
Clonez votre voix avec 10 secondes d'audio
Pourquoi 10 secondes suffisent aujourd'hui (ce n'était pas le cas il y a 2 ans)
Jusqu'en 2023, cloner une voix nécessitait entre 30 minutes et plusieurs heures d'enregistrement propre, en studio, à partir d'un corpus spécifique. Aujourd'hui, des modèles comme Kokoro TTS et XTTS v2 accomplissent le même travail avec seulement 6 à 15 secondes d'audio de référence, dans n'importe quel environnement raisonnablement silencieux.
Qu'est-ce qui a changé ? L'architecture. Les modèles modernes séparent ce que vous dites (le contenu) de la façon dont vous le dites (timbre, prosodie, rythme). Un encodeur léger extrait votre « profil vocal » en quelques centaines de millisecondes ; n'importe quel texte peut ensuite être synthétisé en utilisant ce profil. Le modèle de synthèse sait déjà parler le français, l'anglais ou d'autres langues — il « peint » simplement le texte avec votre voix.
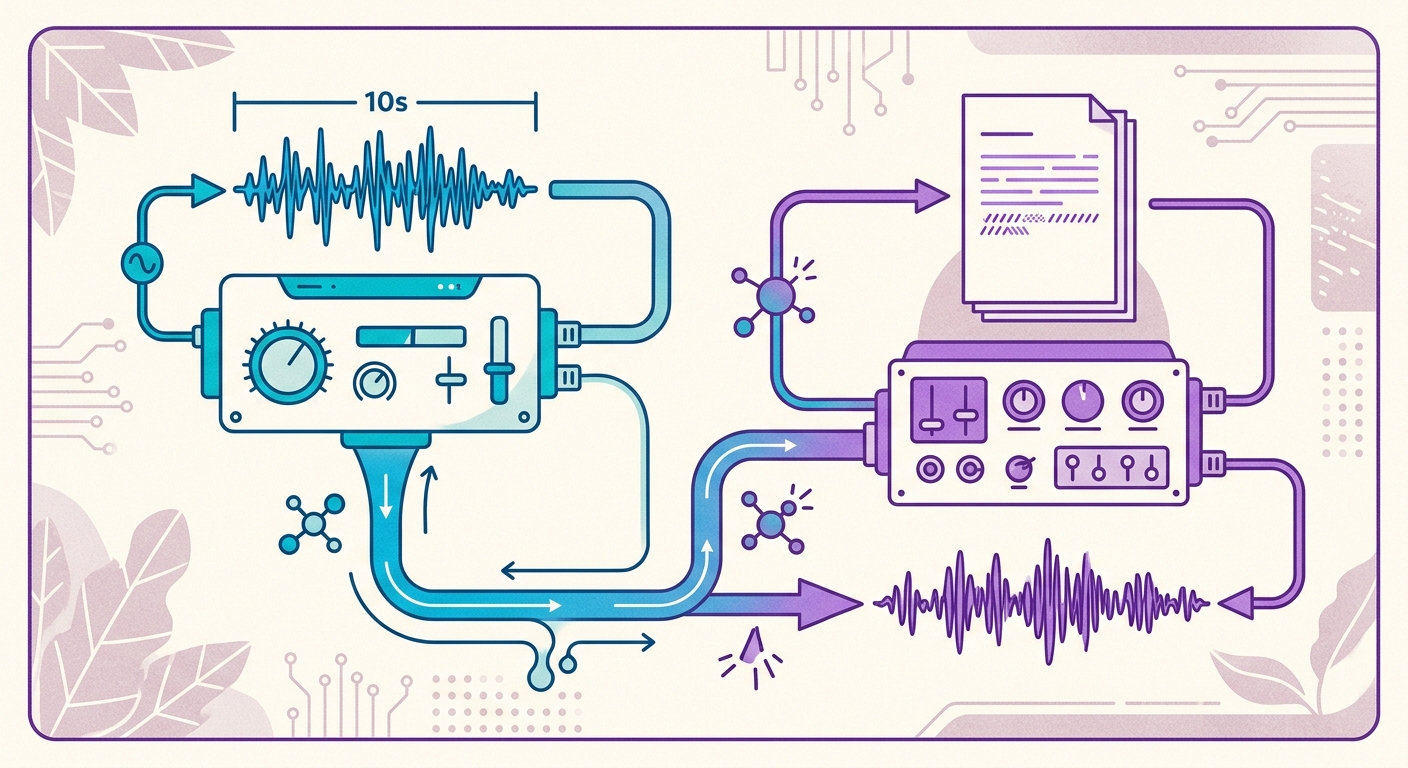
Le pipeline Brainiall en pratique
Chez Brainiall, nous utilisons un modèle vocal natif tournant sur GPU dédié, avec 54 voix pré-entraînées dans 9 langues — dont 3 voix neurales en portugais brésilien (pf_dora, pm_alex, pm_santa). Pour cloner une nouvelle voix, le processus est le suivant :
1. Vous enregistrez 10 secondes en disant n'importe quoi dans votre langue (par exemple, en lisant ce paragraphe)
2. L'encodeur extrait votre « voice embedding » — un vecteur de 512 valeurs
3. Le synthesizer reçoit le texte à narrer + votre embedding
4. Vous recevez un MP3 en retour en 2 à 4 secondes (temps réel < 1, c'est-à-dire que la synthèse est plus rapide que l'audio final)
Quand le résultat est naturel, quand il sonne encore robotique
Excellent résultat quand :
- Votre audio de référence est propre (bruit de fond faible, sans écho)
- Vous parlez sur un ton neutre, sans rires ni interjections excessives
- Le texte à narrer est dans la même langue que l'échantillon
- Les phrases sont courtes à moyennes (jusqu'à 30 mots par phrase)
Encore imparfait quand :
- Vous demandez des émotions très spécifiques (colère explosive, pleurs)
- Le texte contient de nombreux noms étrangers ou des jargons techniques rares
- L'échantillon original comportait du bruit ambiant — le modèle le reproduit également
- Les audios très longs (>2 minutes) commencent à présenter un « drift » prosodique
Les limites éthiques (important)
Cloner une voix sans consentement est un problème juridique et éthique sérieux. Chez Brainiall :
- Les voix clonées sont associées à votre compte et vous seul pouvez les utiliser
- Nous ne clonons jamais la voix de tiers à partir d'audios publics sans la permission explicite de leur propriétaire
- Le contenu généré est soumis à une modération avant d'être délivré (nous détectons les tentatives d'usurpation d'identité politique ou de célébrités)
- Vous pouvez supprimer votre voice embedding à tout moment dans Mes données (RGPD)
Le voice cloning offre des usages légitimes puissants : narrer des livres avec votre propre voix, créer du contenu en plusieurs langues tout en conservant votre identité, ou encore améliorer l'accessibilité pour les personnes ayant perdu l'usage de la parole. Utilisez-le de manière responsable.
Testez dès maintenant
Dans le chat Brainiall, cliquez sur le microphone dans le champ de saisie, enregistrez 10 secondes (n'importe quel contenu), puis saisissez un texte à narrer. Le clonage lui-même est gratuit jusqu'à 3 essais par mois. Le plan Pro à 29 R$ débloque 100 images et 10 vidéos par mois, ainsi que les 54 voix prêtes à l'emploi — dont beaucoup sonnent déjà plus naturellement qu'une voix clonée en amateur.