
Detecte toxicidade em comentários com IA
O apocalipse Perspective: o que aconteceu
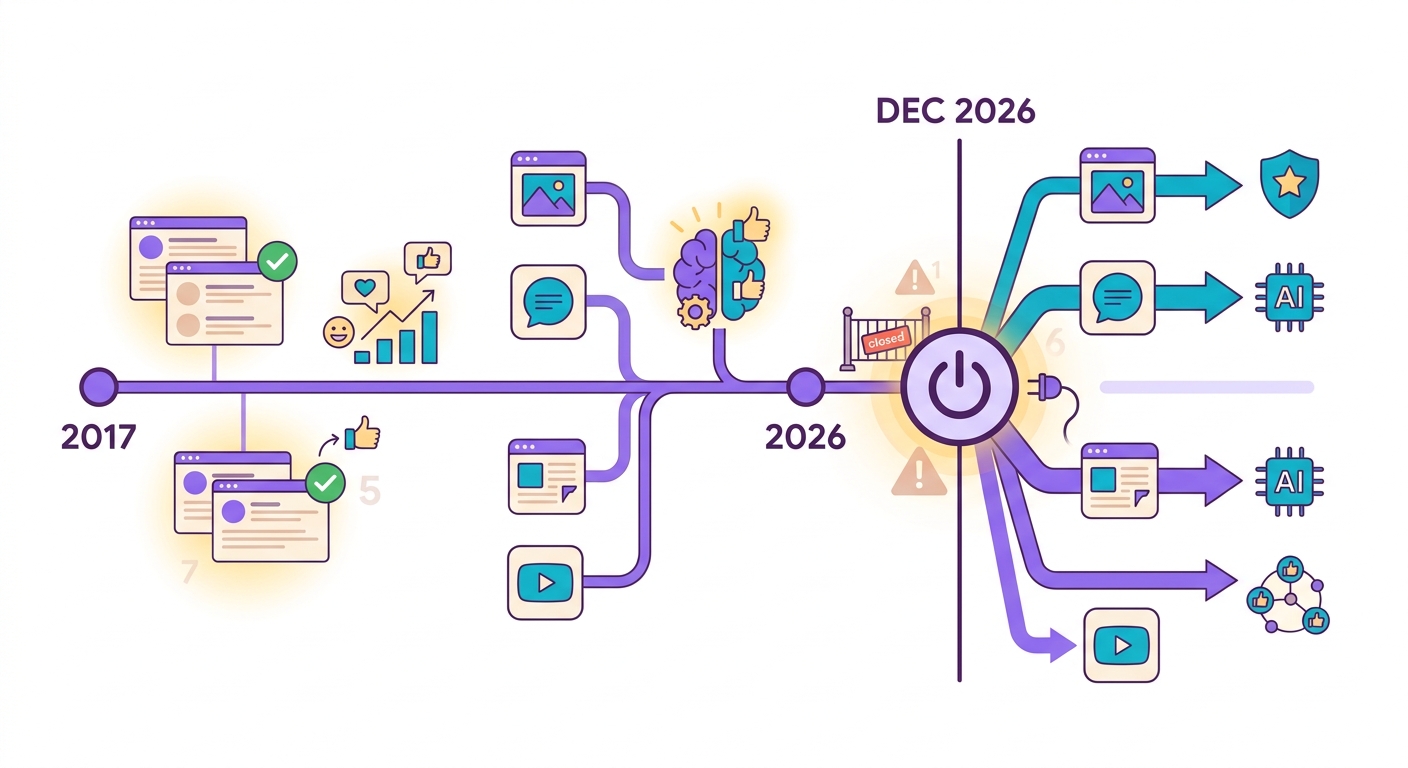
Em outubro de 2024, o Google anunciou que o Perspective API — o serviço gratuito de detecção de toxicidade mais usado no mundo — seria descontinuado em dezembro de 2026. Plataformas que dependiam dele (Reddit, New York Times, The Guardian, milhares de fóruns) têm 2 anos para migrar.
O problema: Perspective era gratuito. Alternativas comerciais como Azure Content Safety e AWS Comprehend cobram a partir de US$ 1 por 1.000 análises. Para um fórum grande com 100k comentários/dia, isso vira $3k/mês só em moderação.
A Brainiall oferece moderação com modelos Detoxify + Unitary rodando em ONNX local (CPU), custando menos de R$ 0,001 por análise — 100x mais barato.
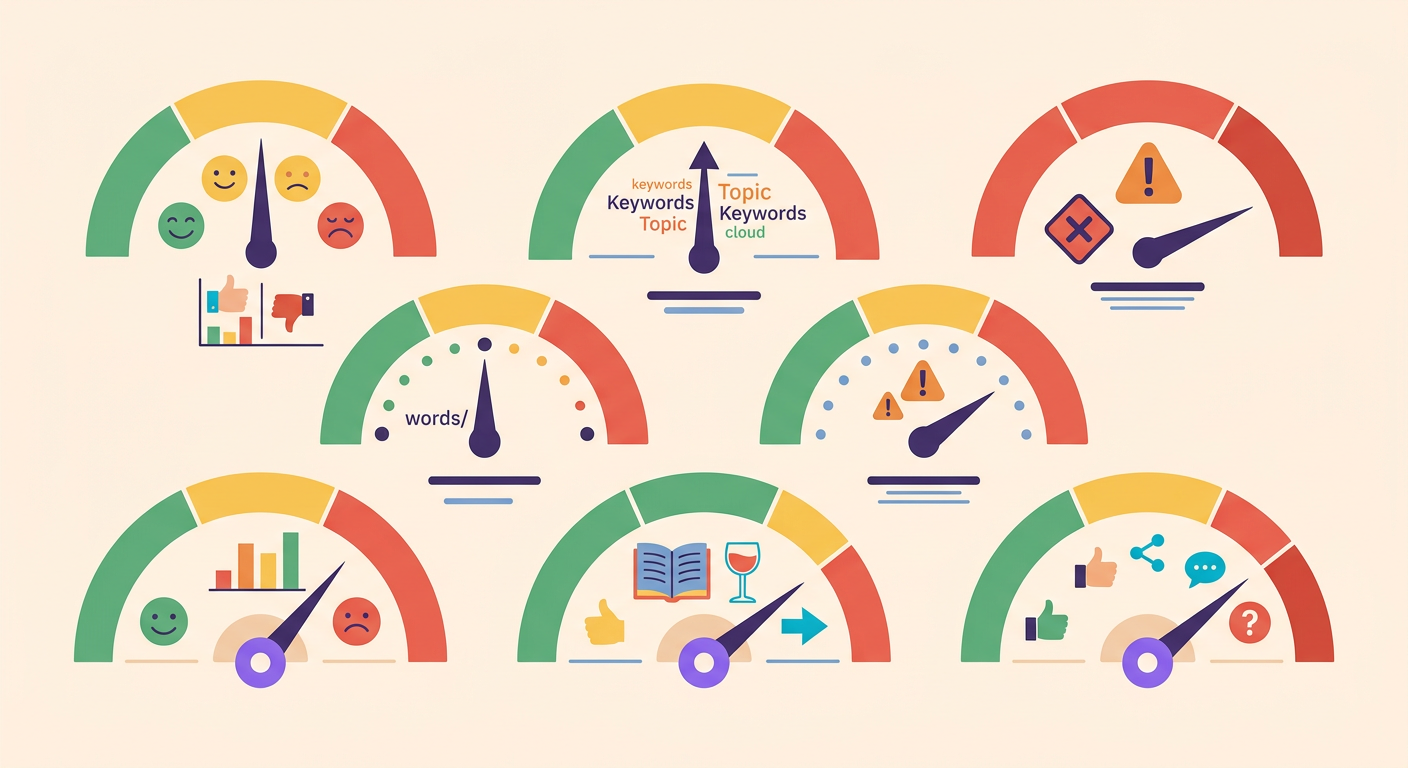
As 7 categorias que importam
Detoxify classifica texto em 7 dimensões com score de 0 a 1:
1. Toxicity: insulto geral, agressividade
2. Severe toxicity: ameaça, ódio extremo
3. Obscene: palavrões e linguagem chula
4. Threat: ameaça de violência física
5. Insult: ataque pessoal direto
6. Identity hate: discriminação baseada em grupo (raça, gênero, religião)
7. Sexual explicit: conteúdo sexualmente explícito
Seu policy decide os thresholds. Exemplo comum: bloquear se severe_toxicity > 0.5 OU identity_hate > 0.6 OU threat > 0.3. Palavrões isolados (obscene > 0.8) geralmente passam com warning, não bloqueio.
O problema de PT-BR
Detoxify foi treinado em inglês. Funciona 95%+ em comentários em inglês. Em português brasileiro, cai para 75-85% — os regionalismos e gírias específicas (muitas não ofensivas) confundem o modelo.
Na Brainiall usamos uma camada adicional: um classificador híbrido que combina:
- Detoxify multilingual (70% da decisão)
- Lista de palavras PT-BR específicas (20%)
- LLM small (Gemma 3 ou similar) para borderline cases (10%)
Isso eleva a precisão para 92%+ em PT-BR, mantendo latência < 80ms.
Quando a IA erra perigosamente
- Sarcasmo: "Adorei como você arruinou minha vida, obrigado!" — positive score, mas texto é hostil
- Sátira legítima: críticas políticas humorísticas podem ser marcadas como ataque
- Contexto médico: "vou matar o paciente de tanto trabalhar" (trabalhador de saúde exausto) — flag falso positivo
- Citações: um artigo citando um post racista para criticá-lo é analisado como o racista
- Code-switching: quem mistura inglês + português + emojis confunde o modelo
Solução prática: combine o score automático com soft-moderation (pedir confirmação antes de publicar) em vez de hard-block para borderline cases.
🎧 Ouça a narração completa (vídeo demo em produção)
Integrando na sua plataforma
Fluxo recomendado:
1. Usuário digita comentário → fetch POST /api/toxicity com { text }
2. API retorna { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Seu código decide: bloquear, warn, ou aprovar
4. Se warn, mostra "Revise — pode ofender alguns usuários" antes de publicar
5. Para bloqueios, log + notifica moderação humana
Não faça moderação 100% automática. Sempre mantenha uma fila humana para os casos borderline.
Teste agora mesmo
No chat Brainiall, peça "analise a toxicidade deste comentário: [cole aqui]". Ou via API na rota /api/nlp/toxicity. Plano Pro R$29 inclui 10.000 análises/mês; Business tem fila priority + batch de milhões.