
Deteksi toksisitas dalam komentar dengan AI
Kiamat Perspective: apa yang terjadi
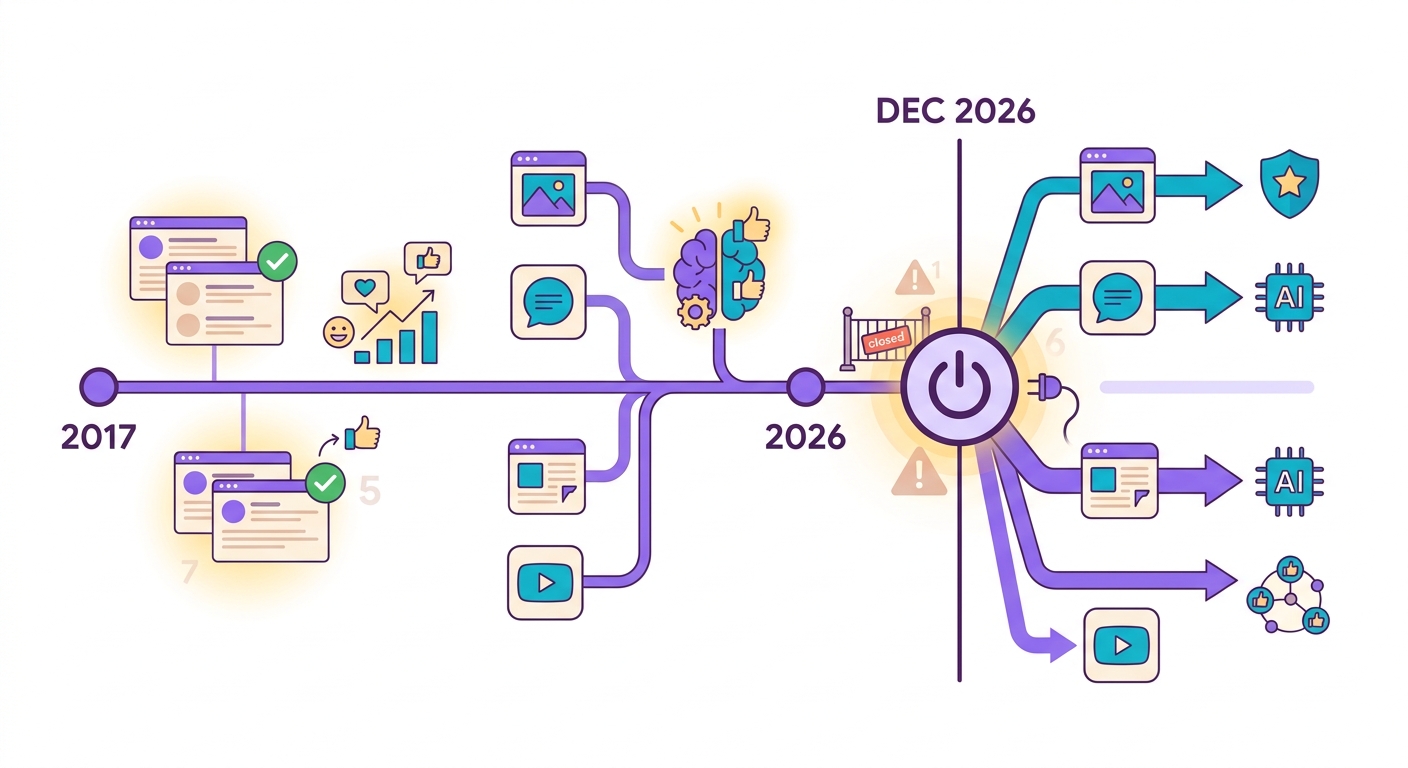
Pada Oktober 2024, Google mengumumkan bahwa Perspective API — layanan deteksi toksisitas gratis yang paling banyak digunakan di dunia — akan dihentikan pada Desember 2026. Platform yang bergantung padanya (Reddit, New York Times, The Guardian, ribuan forum) memiliki waktu 2 tahun untuk bermigrasi.
Masalahnya: Perspective itu gratis. Alternatif komersial seperti Azure Content Safety dan AWS Comprehend mengenakan biaya mulai dari US$ 1 per 1.000 analisis. Untuk forum besar dengan 100 ribu komentar per hari, itu bisa menjadi $3 ribu per bulan hanya untuk moderasi.
Brainiall menawarkan moderasi dengan model Detoxify + Unitary yang berjalan di ONNX lokal (CPU), dengan biaya kurang dari Rp 0,001 per analisis — 100x lebih murah.
7 kategori yang penting
Detoxify mengklasifikasikan teks dalam 7 dimensi dengan skor 0 hingga 1:
1. Toxicity: penghinaan umum, agresivitas
2. Severe toxicity: ancaman, kebencian ekstrem
3. Obscene: kata-kata kotor dan bahasa vulgar
4. Threat: ancaman kekerasan fisik
5. Insult: serangan personal langsung
6. Identity hate: diskriminasi berbasis kelompok (ras, gender, agama)
7. Sexual explicit: konten yang bersifat seksual eksplisit
Kebijakan Anda menentukan threshold-nya. Contoh umum: blokir jika severe_toxicity > 0,5 ATAU identity_hate > 0,6 ATAU threat > 0,3. Kata-kata kotor yang berdiri sendiri (obscene > 0,8) biasanya lolos dengan peringatan, bukan pemblokiran.
Tantangan bahasa Indonesia
Detoxify dilatih dalam bahasa Inggris. Performanya mencapai 95%+ untuk komentar berbahasa Inggris. Dalam bahasa Indonesia, akurasinya turun ke 75-85% — regionalisme dan slang spesifik (banyak yang tidak ofensif) membingungkan model.
Di Brainiall, kami menggunakan lapisan tambahan: sebuah klasifier hibrida yang menggabungkan:
- Detoxify multilingual (70% dari keputusan)
- Daftar kata spesifik bahasa Indonesia (20%)
- LLM small (Gemma 3 atau sejenisnya) untuk kasus borderline (10%)
Ini meningkatkan akurasi hingga 92%+ dalam bahasa Indonesia, dengan tetap menjaga latensi < 80ms.
Ketika AI membuat kesalahan berbahaya
- Sarkasme: "Senang sekali kamu sudah merusak hidupku, terima kasih!" — skor positif, padahal teksnya bersifat bermusuhan
- Satire yang sah: kritik politik yang humoris bisa ditandai sebagai serangan
- Konteks medis: "saya akan membunuh pasien ini karena terlalu banyak kerja" (tenaga kesehatan yang kelelahan) — false positive
- Kutipan: sebuah artikel yang mengutip postingan rasis untuk mengkritiknya dianalisis seolah-olah itu adalah konten rasis itu sendiri
- Code-switching: pengguna yang mencampur bahasa Inggris + Indonesia + emoji membingungkan model
Solusi praktis: gabungkan skor otomatis dengan soft-moderation (meminta konfirmasi sebelum publikasi) alih-alih hard-block untuk kasus borderline.
Integrasikan ke platform Anda
Alur yang direkomendasikan:
1. Pengguna mengetik komentar → fetch POST /api/toxicity dengan { text }
2. API mengembalikan { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Kode Anda memutuskan: blokir, beri peringatan, atau setujui
4. Jika peringatan, tampilkan "Tinjau kembali — mungkin menyinggung sebagian pengguna" sebelum publikasi
5. Untuk pemblokiran, catat log + notifikasi ke tim moderasi manusia
Jangan lakukan moderasi 100% otomatis. Selalu pertahankan antrean manusia untuk kasus-kasus borderline.
Coba sekarang juga
Di chat Brainiall, ketik "analisis toksisitas komentar ini: [tempel di sini]". Atau melalui API di rute /api/nlp/toxicity. Paket Pro Rp29 sudah mencakup 10.000 analisis per bulan; paket Business memiliki antrean prioritas + batch jutaan analisis.