
GPT-5 مقابل Claude Sonnet مقابل Gemini 3 Pro: أيهما تختار؟
اختيار النموذج أهم مما تتخيل
في عام 2026، الفارق بين النماذج المتقدمة واضح جداً في المهام المحددة. التسرع باختيار الأشهر (GPT) دون تجربة 2-3 خيارات قد يكلفك 2-3 أضعاف في التوكنز، أو يمنحك نتيجة أسوأ بنسبة 20% في حالتك تحديداً.
أبرز 3 نماذج على Brainiall:
- Claude Sonnet 4.6 (Anthropic): الأفضل للاستدلال المعقد، والكتابة الطويلة، والكود
- GPT-5 (OpenAI): الأفضل للمحتوى المتعدد الوسائط (صورة+نص+كود) والإبداع
- Gemini 3 Pro (Google): الأفضل للسياقات الضخمة (+1M توكن) وانخفاض زمن الاستجابة
التكاليف الفعلية في 2026 (لكل مليون توكن)
| النموذج | المدخلات | المخرجات | ملاحظات |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | 15 ر.س | 75 ر.س | Cache hit يخفض تكلفة المدخلات 10x |
| GPT-5 | 12 ر.س | 60 ر.س | الأرخص لكل توكن |
| Gemini 3 Pro | 7 ر.س | 35 ر.س | أفضل توازن بين التكلفة والجودة |
| Claude Haiku 4.5 | 2 ر.س | 10 ر.س | سريع، مثالي للمهام البسيطة |
لشات بوت محادثة متوسط (100 رسالة، ~500 توكن لكل منها)، تتراوح التكلفة اليومية بين 10-50 ر.س. أما للتطبيقات الدُفعية (تحليل 10 آلاف مستند)، فترتفع إلى 500-2000 ر.س.
متى تستخدم كل نموذج
Claude Sonnet 4.6 لـ:
- كتابة المستندات الطويلة (التقارير، المقالات، التحليلات القانونية)
- مراجعة الكود وإعادة هيكلته
- تحليل الفروق الدقيقة في النصوص (الأدب، الفلسفة)
- المهام التي تتطلب اتباع تعليمات معقدة
- الوكلاء ذوو سلاسل الاستدلال الطويلة
GPT-5 لـ:
- الردود الإبداعية المفتوحة (العصف الذهني، السيناريوهات)
- المحتوى المتعدد الوسائط حيث الصورة والنص مهمان معاً
- الردود السريعة والمباشرة
- الحالات التي تريد فيها "أكثر النماذج شمولاً"
- كود Python وJavaScript القياسي
Gemini 3 Pro لـ:
- معالجة المستندات الضخمة (الكتب، قواعد الكود الكاملة)
- التطبيقات ذات زمن الاستجابة الحرج (<1 ثانية)
- تحليل الفيديو (متعدد الوسائط بشكل أصلي)
- المهام العلمية والرياضية
- الإنتاج على نطاق واسع حيث التكلفة عامل حاسم
اختبر حالتك عبر 3 pipelines متطابقة
لا تثق بالمعايير العامة. أنشئ تقييمك الخاص:
1. اختر 20 مثالاً تمثيلياً من استخدامك الفعلي
2. شغّل نفس الـ prompt على النماذج الثلاثة
3. قيّم الردود بشكل أعمى (دون معرفة أيها أيّ)
4. قِس: الدقة، زمن الاستجابة، التكلفة
كثيراً ما يكون النموذج "الأضعف" في المعايير العامة هو الأفضل لحالتك، لأن مهمتك تمتلك خصائص محددة لا تلتقطها تلك المعايير.
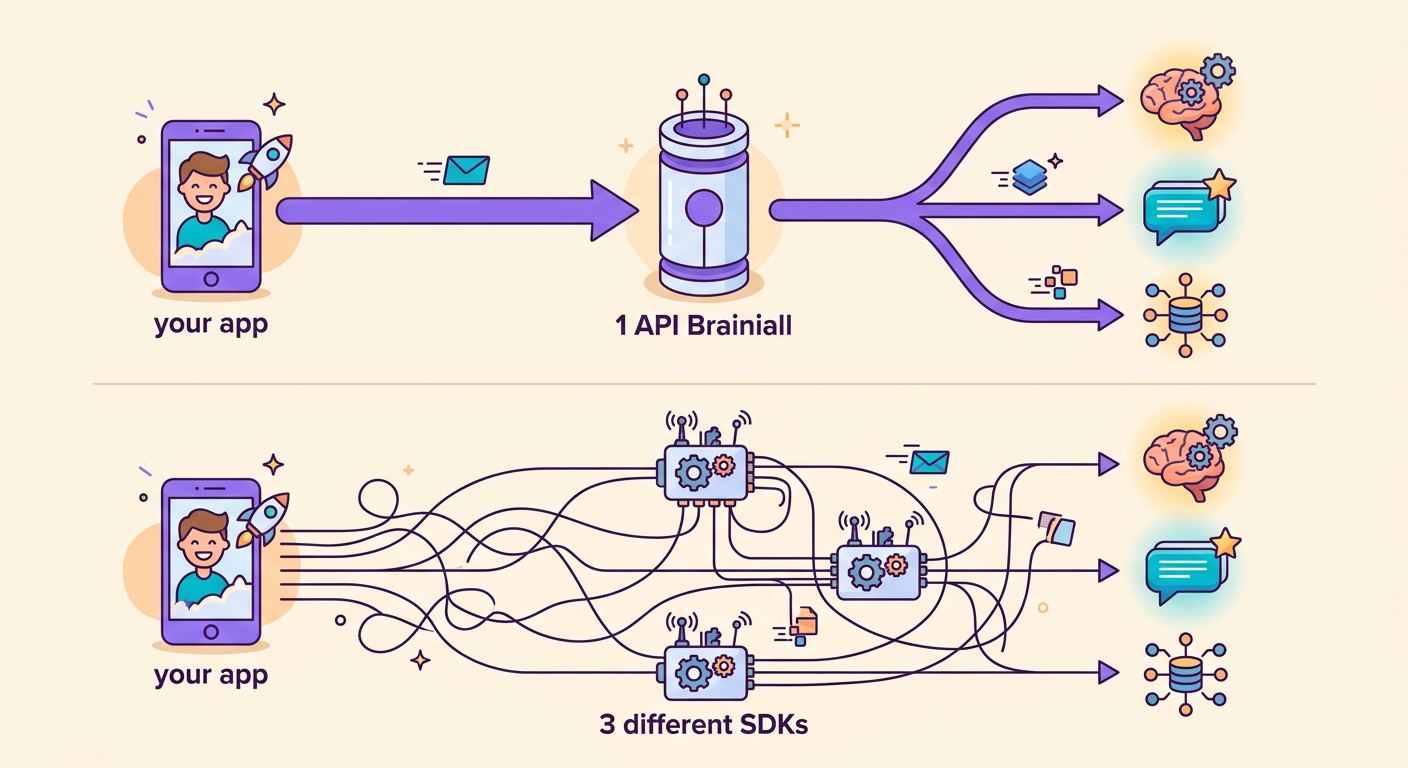
الاستخدام عبر Brainiall
الميزة الكبرى لـ gateway الخاص بنا: تغيير النموذج بتعديل string واحدة فقط.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Explique entropia em 3 frases."))`
بدون Brainiall، ستحتاج إلى 3 حسابات، و3 SDKs، و3 فواتير منفصلة. مع gateway موحد، كل شيء شفاف وسلس.
أخطاء شائعة عند المقارنة
- Prompt غير محايد: إذا كان الـ prompt محسّناً لـ GPT، فقد يبدو Claude أسوأ بشكل غير عادل
- مثال واحد فقط: التباين بين التشغيلات مرتفع؛ استخدم N=20+ كحد أدنى
- مقياس خاطئ: قياس الدقة وحدها يتجاهل التكلفة وزمن الاستجابة والمتانة
- تجاهل الـ cache: يمتلك Claude cache للـ prompt يخفض التكلفة 10x للأنظمة المتكررة
- عدم الاختبار بالعربية: جميعها ممتازة بالإنجليزية؛ بالعربية يكون الفارق أكبر
جرّب الآن
في شات Brainiall، اختر نموذجاً من القائمة المنسدلة العلوية واطرح سؤالك. ثم بدّل إلى نموذج آخر وقارن النتائج. اشتراك Pro بـ 29 ر.س يتيح الوصول إلى 15 نموذجاً؛ وخطة Business تفتح لك جميع النماذج.