
Construa seu primeiro agente de IA com memória
Agente vs chatbot: qual a diferença
Um chatbot responde mensagens independentemente. Cada conversa é isolada. Se você disse seu nome ontem, ele não sabe hoje.
Um agente tem 3 características extras:
1. Memória persistente: lembra de você entre sessões
2. Ferramentas: pode chamar APIs externas (buscar no Google, enviar email, executar código)
3. Planejamento: pode decompor tarefa complexa em passos
Neste curso vamos focar em (1): memória persistente. Ferramentas e planejamento são cursos separados.

Arquitetura básica de memória
O que o agente precisa guardar sobre você:
- Fatos declarativos: "Pedro trabalha com Python", "gosta de café sem açúcar", "mora em São Paulo"
- Preferências: "responda em pt-BR formal", "explicações breves, sem floreio"
- Histórico de interações: resumo dos últimos N diálogos
- Contexto efêmero: o que você está fazendo AGORA (apagado após sessão)
Padrão de armazenamento:
`
memoria_usuario = {
"facts": [
{"text": "Pedro trabalha com Python", "pinned": False},
{"text": "prefere respostas curtas", "pinned": True}
],
"summary_last_10_sessions": "Usuário aprendeu sobre TLS, APIs e autenticação...",
"preferences": {"response_language": "pt-BR", "tone": "technical"}
}`
Como a Brainiall faz isso
Nosso backend já implementa memória persistente. Você pode ver:
1. Clicar no ícone 🧠 na sidebar do chat
2. Ver lista de fatos que a IA aprendeu sobre você
3. Pinar fatos importantes (nunca esquecer)
4. Editar ou excluir
5. Desabilitar memória via toggle
Internamente usamos:
- PostgreSQL JSONB para armazenar fatos por usuário
- Eviction policy: máximo 50 fatos não-pinados, mais antigos saem primeiro
- Extraction: a cada 10 mensagens, LLM lê a conversa e sugere fatos novos para aprovação
- Retrieval: antes de responder, busca fatos relevantes e injeta no prompt
🎧 Ouça a narração completa (vídeo demo em produção)
Construindo seu agente via API
Exemplo minimalista Python:
`python
import httpx
BASE = "https://api.brainiall.com"
KEY = "brnl-xxxxx"
def chat(message, user_memory):
# Inject memory as system prompt context
memory_text = "\n".join(f"- {f}" for f in user_memory["facts"])
system = f"Você é um assistente pessoal. Sobre o usuário:\n{memory_text}"
r = httpx.post(
f"{BASE}/v1/chat/completions",
json={
"model": "claude-sonnet-4-6",
"messages": [
{"role": "system", "content": system},
{"role": "user", "content": message}
]
},
headers={"Authorization": f"Bearer {KEY}"}
)
return r.json()["choices"][0]["message"]["content"]
# Uso
memory = {"facts": ["Pedro trabalha com Python", "gosta de café sem açúcar"]}
print(chat("Que que bebi hoje de manhã?", memory))
# → "Você provavelmente bebeu um café sem açúcar, certo?"`
Este é um agente básico. Adicionar extraction automática (LLM lê e extrai fatos novos) e retrieval (só injetar fatos relevantes) deixaria o código em ~100 linhas.
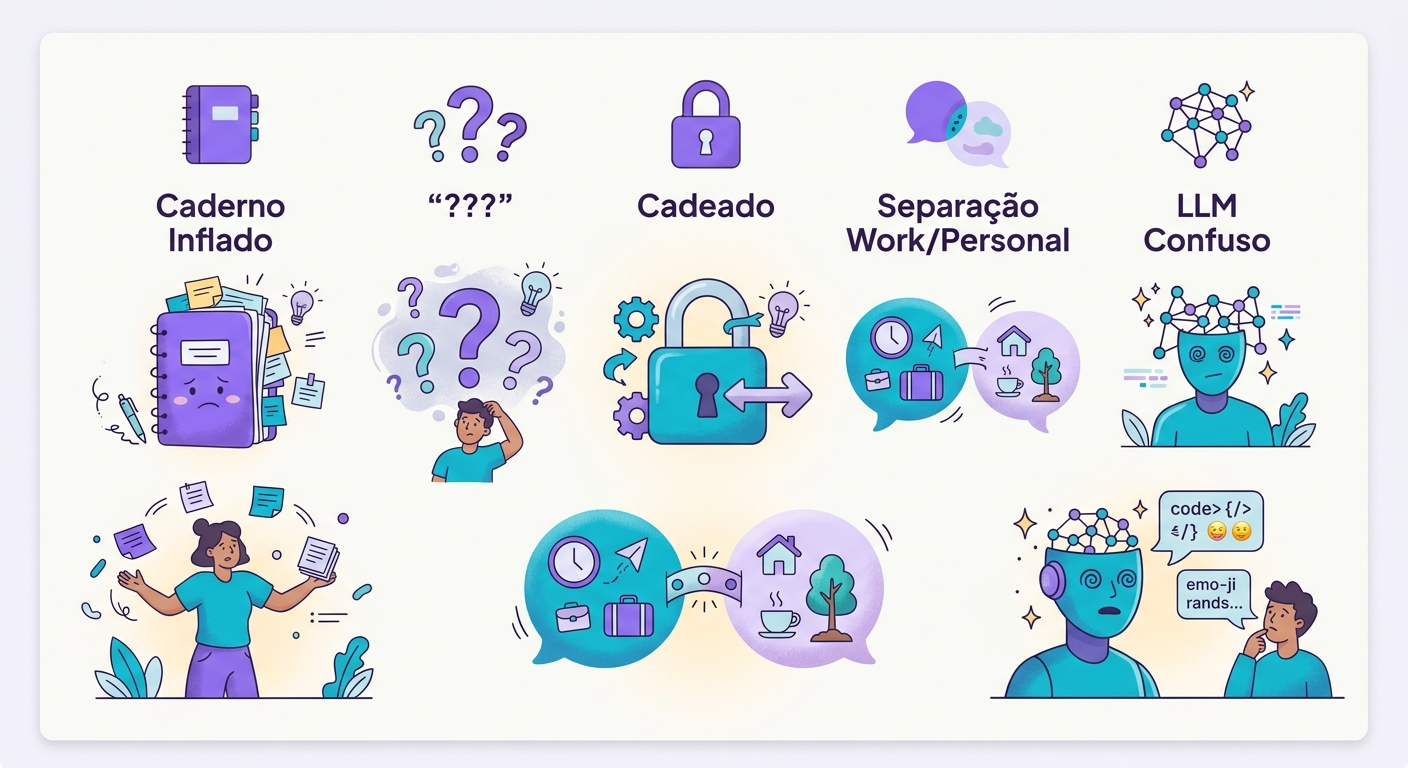
Armadilhas comuns
- Memória inflacionada: sem eviction, a memória cresce até quebrar token limit
- Fatos contraditórios: "Pedro gosta de café" + "Pedro parou de beber café" — qual prevalece?
- Privacidade: user deve sempre poder ver + editar + deletar
- Escopo errado: memórias de work não devem vazar para chats pessoais
- Drift: LLM pode inventar fatos falsos se o prompt é ambíguo; sempre valide antes de persistir
Casos de uso
- Tutor personalizado: lembra quais tópicos você domina ou tem dificuldade
- Nutricionista virtual: histórico de refeições, preferências, restrições
- Coach de carreira: lembra de objetivos, conquistas recentes, pontos de melhoria
- Assistente de escrita: seu estilo, tom preferido, temas recorrentes
- Suporte técnico interno: lembra de tickets anteriores, sistemas que você usa
Teste agora mesmo
No chat Brainiall, abra uma conversa, conte algo sobre você, feche, abra outra conversa no dia seguinte — o agente lembra. Habilite/desabilite via ícone 🧠 na sidebar. Pro R$29 tem memória completa; free tem memória limitada a 10 fatos.