
Detecta toxicidad en comentarios con IA
El apocalipsis Perspective: qué pasó
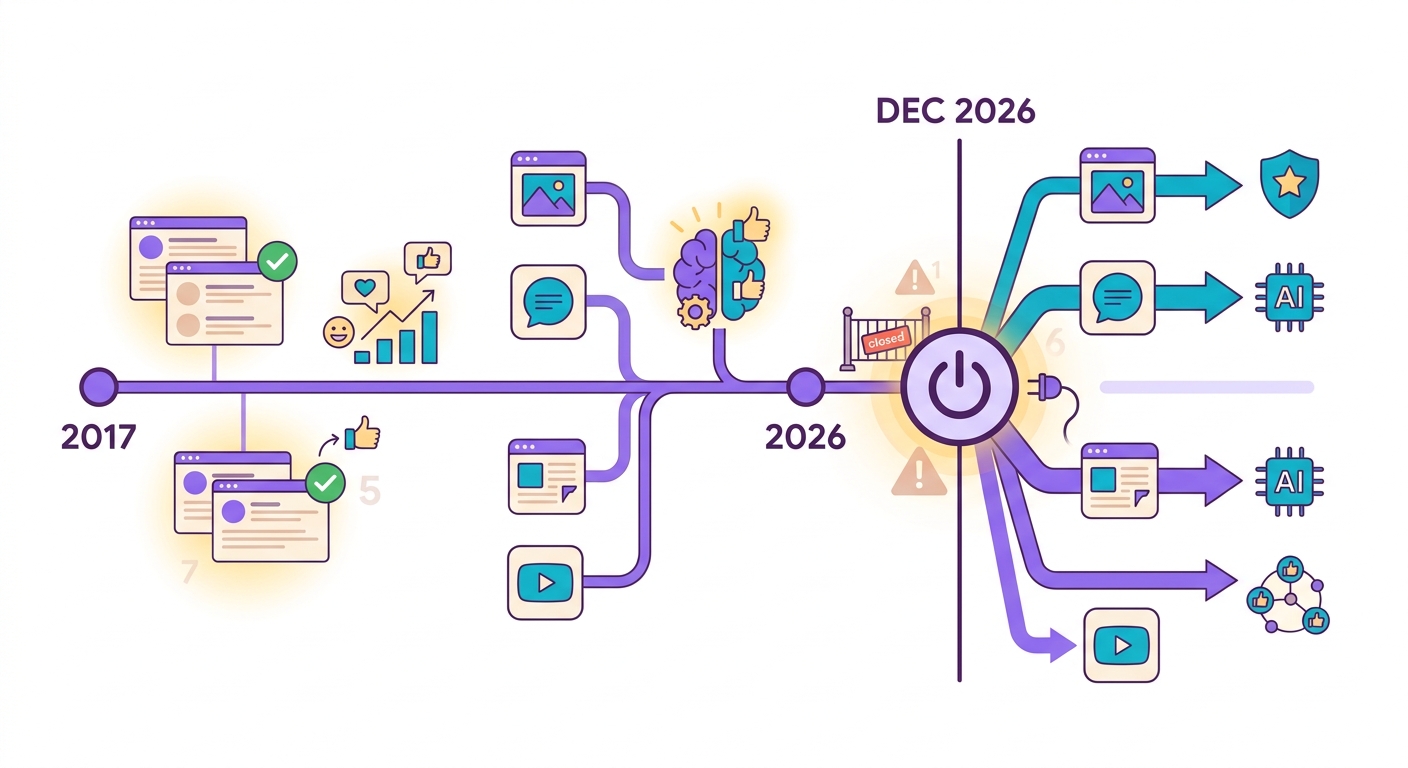
En octubre de 2024, Google anunció que el Perspective API — el servicio gratuito de detección de toxicidad más usado en el mundo — sería descontinuado en diciembre de 2026. Las plataformas que dependían de él (Reddit, New York Times, The Guardian, miles de foros) tienen 2 años para migrar.
El problema: Perspective era gratuito. Las alternativas comerciales como Azure Content Safety y AWS Comprehend cobran desde US$ 1 por 1.000 análisis. Para un foro grande con 100k comentarios/día, eso se convierte en $3k/mes solo en moderación.
Brainiall ofrece moderación con modelos Detoxify + Unitary ejecutándose en ONNX local (CPU), con un costo menor a R$ 0,001 por análisis — 100x más barato.
Las 7 categorías que importan
Detoxify clasifica el texto en 7 dimensiones con un score de 0 a 1:
1. Toxicity: insulto general, agresividad
2. Severe toxicity: amenaza, odio extremo
3. Obscene: groserías y lenguaje vulgar
4. Threat: amenaza de violencia física
5. Insult: ataque personal directo
6. Identity hate: discriminación basada en grupo (raza, género, religión)
7. Sexual explicit: contenido sexualmente explícito
Tu política define los thresholds. Ejemplo común: bloquear si severe_toxicity > 0.5 O identity_hate > 0.6 O threat > 0.3. Las groserías aisladas (obscene > 0.8) generalmente pasan con advertencia, no con bloqueo.
El problema del español
Detoxify fue entrenado en inglés. Funciona al 95%+ en comentarios en inglés. En español, baja al 75-85% — los regionalismos y expresiones locales (muchas de ellas inofensivas) confunden al modelo.
En Brainiall usamos una capa adicional: un clasificador híbrido que combina:
- Detoxify multilingual (70% de la decisión)
- Lista de palabras específicas en español (20%)
- LLM small (Gemma 3 o similar) para casos borderline (10%)
Esto eleva la precisión al 92%+ en español, manteniendo una latencia < 80ms.
Cuando la IA falla peligrosamente
- Sarcasmo: "¡Me encantó cómo arruinaste mi vida, gracias!" — score positivo, pero el texto es hostil
- Sátira legítima: las críticas políticas humorísticas pueden marcarse como ataque
- Contexto médico: "voy a matar al paciente de tanto trabajar" (trabajador de salud agotado) — falso positivo
- Citas: un artículo que cita un post racista para criticarlo es analizado como el racista
- Code-switching: quien mezcla inglés + español + emojis confunde al modelo
Solución práctica: combina el score automático con soft-moderation (pedir confirmación antes de publicar) en lugar de hard-block para los casos borderline.
Integrándolo en tu plataforma
Flujo recomendado:
1. El usuario escribe un comentario → fetch POST /api/toxicity con { text }
2. La API devuelve { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Tu código decide: bloquear, advertir o aprobar
4. Si advierte, muestra "Revisa — puede ofender a algunos usuarios" antes de publicar
5. Para bloqueos, log + notifica a la moderación humana
No hagas moderación 100% automática. Mantén siempre una cola humana para los casos borderline.
Pruébalo ahora mismo
En el chat de Brainiall, escribe "analiza la toxicidad de este comentario: [pega aquí]". O vía API en la ruta /api/nlp/toxicity. El plan Pro US$5.99 incluye 10.000 análisis/mes; el Business tiene cola priority + batch de millones.