
Detecta el idioma en textos multilingües
Por qué detectar el idioma automáticamente es útil
Escenarios reales:
- Chatbot multilingüe: el usuario escribe "Hola, como estoy?" → detecta español → responde en español (en lugar de portugués, que sería el idioma por defecto)
- Feed de contenido global: un agregador de noticias necesita agrupar artículos por idioma antes de traducirlos
- Soporte: un ticket en japonés debe ir al equipo de Japón, no al de Brasil
- Moderación: las reglas de contenido sensible varían según la región e idioma
- Analytics: mide la diversidad lingüística de tu audiencia
El modelo fastText language identification, open source de Facebook, detecta 176 idiomas en menos de 10ms por texto.
Cómo el modelo distingue idiomas
fastText representa cada palabra como n-grams de caracteres (subwords). Luego suma esos vectores y clasifica con regresión softmax. Por qué funciona:
- El portugués tiene características como "ção", "nh", "lh"
- El inglés tiene características como "th", "ing", "ed"
- El alemán tiene "sch", "ch", "äöü"
- El mandarín escrito en pinyin tiene patrones completamente distintos a los del hanzi
El modelo analiza la firma estadística de los n-grams y decide. Los textos cortos (<3 palabras) son ambiguos; los textos con 20+ palabras tienen una precisión > 99%.
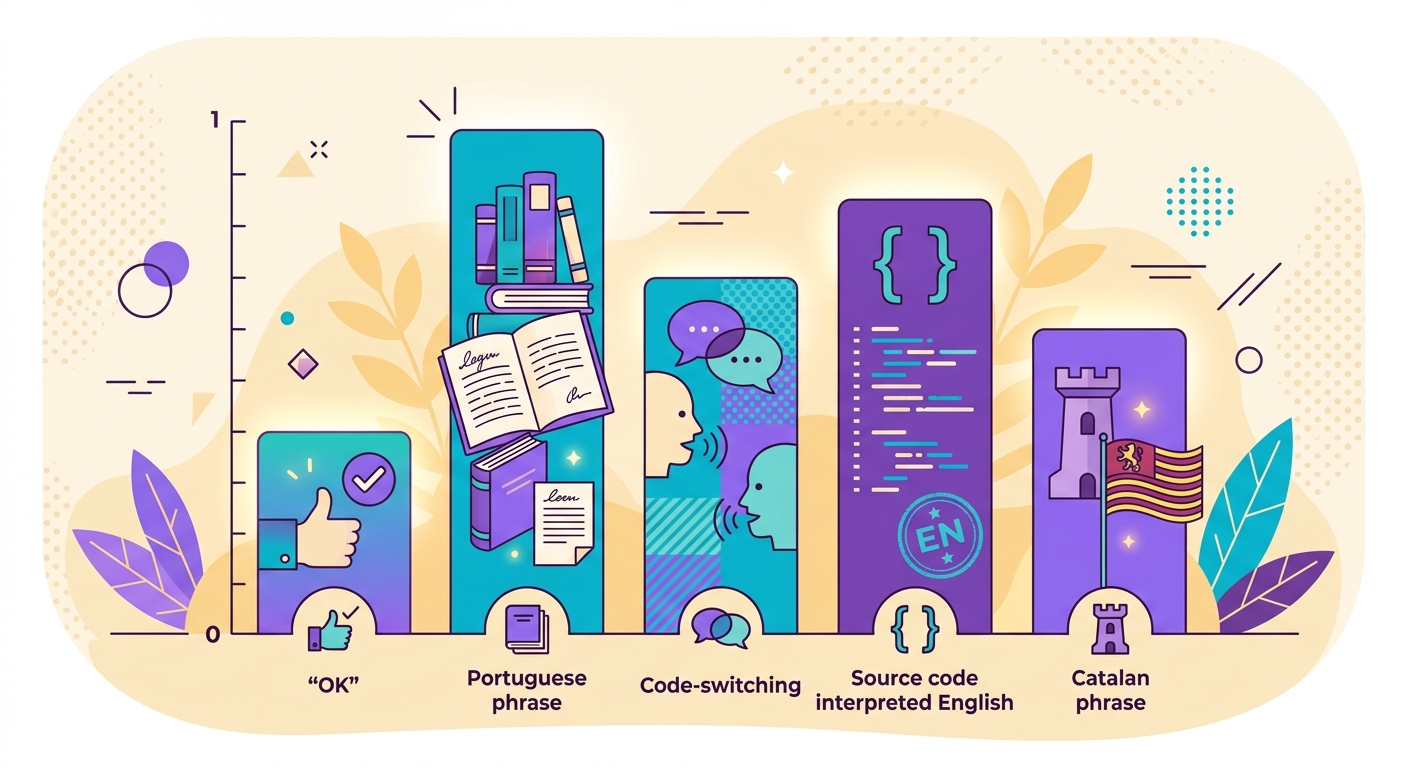
Casos difíciles y cómo manejarlos
- Code-switching: texto que mezcla 2 idiomas ("Hello, tudo bem?") — el modelo devuelve el idioma dominante con un score reducido
- Idiomas cercanos: portugués vs. español vs. catalán — fastText acierta en más del 90% de los casos, pero existen casos límite
- Transliteración: chino escrito en pinyin, árabe en letras latinas — el modelo los detecta falsamente como "inglés"
- Textos muy cortos: "OK" podría ser cualquier idioma — siempre devuelve un score bajo; debes usar un threshold
- Código de programación: el código fuente se detecta como "inglés" — filtrarlo antes si es necesario
Threshold recomendado: acepta la detección solo si la confianza es > 0.75. Por debajo de ese valor, márcalo como "unknown" y deriva a un humano.
Integrándolo en tu stack
Ejemplo típico en Python:
`python
import httpx
r = httpx.post(
"https://api.brainiall.com/api/nlp/language",
json={"text": "Hola, ¿cómo estás hoy?"},
headers={"Authorization": "Bearer brnl-xxx"}
)
# {"language": "es", "confidence": 0.96, "top_3": [
# {"lang": "es", "conf": 0.96},
# {"lang": "pt", "conf": 0.02},
# {"lang": "ca", "conf": 0.01}
# ]}`
Usa top_3 cuando quieras mostrar alternativas en casos de baja confianza (ej: "Parece ser español, pero podría ser catalán — confirma").
Casos de uso avanzados
- Pre-procesamiento de NLP: antes del análisis de sentimiento, detectar el idioma y enrutar al modelo correcto
- Filtering: eliminar textos fuera del idioma objetivo en datasets grandes
- Traffic routing: balancear la carga entre clusters multilingües
- Segmentación: dividir documentos largos por idioma cuando están mezclados
- Búsqueda: permitir que el usuario filtre "muéstrame solo contenido en español de esta plataforma"
Pruébalo ahora mismo
Escribe "detecta el idioma de este texto: [pega aquí]" en el chat de Brainiall. API en /api/nlp/language. Latencia típica < 10ms — ideal para uso en tiempo real. El plan Pro tiene un uso generoso; el plan Business incluye la API en modo batch.