
Clona tu voz con 10 segundos de audio
Por qué 10 segundos son suficientes hoy (hace 2 años no lo eran)
Hasta 2023, clonar una voz requería entre 30 minutos y varias horas de grabación limpia, en estudio, leyendo un corpus específico. Hoy, modelos como Kokoro TTS y XTTS v2 hacen el mismo trabajo con 6 a 15 segundos de audio de referencia, en cualquier entorno razonablemente silencioso.
¿Qué cambió? La arquitectura. Los modelos modernos separan lo que dices (contenido) de cómo lo dices (timbre, prosodia, ritmo). Un encoder pequeño extrae tu "perfil vocal" en pocos cientos de milisegundos; luego, cualquier texto puede sintetizarse usando ese perfil. El modelo de síntesis ya sabe cómo hablar español, inglés u otro idioma — simplemente está "pintando" el texto con tu voz.
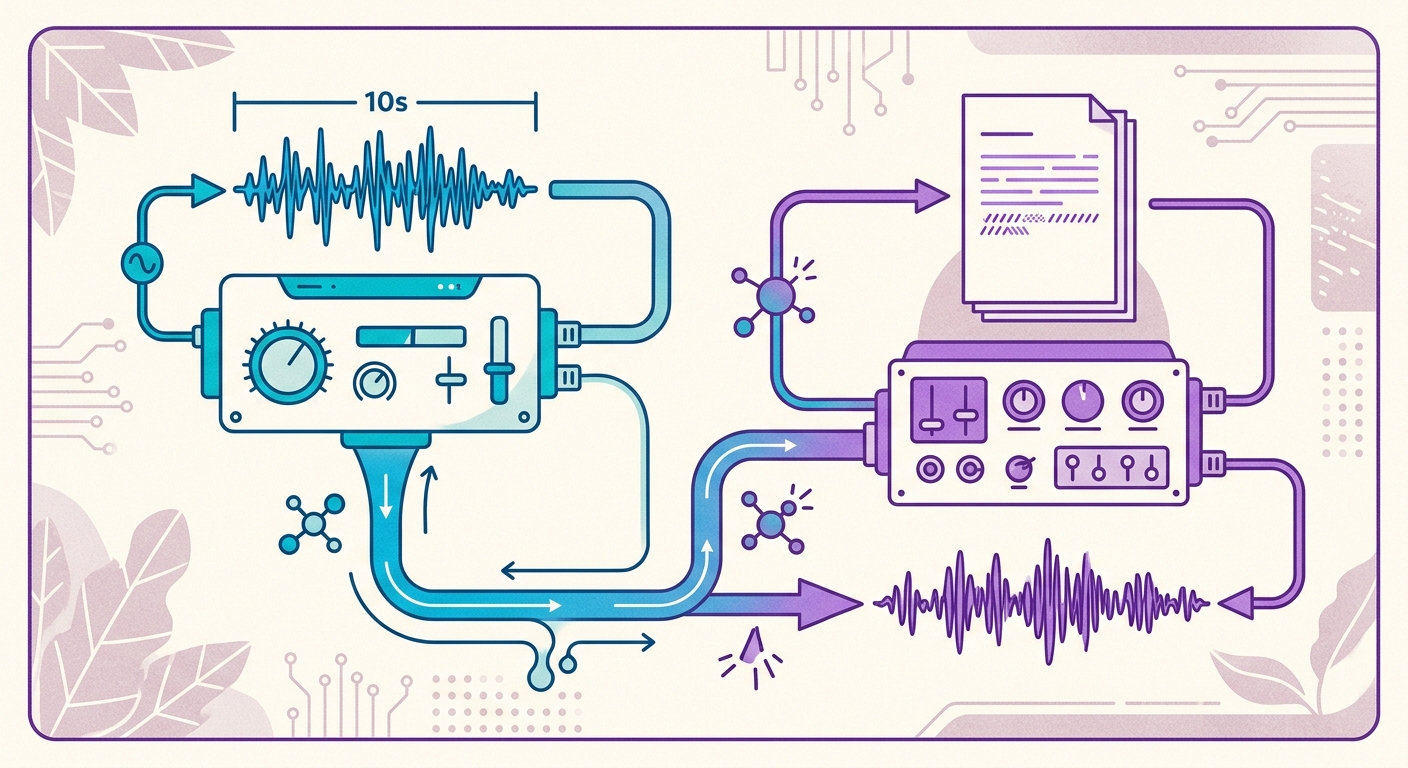
El pipeline de Brainiall en la práctica
En Brainiall usamos un modelo nativo de voz corriendo en GPU dedicada, con 54 voces preentrenadas en 9 idiomas — incluyendo 3 voces neurales en portugués brasileño (pf_dora, pm_alex, pm_santa). Para clonar una voz nueva, el flujo es:
1. Grabas 10 segundos hablando cualquier cosa (por ejemplo, leyendo este párrafo)
2. El encoder extrae tu "voice embedding" — un vector de 512 números
3. El synthesizer recibe el texto que quieres narrar + tu embedding
4. Recibes un MP3 de vuelta en 2-4 segundos (tiempo real < 1, es decir, la síntesis es más rápida que el audio final)
Cuándo suena natural y cuándo todavía suena robótico
Suena excelente cuando:
- Tu audio de referencia es limpio (ruido de fondo bajo, sin eco)
- Hablas en tono neutro, sin risas ni interjecciones extremas
- El texto a narrar está en el mismo idioma que la muestra
- Frases cortas a medianas (hasta 30 palabras por frase)
Todavía falla cuando:
- Pides emociones muy específicas (ira explosiva, llanto)
- El texto tiene muchos nombres extranjeros o jergas técnicas poco comunes
- La muestra original tenía ruido ambiental — el modelo copia el ruido también
- Audios muy largos (>2 minutos) empiezan a tener "drift" prosódico
Los límites éticos (importante)
Clonar una voz sin consentimiento es un problema jurídico y ético serio. En Brainiall:
- Las voces clonadas están asociadas a tu cuenta y solo tú puedes usarlas
- Nunca clonamos la voz de terceros a partir de audios públicos sin permiso explícito del titular
- El contenido generado pasa por moderación antes de ser entregado (detectamos intentos de suplantación política o de celebridades)
- Puedes eliminar tu voice embedding en cualquier momento desde Mis datos (LGPD)
El voice cloning tiene usos legítimos muy poderosos: narrar libros con tu propia voz, crear contenido en múltiples idiomas manteniendo tu identidad, accesibilidad para personas que han perdido el habla. Úsalo con responsabilidad.
Pruébalo ahora mismo
En el chat de Brainiall, haz clic en el micrófono del campo de entrada, graba 10 segundos (cualquier contenido) y luego escribe un texto para narrar. La clonación en sí es gratuita hasta 3 intentos por mes. El plan Pro por US$5.99 desbloquea 100 imágenes y 10 videos/mes, además de las 54 voces listas para usar — muchas de ellas ya suenan más naturales que una voz clonada por un aficionado.