
GPT-5 vs Claude Sonnet vs Gemini 3 Pro: ¿cuál elegir?
La elección del modelo importa más de lo que crees
En 2026, la diferencia entre modelos top-tier es notable en tareas específicas. Saltarse la prueba de 2-3 opciones e ir directo con el más famoso (GPT) puede costarte 2-3x más en tokens o darte un resultado 20% peor en tu caso particular.
Los 3 modelos dominantes en Brainiall:
- Claude Sonnet 4.6 (Anthropic): el mejor para razonamiento complejo, escritura larga y código
- GPT-5 (OpenAI): el mejor para multimodal (imagen+texto+código) y creatividad
- Gemini 3 Pro (Google): el mejor para contextos gigantes (1M+ tokens) y baja latencia
Costos reales en 2026 (por millón de tokens)
| Modelo | Input | Output | Notas |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | R$ 15 | R$ 75 | Cache hit reduce el input 10x |
| GPT-5 | R$ 12 | R$ 60 | Más económico por token |
| Gemini 3 Pro | R$ 7 | R$ 35 | Mejor costo/calidad |
| Claude Haiku 4.5 | R$ 2 | R$ 10 | Rápido, ideal para tareas simples |
Para un chatbot conversacional promedio (100 mensajes, ~500 tokens cada uno), el costo diario ronda los R$ 10-50. Para aplicaciones batch (análisis de 10k documentos), puede subir a R$ 500-2000.
Cuándo usar cada uno
Claude Sonnet 4.6 para:
- Redacción de documentos extensos (informes, ensayos, análisis jurídicos)
- Code review y refactoring
- Análisis de matices en textos (literatura, filosofía)
- Tareas que requieren seguir instrucciones complejas
- Agentes con cadenas largas de razonamiento
GPT-5 para:
- Respuestas creativas abiertas (brainstorming, guiones)
- Multimodal donde imagen + texto son importantes
- Respuestas rápidas y directas
- Casos donde quieres el "modelo más genérico posible"
- Código Python y JavaScript estándar
Gemini 3 Pro para:
- Procesar documentos enormes (libros, bases de código completas)
- Aplicaciones con latencia crítica (<1s)
- Análisis de videos (multimodal de video nativo)
- Tareas científicas y matemáticas
- Producción a escala donde el costo importa
Prueba tu caso con 3 pipelines idénticos
No confíes en benchmarks genéricos. Crea tu propio eval:
1. Selecciona 20 ejemplos representativos de tu uso real
2. Ejecuta el mismo prompt en los 3 modelos
3. Evalúa las respuestas a ciegas (sin saber cuál es cuál)
4. Mide: accuracy, latencia y costo
Muchas veces el modelo "peor" en benchmarks genéricos es el mejor para tu caso, porque tu tarea tiene características específicas que el benchmark no captura.
Usando a través de Brainiall
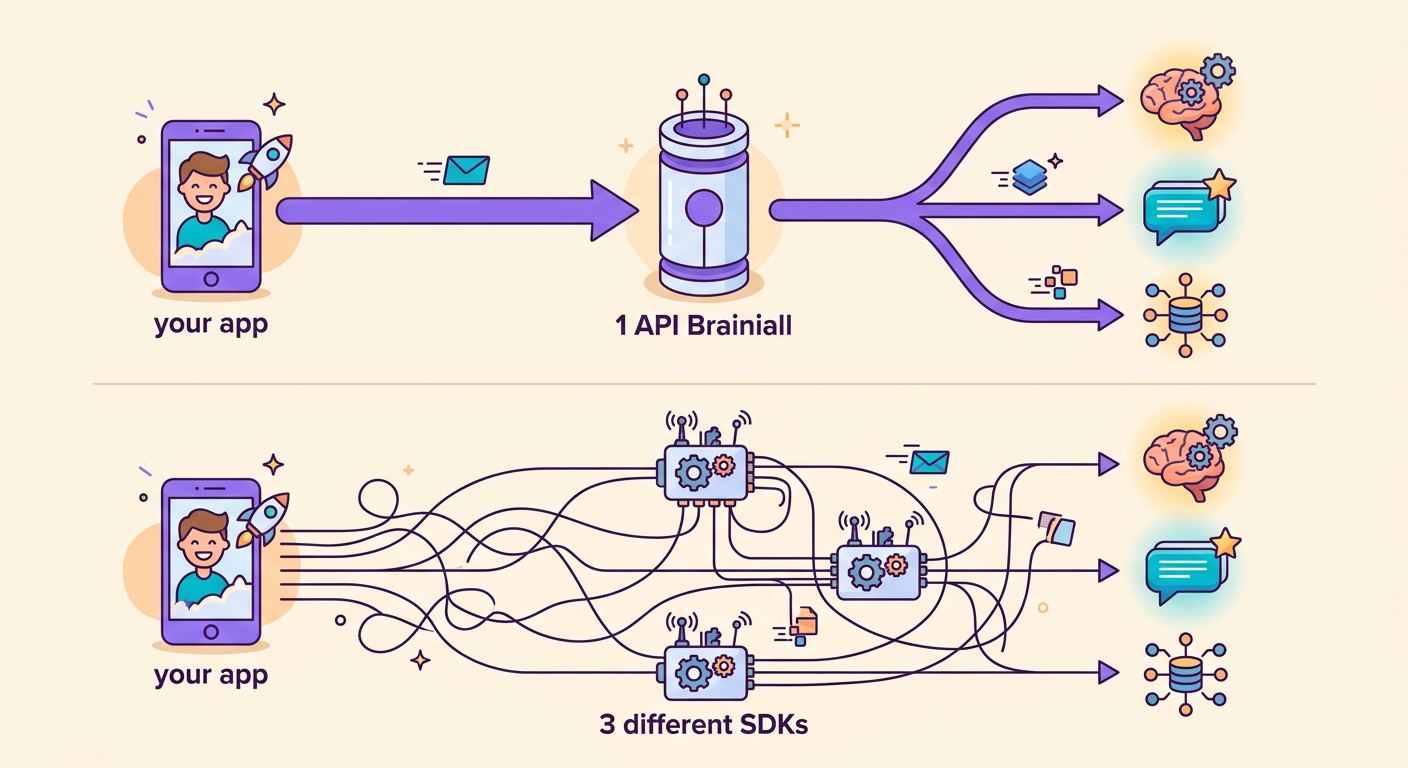
La gran ventaja de nuestro gateway: cambias de modelo modificando solo 1 string.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Explica la entropía en 3 frases."))`
Sin Brainiall, necesitarías 3 cuentas, 3 SDKs y 3 billings separados. Con un gateway único, todo es transparente.
Trampas al comparar
- Prompt no neutro: si tu prompt fue optimizado para GPT, Claude puede parecer peor de forma injusta
- Un solo ejemplo: la variabilidad entre ejecuciones es alta; usa un mínimo de N=20+
- Métrica equivocada: medir solo accuracy ignora costo, latencia y robustez
- Ignorar el cache: Claude tiene cache de prompt que reduce el costo 10x en sistemas repetitivos
- No probar en español: todos son buenos en inglés; en español la diferencia es mayor
Pruébalo ahora mismo
En el chat de Brainiall selecciona un modelo en el dropdown superior y haz tu pregunta. Cámbialo a otro modelo y compara. El plan Pro a US$5.99 da acceso a 15 modelos; el Business desbloquea todos.