
اكتشف اللغة في النصوص متعددة اللغات
لماذا يُعدّ الكشف التلقائي عن اللغة مفيداً
سيناريوهات واقعية:
- روبوت محادثة متعدد اللغات: يكتب المستخدم "Hola, como estoy?" → يكتشف الإسبانية → يرد بالإسبانية (بدلاً من البرتغالية التي ستكون الافتراضية)
- تغذية المحتوى العالمي: محرك تجميع الأخبار يحتاج إلى تجميع المقالات حسب اللغة قبل الترجمة
- الدعم الفني: تذكرة باللغة اليابانية يجب أن تذهب إلى فريق اليابان، لا فريق البرازيل
- الإشراف على المحتوى: قواعد المحتوى الحساس تتفاوت حسب المنطقة واللغة
- التحليلات: قياس التنوع اللغوي لجمهورك
نموذج fastText language identification، المفتوح المصدر من Facebook، يكتشف 176 لغة في أقل من 10 مللي ثانية لكل نص.
كيف يميّز النموذج بين اللغات
يمثّل fastText كل كلمة على شكل n-grams من الأحرف (subwords)، ثم يجمع هذه المتجهات ويصنّفها باستخدام انحدار softmax. أسباب نجاحه:
- البرتغالية تتميز بـ "ção" و"nh" و"lh"
- الإنجليزية تتميز بـ "th" و"ing" و"ed"
- الألمانية تتميز بـ "sch" و"ch" و"äöü"
- الصينية المكتوبة بالبينيين لها أنماط مختلفة تماماً عن الهانزي
يدرس النموذج البصمة الإحصائية لـ n-grams ويتخذ قراره. النصوص القصيرة (أقل من 3 كلمات) غامضة؛ أما النصوص التي تحتوي على 20 كلمة أو أكثر فتتجاوز دقتها 99%.
الحالات الصعبة وكيفية التعامل معها
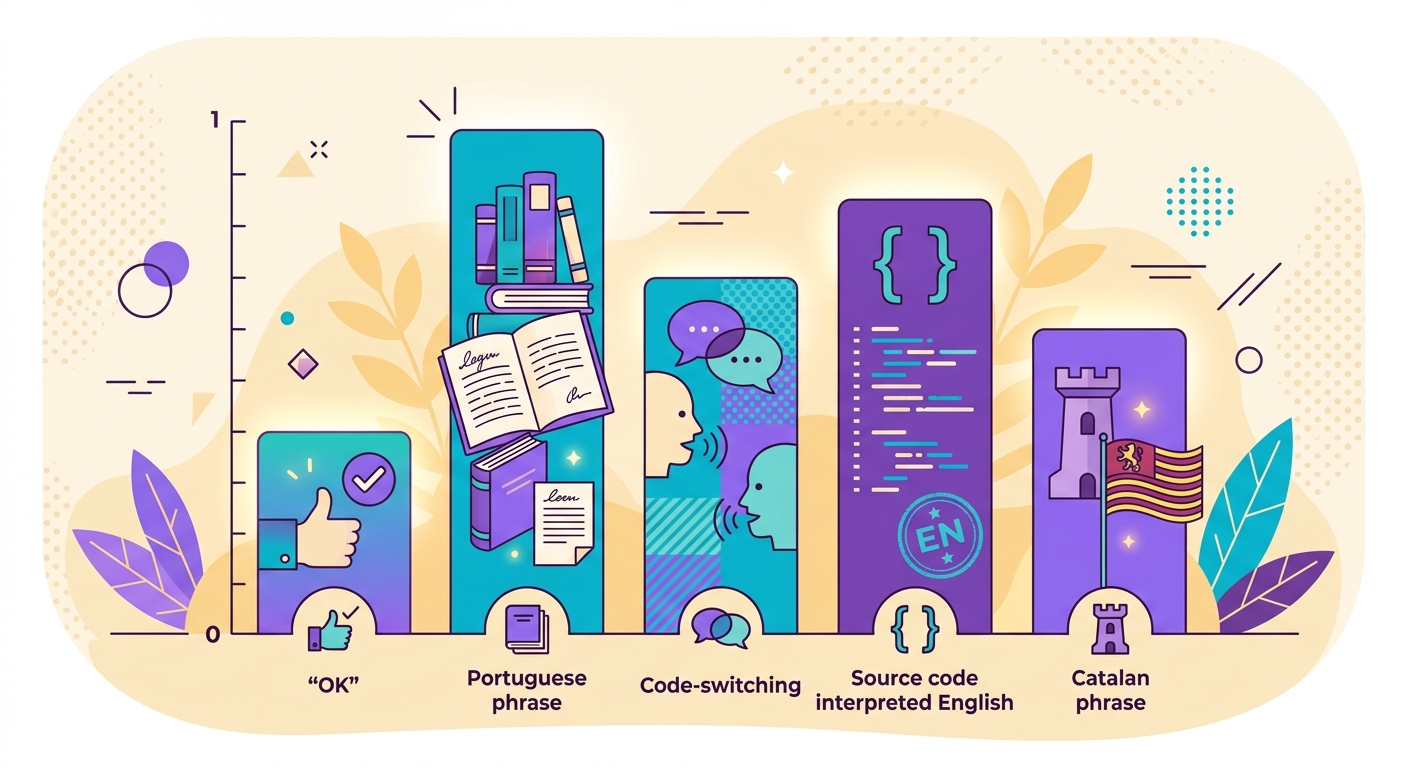
- التبديل بين الأكواد: نص يمزج لغتين ("Hello, tudo bem?") — يعيد النموذج اللغة السائدة مع درجة ثقة منخفضة
- اللغات المتقاربة: البرتغالية مقابل الإسبانية مقابل الكتالونية — يصيب fastText أكثر من 90% لكن الحالات الحدية موجودة
- النقحرة: الصينية المكتوبة بالبينيين، أو العربية بالحروف اللاتينية — قد يكتشفها النموذج خطأً كـ"إنجليزية"
- النصوص القصيرة جداً: "OK" قد تنتمي لأي لغة — تُعاد دائماً بدرجة ثقة منخفضة، لذا استخدم عتبة تصفية
- كود البرمجة: النص البرمجي يُكتشف كـ"إنجليزية" — قم بتصفيته مسبقاً إذا لزم الأمر
العتبة الموصى بها: اقبل الكشف فقط عند confidence > 0.75. وما دون ذلك، ضعه في خانة "غير معروف" وأحله إلى مراجع بشري.
التكامل مع بنيتك التقنية
مثال Python نموذجي:
`python
import httpx
r = httpx.post(
"https://api.brainiall.com/api/nlp/language",
json={"text": "Hola, ¿cómo estás hoy?"},
headers={"Authorization": "Bearer brnl-xxx"}
)
# {"language": "es", "confidence": 0.96, "top_3": [
# {"lang": "es", "conf": 0.96},
# {"lang": "pt", "conf": 0.02},
# {"lang": "ca", "conf": 0.01}
# ]}`
استخدم top_3 عندما تريد عرض بدائل في حالات الثقة المنخفضة (مثال: "يبدو أنها إسبانية، لكن قد تكون كتالونية — يرجى التأكيد").
حالات الاستخدام المتقدمة
- المعالجة المسبقة لـ NLP: قبل تحليل المشاعر، اكتشف اللغة ووجّه إلى النموذج المناسب
- التصفية: إزالة النصوص خارج اللغة المستهدفة من مجموعات البيانات الكبيرة
- توجيه حركة المرور: توزيع الحمل بين مجموعات متعددة اللغات
- التجزئة: تقسيم المستندات الطويلة حسب اللغة عند اختلاطها
- البحث: السماح للمستخدم بالبحث عن "أرني المحتوى باللغة العربية فقط في هذه المنصة"
جرّبه الآن
اطلب "اكتشف لغة هذا النص: [الصق]" في محادثة Brainiall. API متاح على /api/nlp/language. زمن الاستجابة المعتاد أقل من 10 مللي ثانية — مناسب للاستخدام في الوقت الفعلي. خطة Pro توفر استخداماً سخياً؛ وخطة Business تشمل batch API.