
GPT-5 vs Claude Sonnet vs Gemini 3 Pro : lequel choisir ?
Le choix du modèle compte plus que vous ne le pensez
En 2026, la différence entre les modèles top-tier est significative sur des tâches spécifiques. Sauter l'étape de tester 2-3 options et foncer directement avec le plus connu (GPT) peut coûter 2-3x plus en tokens ou donner un résultat 20% moins bon dans votre cas précis.
Les 3 modèles dominants sur Brainiall :
- Claude Sonnet 4.6 (Anthropic) : idéal pour le raisonnement complexe, la rédaction longue, le code
- GPT-5 (OpenAI) : idéal pour le multimodal (image+texte+code), la créativité
- Gemini 3 Pro (Google) : idéal pour les contextes gigantesques (1M+ tokens), la faible latence
Coûts réels en 2026 (par million de tokens)
| Modèle | Input | Output | Notes |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | R$ 15 | R$ 75 | Le cache hit réduit l'input de 10x |
| GPT-5 | R$ 12 | R$ 60 | Moins cher par token |
| Gemini 3 Pro | R$ 7 | R$ 35 | Meilleur rapport coût/qualité |
| Claude Haiku 4.5 | R$ 2 | R$ 10 | Rapide, idéal pour les tâches simples |
Pour un chatbot conversationnel moyen (100 messages, ~500 tokens chacun), le coût journalier se situe entre R$ 10 et R$ 50. Pour des applications batch (analyse de 10 000 documents), il monte à R$ 500-2000.
Quand utiliser chacun
Claude Sonnet 4.6 pour :
- La rédaction de longs documents (rapports, essais, analyses juridiques)
- La revue de code et le refactoring
- L'analyse de nuances dans les textes (littérature, philosophie)
- Les tâches nécessitant de suivre des instructions complexes
- Les agents avec une longue chaîne de raisonnement
GPT-5 pour :
- Les réponses créatives ouvertes (brainstorming, scénarios)
- Le multimodal où image + texte sont importants
- Les réponses rapides et directes
- Les cas où vous voulez le « modèle le plus généraliste possible »
- Le code Python et JavaScript standard
Gemini 3 Pro pour :
- Traiter des documents volumineux (livres, bases de code entières)
- Les applications à latence critique (<1s)
- L'analyse de vidéos (multimodal vidéo natif)
- Les tâches scientifiques et mathématiques
- La production à grande échelle où le coût est un enjeu
Testez votre cas avec 3 pipelines identiques
Ne faites pas confiance aux benchmarks génériques. Créez votre propre évaluation :
1. Sélectionnez 20 exemples représentatifs de votre usage réel
2. Lancez le même prompt sur les 3 modèles
3. Évaluez les réponses en aveugle (sans savoir lequel est lequel)
4. Mesurez : précision, latence, coût
Souvent, le modèle « moins bon » sur les benchmarks génériques est le meilleur pour votre cas, car votre tâche présente des caractéristiques spécifiques que le benchmark ne capture pas.
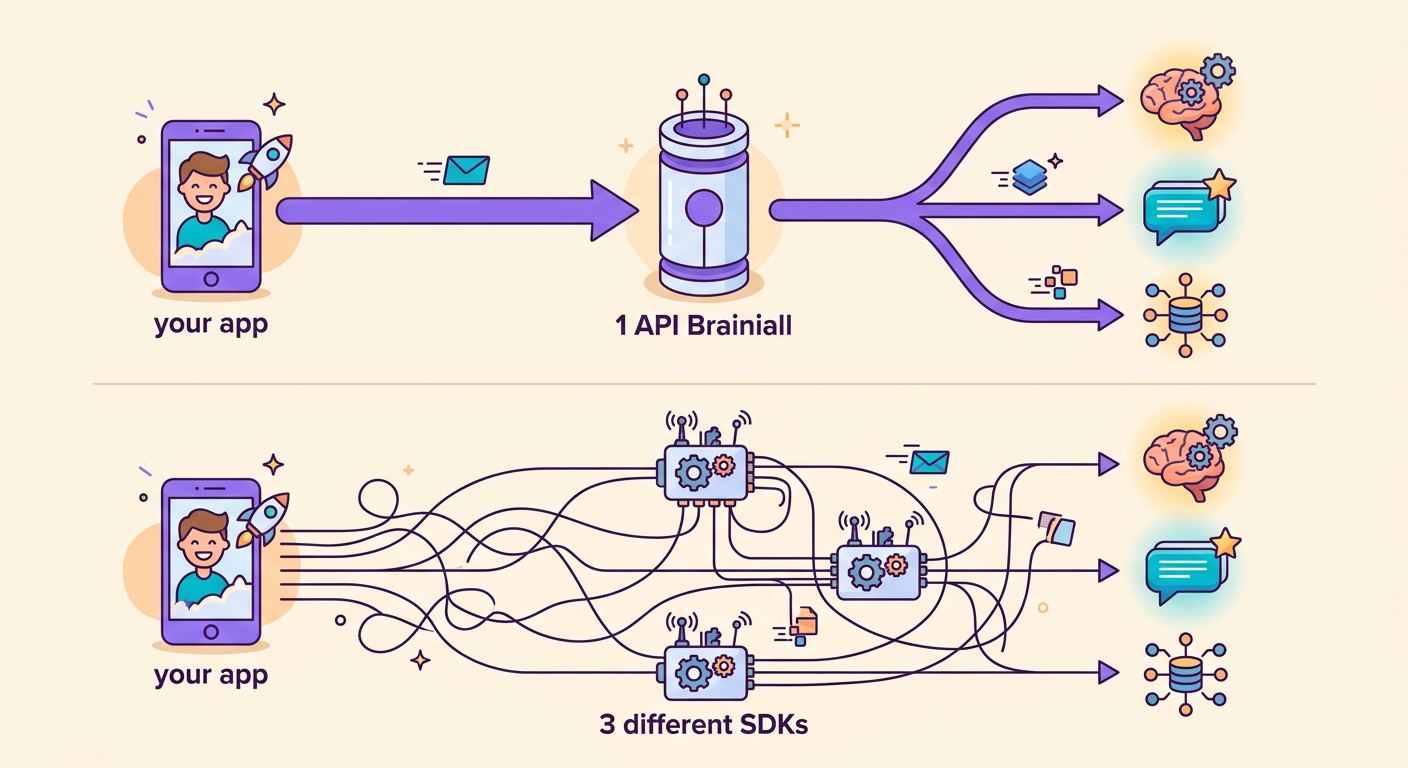
Utilisation via Brainiall
Le grand avantage de notre gateway : vous changez de modèle en modifiant 1 seule chaîne de caractères.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Explique l'entropie en 3 phrases."))`
Sans Brainiall, vous auriez besoin de 3 comptes, 3 SDKs, 3 facturations séparées. Avec un gateway unique, tout devient transparent.
Les pièges à éviter lors d'une comparaison
- Prompt non neutre : si votre prompt a été optimisé pour GPT, Claude peut sembler moins performant de façon injuste
- Un seul exemple : la variabilité entre les runs est élevée ; visez un minimum de N=20
- Mauvaise métrique : mesurer uniquement la précision ignore le coût, la latence et la robustesse
- Ignorer le cache : Claude dispose d'un cache de prompt qui réduit le coût de 10x pour les systèmes répétitifs
- Ne pas tester en français : tous sont performants en anglais ; en français, les différences sont plus marquées
Testez dès maintenant
Dans le chat Brainiall, sélectionnez un modèle dans le menu déroulant en haut et posez votre question. Passez à un autre modèle et comparez. L'offre Pro à €5,49 donne accès à 15 modèles ; l'offre Business les débloque tous.