
Trò chuyện bằng giọng nói (STT → LLM → TTS pipeline)
Cấu trúc của một cuộc trò chuyện bằng giọng nói
Trò chuyện bằng giọng nói với AI là một chuỗi gồm 3 API:
`
[Bạn nói] → Microphone → STT (Whisper) → văn bản
↓
LLM (Claude/GPT)
↓
[Bạn nghe] ← Loa ← TTS (pf_dora) ← văn bản`
Mỗi bước đều có độ trễ. Để trải nghiệm có cảm giác tự nhiên (như cuộc trò chuyện thật), tổng thời gian cần dưới 1.5 giây. Vào năm 2026, điều này hoàn toàn khả thi nhưng đòi hỏi kỹ thuật xây dựng cẩn thận.
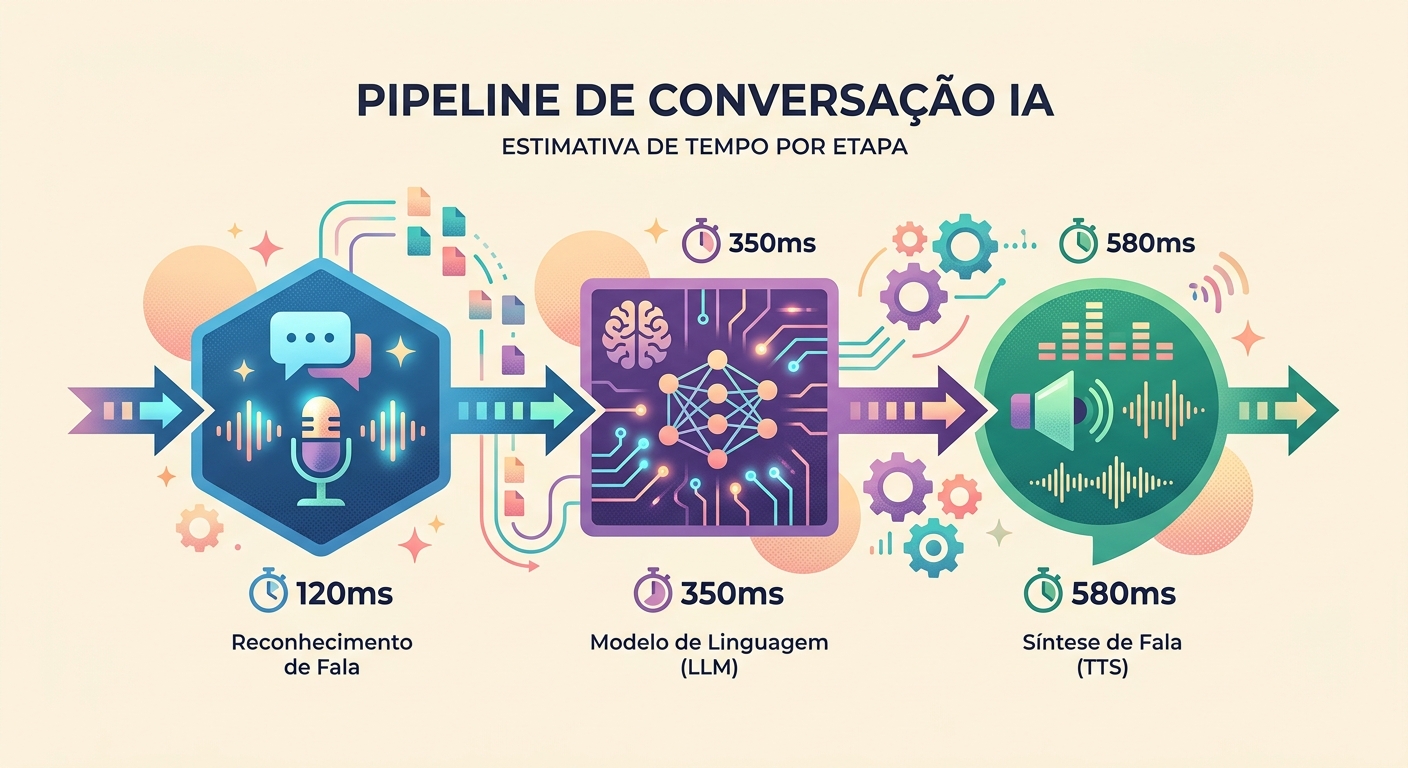
Độ trễ thực tế vào năm 2026
Đo lường trong cuộc trò chuyện thực tế trên Brainiall:
- Thu âm (mic → WAV): ~100ms (tùy thuộc phần cứng)
- STT (Whisper Large v3): 300-600ms cho câu dài 3-5 giây
- LLM (Claude Haiku để tối ưu tốc độ): 400-900ms cho token đầu tiên
- TTS (pf_dora qua unified-api): 300-500ms cho 3-5 giây âm thanh
- Phát lại (độ trễ loa): ~50ms
Tổng thời gian từ token đầu đến giọng nói: 1150-2150ms. Chấp nhận được nếu mô hình bắt đầu "nói" sớm (streaming).
Streaming là chìa khóa
Không có streaming, mỗi bước phải chờ bước trước hoàn tất: 600ms + 900ms + 500ms = tối thiểu 2000ms.
Với streaming:
- STT có thể bắt đầu phiên âm trong khi bạn vẫn đang nói (VAD — Voice Activity Detection)
- LLM bắt đầu tạo token trước khi STT hoàn tất (dựa trên dự đoán ý định)
- TTS bắt đầu đọc những từ đầu tiên trong khi LLM vẫn đang tạo phần còn lại
Độ trễ hiệu quả giảm xuống còn 400-700ms. Cảm giác hoàn toàn tự nhiên.
VAD: biết khi nào bạn ngừng nói
Thách thức tinh tế nhất: phát hiện khi bạn đã ngừng nói. Dừng quá sớm sẽ cắt đứt câu của bạn. Dừng quá muộn sẽ thêm 500ms độ trễ không cần thiết.
Các kỹ thuật:
- Im lặng hoàn toàn trong 600ms: đơn giản nhưng không xử lý được các khoảng dừng suy nghĩ tự nhiên
- Silero VAD: mô hình neural phát hiện kết thúc câu với độ chính xác ~95% trong <50ms
- Confidence từ STT: Whisper trả về confidence; nếu giảm, có thể câu đã kết thúc
- Phát hiện ngắt lời: người dùng nói lại → hủy TTS đang chạy, bắt đầu lại chu kỳ
Brainiall sử dụng Silero VAD kết hợp ngưỡng im lặng động (tự điều chỉnh theo môi trường xung quanh).
Chọn mô hình: cân bằng giữa độ trễ và chất lượng
Ở chế độ giọng nói, thường nên hy sinh một chút chất lượng LLM để đổi lấy tốc độ:
- Claude Haiku 4.5: ~400ms token đầu tiên, phản hồi súc tích, R$ 2/1M token
- GPT-5 mini: ~350ms, sáng tạo hơn Haiku, R$ 3/1M token
- Gemini 3 Flash: ~250ms, xuất sắc cho phản hồi ngắn, R$ 2/1M token
Với các cuộc trò chuyện ưu tiên chất lượng hơn tốc độ (ví dụ: gia sư ngôn ngữ chuyên sâu), hãy nâng lên Claude Sonnet 4.6 hoặc GPT-5 đầy đủ.
Các trường hợp sử dụng phù hợp với voice-mode
- Luyện hội thoại ngoại ngữ: thực hành nói tiếng Anh với AI phản hồi tự nhiên
- Trợ lý hands-free: khi lái xe, nấu ăn, tập thể dục
- Hỗ trợ tiếp cận: dành cho người gặp khó khăn khi gõ phím
- Brainstorming khi đi bộ: ghi lại ý tưởng bằng giọng nói thay vì viết
- Gia sư: hỏi và nhận câu trả lời nhanh, luồng học tập tự nhiên hơn
- Doanh nghiệp — tổng đài điện thoại: thay thế hệ thống IVR cứng nhắc bằng hội thoại tự nhiên
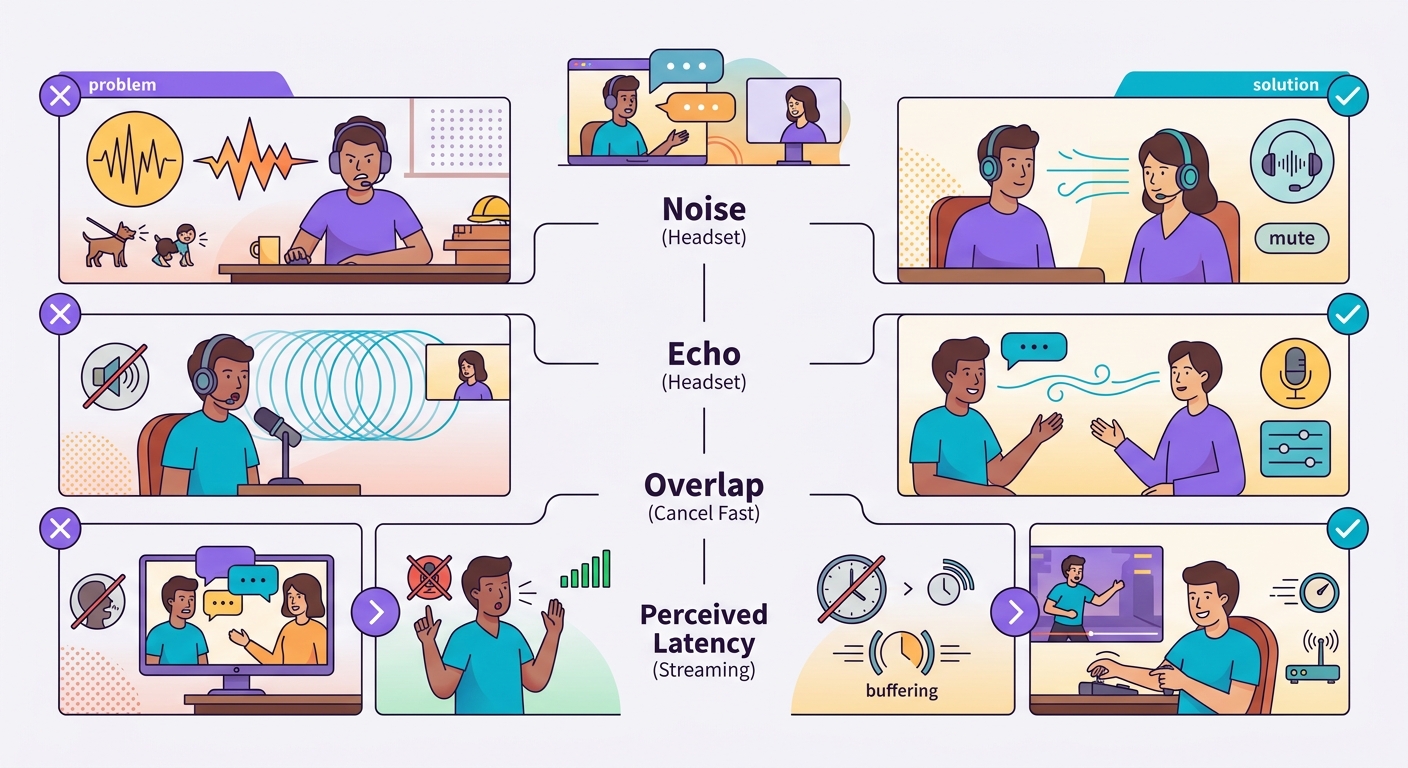
Những lỗi thường gặp
- Tiếng ồn xung quanh: âm thanh môi trường khiến VAD hoạt động sai; hãy dùng tai nghe hoặc micro định hướng
- Echo từ TTS: nếu dùng loa laptop, micro có thể thu lại âm thanh TTS và phiên âm nhầm; hãy dùng tai nghe
- Nói chồng lên nhau: người dùng ngắt lời, hệ thống phản ứng chậm = gây khó chịu; cần triển khai hủy nhanh
- Độ trễ cảm nhận vs thực tế: 1 giây có vẻ ổn với văn bản nhưng lại cảm thấy chậm với giọng nói; hãy tối ưu xuống <500ms khi có thể
Triển khai cơ bản trên trình duyệt
Để thử nghiệm nhanh:
`javascript
// 1. Thu âm
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Gửi từng chunk mỗi 500ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. Gửi đến LLM, nhận phản hồi
// 4. Gửi phản hồi đến /api/tts, phát kết quả
};
mediaRecorder.start(500);`
Brainiall đã tích hợp sẵn tính năng này trong chat: nhấp vào biểu tượng micro và giữ.
Thử ngay bây giờ
Trong chat Brainiall, nhấp vào biểu tượng micro và giữ. Nói, thả ra, nhận phản hồi bằng văn bản và âm thanh. Gói Pro $5.99 bao gồm giọng nói đầy đủ; gói Business mở khóa giọng nói cao cấp và độ trễ ưu tiên.