
GPT-5 vs Claude Sonnet vs Gemini 3 Pro: qual escolher?
A escolha do modelo importa mais que você pensa
Em 2026, a diferença entre modelos top-tier é notável em tarefas específicas. Esquecer de testar 2-3 opções e ir direto com o mais famoso (GPT) pode custar 2-3x mais em tokens ou trazer resultado 20% pior em seu caso específico.
Os 3 modelos dominantes na Brainiall:
- Claude Sonnet 4.6 (Anthropic): melhor para raciocínio complexo, escrita longa, código
- GPT-5 (OpenAI): melhor para multimodal (imagem+texto+código), criatividade
- Gemini 3 Pro (Google): melhor para contextos gigantes (1M+ tokens), latência baixa
Custos reais em 2026 (por milhão de tokens)
| Modelo | Input | Output | Notas |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | R$ 15 | R$ 75 | Cache hit reduz input 10x |
| GPT-5 | R$ 12 | R$ 60 | Mais barato por token |
| Gemini 3 Pro | R$ 7 | R$ 35 | Melhor custo/quality |
| Claude Haiku 4.5 | R$ 2 | R$ 10 | Rápido, bom pra tasks simples |
Para um chatbot conversacional médio (100 mensagens, ~500 tokens cada), o custo diário fica em R$ 10-50. Para aplicações batch (análise de 10k documentos), sobe para R$ 500-2000.
Quando usar cada um
Claude Sonnet 4.6 para:
- Redação de documentos longos (relatórios, ensaios, análises jurídicas)
- Code review e refactoring
- Análise de nuance em textos (literatura, filosofia)
- Tarefas que exigem seguir instruções complexas
- Agentes com cadeia longa de raciocínio
GPT-5 para:
- Respostas criativas abertas (brainstorming, roteiros)
- Multimodal onde imagem + texto são importantes
- Respostas rápidas e diretas
- Casos onde você quer o "modelo mais genérico possível"
- Código Python e JavaScript padrão
Gemini 3 Pro para:
- Processar documentos enormes (livros, bases de código inteiras)
- Aplicações com latência crítica (<1s)
- Análise de vídeos (nativo multimodal de vídeo)
- Tarefas científicas e matemáticas
- Produção em escala onde custo importa
🎧 Ouça a narração completa (vídeo demo em produção)
Teste seu caso com 3 pipelines idênticos
Não confie em benchmarks genéricos. Crie seu próprio eval:
1. Selecione 20 exemplos representativos do seu uso real
2. Rode o mesmo prompt nos 3 modelos
3. Avalie respostas cegas (sem saber qual é qual)
4. Meça: accuracy, latência, custo
Muitas vezes o modelo "pior" em benchmarks genéricos é o melhor para seu caso porque sua tarefa tem características específicas que o benchmark não captura.
Usando via Brainiall
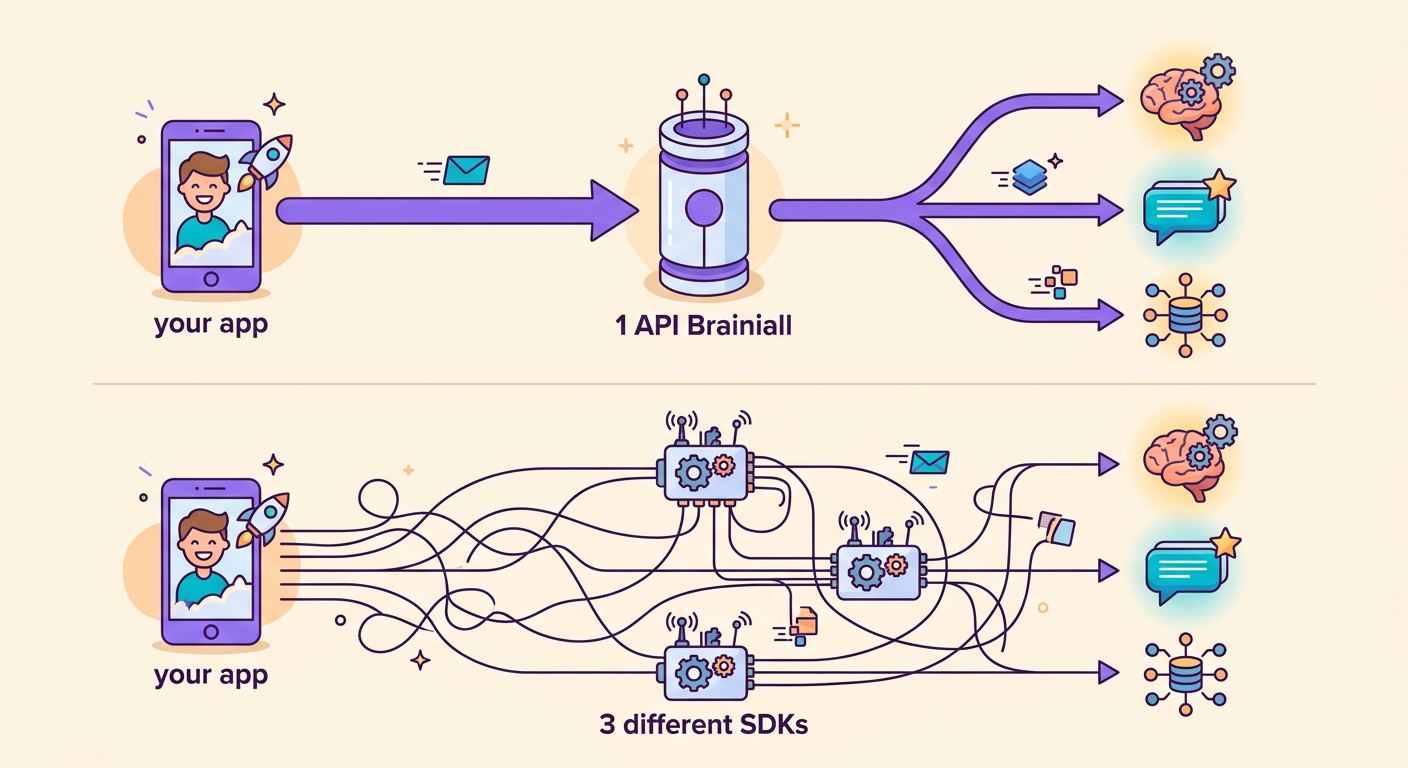
A grande vantagem do nosso gateway: você troca de modelo mudando 1 string.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Explique entropia em 3 frases."))`
Sem Brainiall, você precisaria de 3 contas, 3 SDKs, 3 billings separados. Com gateway único, é transparente.
Armadilhas ao comparar
- Prompt não neutro: se seu prompt foi otimizado para GPT, Claude pode parecer pior injustamente
- Um exemplo só: variabilidade entre runs é alta; faça N=20+ mínimo
- Métrica errada: medir só accuracy ignora custo/latência/robustez
- Ignorar cache: Claude tem cache de prompt que reduz custo 10x para sistemas repetidos
- Não testar em PT-BR: todos são bons em inglês; em PT-BR a diferença é maior
Teste agora mesmo
No chat Brainiall selecione um modelo no dropdown superior e faça sua pergunta. Troque para outro modelo e compare. Pro R$29 dá acesso a 15 modelos; Business desbloqueia todos.