan (press-and-hold). Bicara, lepaskan, dan terima respons dalam teks + audio. Paket Pro Rp 49rb sudah termasuk fitur suara lengkap; paket Business membuka akses ke suara premium + latensi prioritas.