
Détectez la toxicité dans les commentaires avec l'IA
L'apocalypse Perspective : ce qui s'est passé
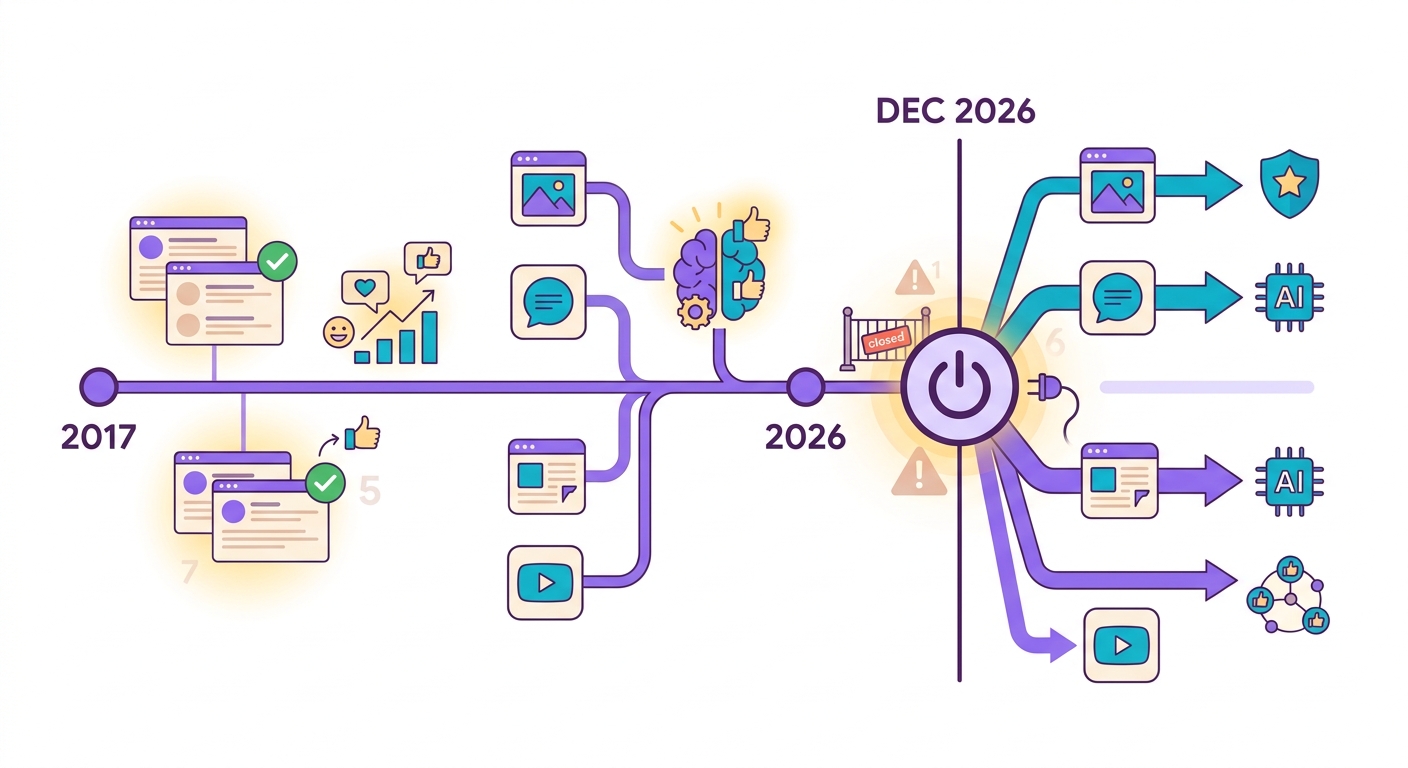
En octobre 2024, Google a annoncé que le Perspective API — le service gratuit de détection de toxicité le plus utilisé au monde — serait abandonné en décembre 2026. Les plateformes qui en dépendaient (Reddit, New York Times, The Guardian, des milliers de forums) ont 2 ans pour migrer.
Le problème : Perspective était gratuit. Les alternatives commerciales comme Azure Content Safety et AWS Comprehend facturent à partir de 1 $ pour 1 000 analyses. Pour un grand forum avec 100 000 commentaires par jour, cela représente 3 000 $/mois rien que pour la modération.
Brainiall propose une modération avec les modèles Detoxify + Unitary fonctionnant en ONNX local (CPU), pour moins de 0,001 € par analyse — 100x moins cher.
Les 7 catégories qui comptent
Detoxify classe le texte selon 7 dimensions avec un score de 0 à 1 :
1. Toxicity : insulte générale, agressivité
2. Severe toxicity : menace, haine extrême
3. Obscene : grossièretés et langage vulgaire
4. Threat : menace de violence physique
5. Insult : attaque personnelle directe
6. Identity hate : discrimination basée sur un groupe (race, genre, religion)
7. Sexual explicit : contenu sexuellement explicite
Votre politique définit les seuils. Exemple courant : bloquer si severe_toxicity > 0,5 OU identity_hate > 0,6 OU threat > 0,3. Les grossièretés isolées (obscene > 0,8) passent généralement avec un avertissement, sans blocage.
Le défi des langues locales
Detoxify a été entraîné en anglais. Il fonctionne à plus de 95 % sur les commentaires en anglais. En français et dans d'autres langues, ce taux peut descendre à 75-85 % — les régionalismes et les expressions familières spécifiques (souvent non offensantes) perturbent le modèle.
Chez Brainiall, nous utilisons une couche supplémentaire : un classificateur hybride qui combine :
- Detoxify multilingue (70 % de la décision)
- Une liste de mots spécifiques à la langue cible (20 %)
- Un LLM compact (Gemma 3 ou similaire) pour les cas limites (10 %)
Cela élève la précision à plus de 92 %, tout en maintenant une latence inférieure à 80 ms.
Quand l'IA se trompe dangereusement
- Sarcasme : "J'ai adoré la façon dont tu as ruiné ma vie, merci !" — score positif, mais le texte est hostile
- Satire légitime : les critiques politiques humoristiques peuvent être signalées comme des attaques
- Contexte médical : "je vais tuer ce patient à force de travailler" (soignant épuisé) — faux positif
- Citations : un article citant un post raciste pour le critiquer est analysé comme s'il était lui-même raciste
- Code-switching : mélanger plusieurs langues et des emojis perturbe le modèle
Solution pratique : combinez le score automatique avec une modération douce (demander confirmation avant publication) plutôt qu'un blocage immédiat pour les cas limites.
Intégration dans votre plateforme
Flux recommandé :
1. L'utilisateur saisit un commentaire → requête POST /api/toxicity avec { text }
2. L'API retourne { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Votre code décide : bloquer, avertir ou approuver
4. En cas d'avertissement, afficher "Vérifiez — ce contenu pourrait offenser certains utilisateurs" avant publication
5. Pour les blocages, journalisez et notifiez la modération humaine
N'automatisez pas la modération à 100 %. Maintenez toujours une file d'attente humaine pour les cas limites.
Testez dès maintenant
Dans le chat Brainiall, demandez "analysez la toxicité de ce commentaire : [collez ici]". Ou via API sur la route /api/nlp/toxicity. Le plan Pro à 29 € inclut 10 000 analyses par mois ; le plan Business offre une file prioritaire et le traitement par lots de millions de requêtes.