
Détectez la langue dans des textes multilingues
Pourquoi détecter la langue automatiquement est utile
Scénarios concrets :
- Chatbot multilingue : l'utilisateur écrit "Hola, como estoy?" → détecte l'espagnol → répond en espagnol (au lieu du français défini par défaut)
- Fil d'actualité mondial : un agrégateur de news doit regrouper les articles par langue avant de les traduire
- Support : un ticket en japonais doit être acheminé vers l'équipe Japon, pas vers celle de France
- Modération : les règles de contenu sensible varient selon la région et la langue
- Analytics : mesurez la diversité linguistique de votre audience
Le modèle fastText language identification, open source de Facebook, détecte 176 langues en moins de 10 ms par texte.
Comment le modèle distingue les langues
fastText représente chaque mot sous forme de n-grams de caractères (subwords). Il additionne ensuite ces vecteurs et classifie avec une régression softmax. Pourquoi ça fonctionne :
- Le français possède des caractéristiques comme "tion", "eau", "eux"
- L'anglais a ses propres marqueurs : "th", "ing", "ed"
- L'allemand se distingue par "sch", "ch", "äöü"
- Le mandarin écrit en pinyin présente des patterns totalement différents du hanzi
Le modèle analyse la signature statistique des n-grams pour trancher. Les textes courts (< 3 mots) sont ambigus ; au-delà de 20 mots, la précision dépasse 99 %.
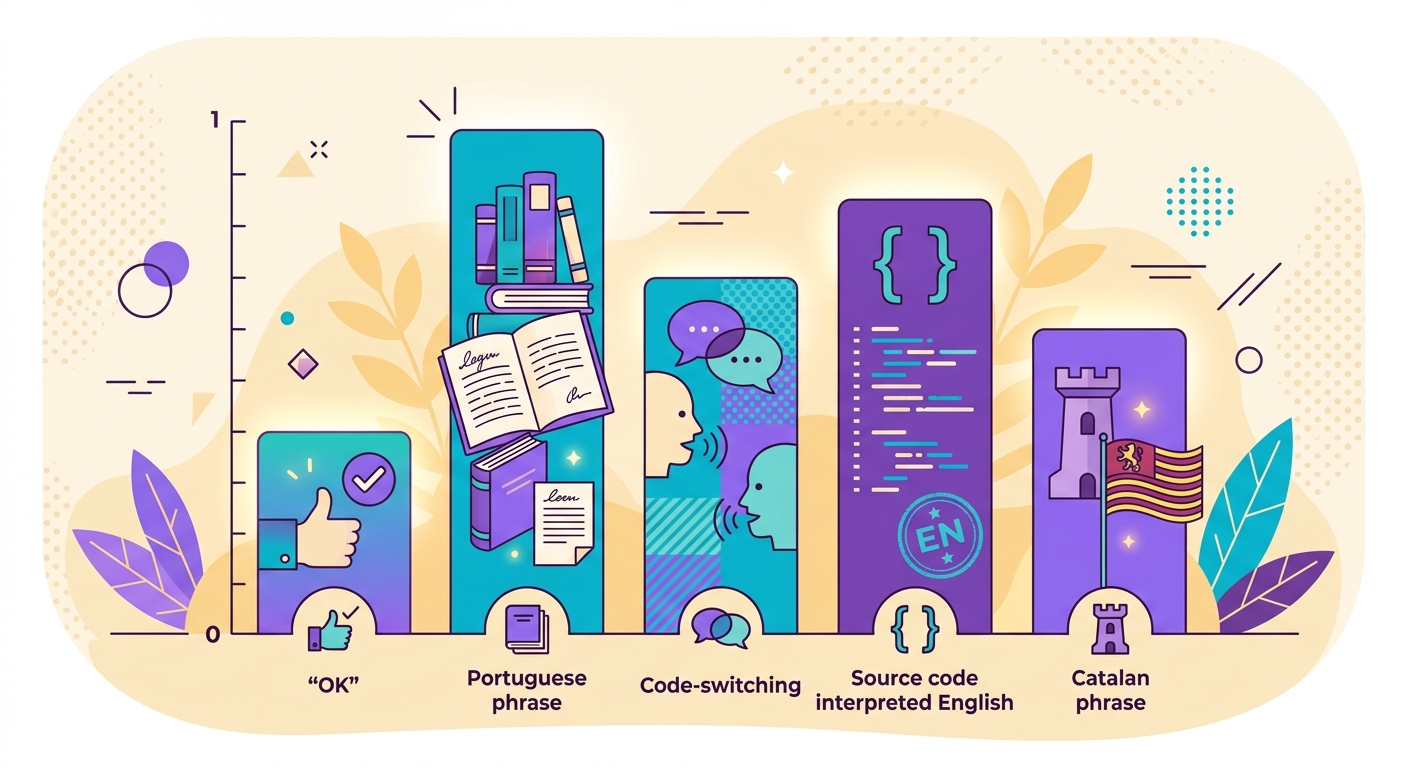
Cas difficiles et comment les gérer
- Code-switching : texte mélangeant 2 langues ("Hello, tudo bem?") — le modèle retourne la langue dominante avec un score réduit
- Langues proches : portugais vs espagnol vs catalan — fastText atteint 90 %+ de précision, mais des cas limites existent
- Translittération : chinois écrit en pinyin, arabe en caractères latins — le modèle peut les détecter à tort comme de l'"anglais"
- Textes très courts : "OK" pourrait appartenir à n'importe quelle langue — le score retourné sera toujours faible, pensez à utiliser un seuil
- Code source : le code de programmation est détecté comme de l'"anglais" — filtrez-le en amont si nécessaire
Seuil recommandé : n'acceptez une détection que si la confidence est > 0,75. En dessous, marquez comme "unknown" et faites appel à un humain.
Intégration dans votre stack
Exemple Python typique :
`python
import httpx
r = httpx.post(
"https://api.brainiall.com/api/nlp/language",
json={"text": "Hola, ¿cómo estás hoy?"},
headers={"Authorization": "Bearer brnl-xxx"}
)
# {"language": "es", "confidence": 0.96, "top_3": [
# {"lang": "es", "conf": 0.96},
# {"lang": "pt", "conf": 0.02},
# {"lang": "ca", "conf": 0.01}
# ]}`
Utilisez top_3 lorsque vous souhaitez afficher des alternatives en cas de faible confiance (ex. : "Semble être de l'espagnol, mais pourrait être du catalan — veuillez confirmer").
Cas d'usage avancés
- Pré-traitement NLP : avant une analyse de sentiment, détecter la langue et router vers le bon modèle
- Filtrage : supprimer les textes hors langue cible dans de grands datasets
- Routage du trafic : répartir la charge entre des clusters multilingues
- Segmentation : diviser des documents longs par langue lorsqu'ils sont mixtes
- Recherche : permettre à l'utilisateur de filtrer "afficher uniquement le contenu en français sur cette plateforme"
Testez dès maintenant
Demandez "détectez la langue de ce texte : [collez]" dans le chat Brainiall. API disponible sur /api/nlp/language. Latence typique < 10 ms — idéal pour une utilisation en temps réel. Le plan Pro offre une utilisation généreuse ; le plan Business inclut l'API batch.