
GPT-5 vs Claude Sonnet vs Gemini 3 Pro: mana yang harus dipilih?
Pilihan model lebih penting dari yang kamu kira
Di tahun 2026, perbedaan antar model top-tier sangat terasa pada tugas-tugas tertentu. Langsung memakai yang paling terkenal (GPT) tanpa mencoba 2-3 opsi lain bisa menghabiskan biaya 2-3x lebih banyak dalam token, atau menghasilkan output 20% lebih buruk untuk kasus spesifikmu.
3 model dominan di Brainiall:
- Claude Sonnet 4.6 (Anthropic): terbaik untuk penalaran kompleks, penulisan panjang, dan kode
- GPT-5 (OpenAI): terbaik untuk multimodal (gambar+teks+kode) dan kreativitas
- Gemini 3 Pro (Google): terbaik untuk konteks sangat besar (1M+ token) dan latensi rendah
Biaya nyata di 2026 (per juta token)
| Model | Input | Output | Catatan |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | R$ 15 | R$ 75 | Cache hit mengurangi input 10x |
| GPT-5 | R$ 12 | R$ 60 | Lebih murah per token |
| Gemini 3 Pro | R$ 7 | R$ 35 | Terbaik dalam rasio biaya/kualitas |
| Claude Haiku 4.5 | R$ 2 | R$ 10 | Cepat, cocok untuk tugas sederhana |
Untuk chatbot percakapan rata-rata (100 pesan, ~500 token masing-masing), biaya harian berkisar R$ 10-50. Untuk aplikasi batch (analisis 10 ribu dokumen), bisa naik hingga R$ 500-2000.
Kapan menggunakan masing-masing model
Claude Sonnet 4.6 untuk:
- Penulisan dokumen panjang (laporan, esai, analisis hukum)
- Code review dan refactoring
- Analisis nuansa dalam teks (sastra, filsafat)
- Tugas yang membutuhkan mengikuti instruksi kompleks
- Agen dengan rantai penalaran yang panjang
GPT-5 untuk:
- Respons kreatif terbuka (brainstorming, skrip)
- Multimodal di mana gambar + teks sama-sama penting
- Respons yang cepat dan langsung ke poin
- Kasus di mana kamu ingin "model paling serbaguna"
- Kode Python dan JavaScript standar
Gemini 3 Pro untuk:
- Memproses dokumen sangat besar (buku, seluruh basis kode)
- Aplikasi dengan latensi kritis (<1 detik)
- Analisis video (multimodal video secara native)
- Tugas ilmiah dan matematis
- Produksi skala besar di mana biaya sangat diperhitungkan
Uji kasusmu dengan 3 pipeline yang identik
Jangan percaya begitu saja pada benchmark generik. Buat evaluasimu sendiri:
1. Pilih 20 contoh yang representatif dari penggunaan nyatamu
2. Jalankan prompt yang sama pada ketiga model
3. Nilai respons secara buta (tanpa tahu model mana yang mana)
4. Ukur: akurasi, latensi, biaya
Seringkali model yang "lebih buruk" di benchmark generik justru menjadi yang terbaik untuk kasusmu, karena tugasmu memiliki karakteristik spesifik yang tidak tertangkap oleh benchmark tersebut.
Menggunakan melalui Brainiall
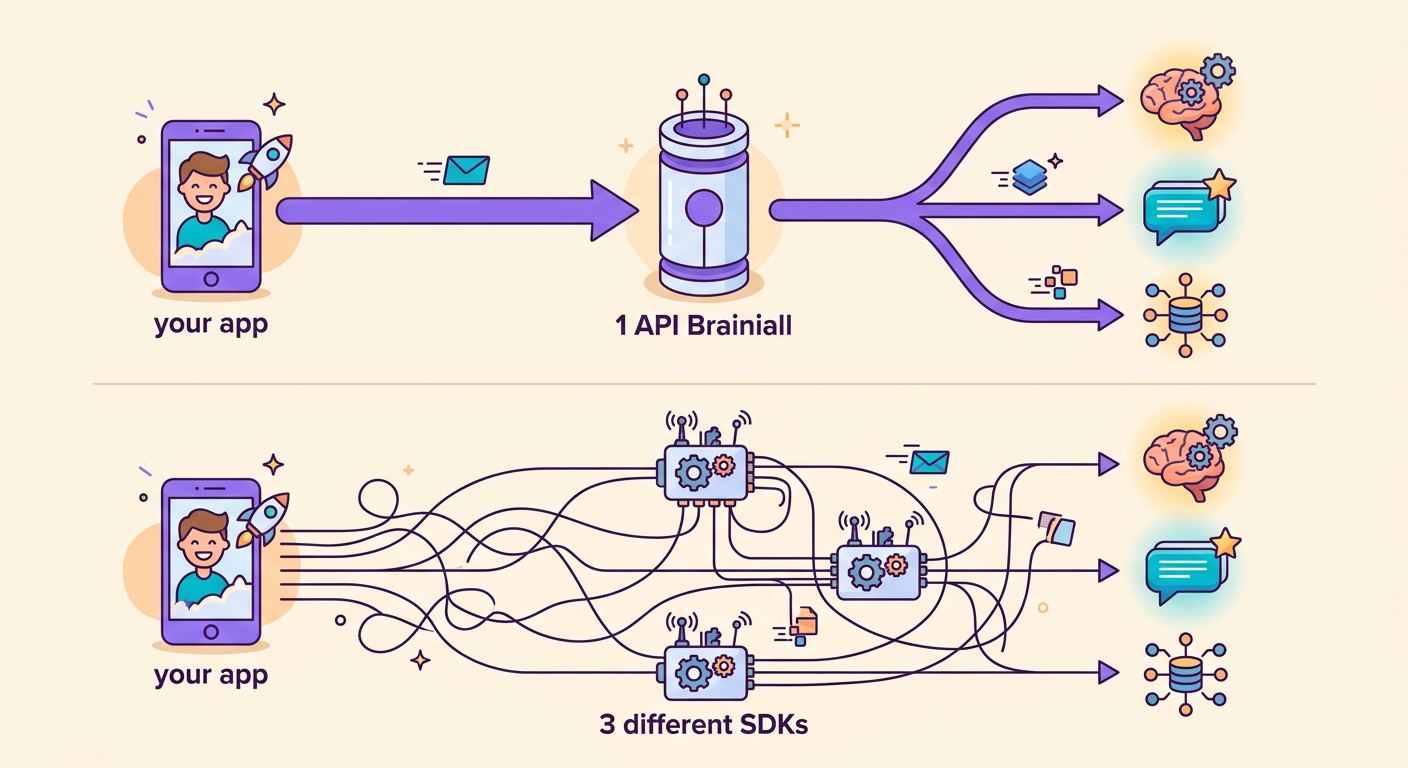
Keunggulan besar gateway kami: kamu bisa ganti model hanya dengan mengubah 1 string.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Jelaskan entropi dalam 3 kalimat."))`
Tanpa Brainiall, kamu butuh 3 akun, 3 SDK, dan 3 tagihan terpisah. Dengan gateway tunggal, semuanya jadi transparan dan mudah.
Jebakan saat membandingkan model
- Prompt yang tidak netral: jika promptmu dioptimalkan untuk GPT, Claude bisa terlihat lebih buruk secara tidak adil
- Hanya satu contoh: variabilitas antar percobaan cukup tinggi; lakukan minimal N=20+
- Metrik yang salah: hanya mengukur akurasi mengabaikan biaya, latensi, dan ketahanan
- Mengabaikan cache: Claude memiliki cache prompt yang mengurangi biaya 10x untuk sistem yang berulang
- Tidak diuji dalam Bahasa Indonesia: semua model bagus dalam bahasa Inggris; dalam Bahasa Indonesia perbedaannya lebih besar
Coba sekarang juga
Di chat Brainiall, pilih model dari dropdown di bagian atas lalu ajukan pertanyaanmu. Ganti ke model lain dan bandingkan hasilnya. Paket Pro seharga Rp 49rb memberi akses ke 15 model; paket Business membuka semua model yang tersedia.