
Narasikan teks apa pun dalam 9 bahasa dengan 54 suara neural
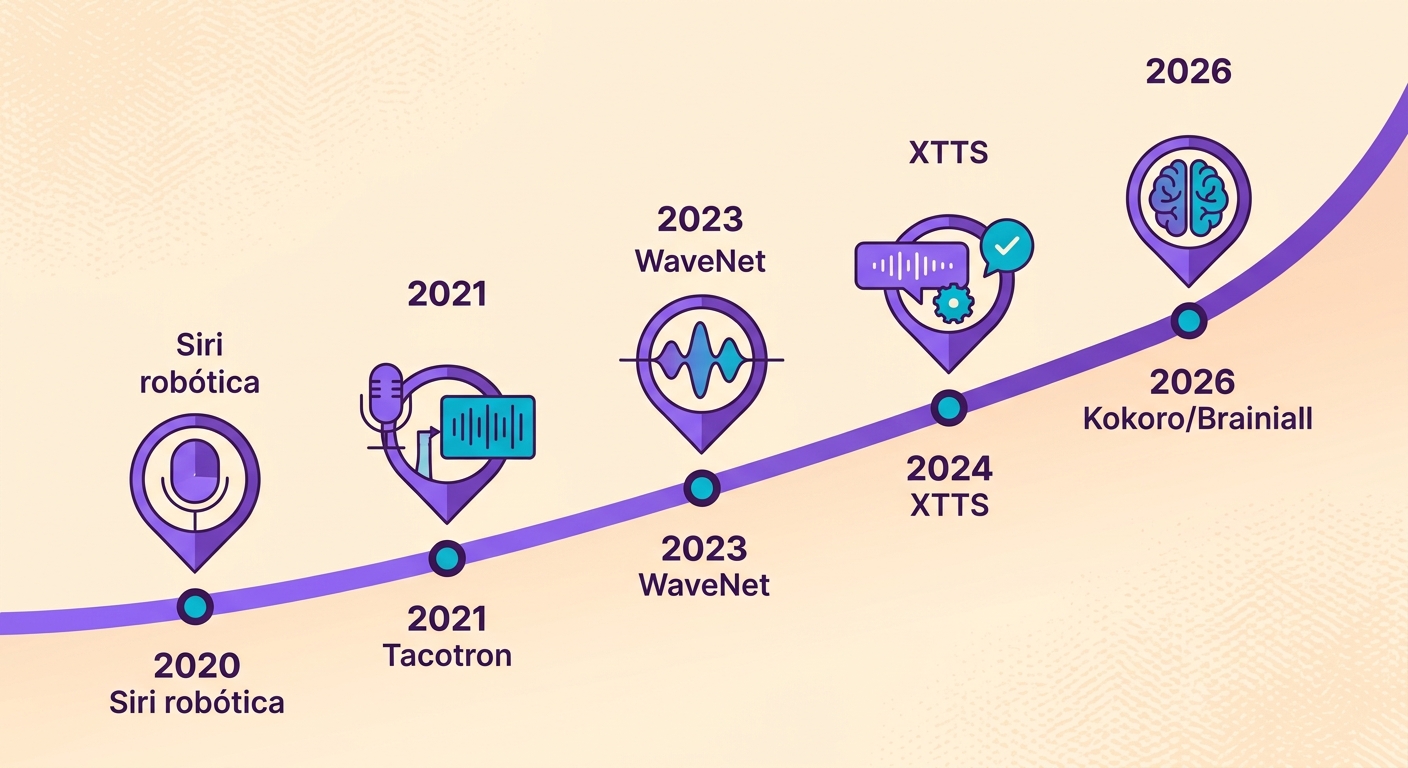
Evolusi TTS dalam 5 tahun
Hingga 2020, Text-to-Speech terdengar robotik — era Siri generasi pertama. Dari 2021 hingga 2023, kita mulai menggunakan model WaveNet dan Tacotron untuk menghasilkan suara yang lebih natural. Mulai 2024, model-model berskala baru (XTTS, Kokoro, VALL-E) membawa tiga terobosan penting:
1. Ukuran kecil: Kokoro hanya memiliki 82 juta parameter — 100× lebih kecil dari model-model raksasa sebelumnya, namun dengan kualitas yang setara
2. Inferensi real-time: RTF (Real-Time Factor) < 0.2 pada GPU entry-level; artinya, 1 menit audio disintesis dalam waktu kurang dari 12 detik
3. Prosodi natural: intonasi, penekanan, ritme — tidak lagi terdengar "monoton dengan jeda"
9 bahasa yang didukung Brainiall
- Portugis Brasil: pf_dora (wanita dewasa), pm_alex, pm_santa (pria)
- Inggris Amerika: af_heart, af_bella, af_nicole, am_adam, am_michael
- Inggris Britania: bf_emma, bm_george, bm_lewis
- Spanyol: ef_lucia, em_carlos
- Prancis: ff_juliette, fm_louis
- Jerman: gf_sophia, gm_max
- Italia: if_chiara, im_marco
- Mandarin: zf_mei, zm_wei
- Jepang: jf_haruka, jm_kenji
Setiap suara memiliki karakternya sendiri: pf_dora terdengar jelas dan edukatif (kami gunakan di kursus Brainiall Academy), am_adam cocok untuk suasana korporat profesional, sementara af_heart memiliki nada yang lebih emosional.
Cara memilih suara yang tepat sesuai konteks
- E-learning / tutorial: suara netral dan artikulatif (pf_dora, am_adam)
- Marketing / iklan: suara dinamis dan ekspresif (af_heart, am_michael)
- Audiobook: suara hangat dan naratif (af_bella, bm_george)
- Berita: suara formal dan jelas (pm_santa, am_adam)
- Chatbot / asisten: suara ramah dan responsif (af_nicole, pm_alex)
Tips praktis: hasilkan 3-5 detik uji coba dengan 3 suara kandidat sebelum mensintesis teks panjang. Preferensi selalu bersifat subjektif.
Mengatur kecepatan dan nada suara
Parameter yang paling berguna:
- speed: 0.25 hingga 4.0 — default 1.0. Gunakan 0.85 untuk audiobook (narasi tenang), 1.15 untuk konten edukatif, 1.3+ hanya untuk pratinjau cepat
- format: mp3, wav, ogg. MP3 adalah default (kompresi terbaik); WAV untuk keperluan pengeditan audio; OGG untuk streaming web
- pitch: beberapa model mendukung pengaturan ini, sesuaikan dalam satuan semitone (-5 hingga +5)
Hindari nilai ekstrem: speed > 2.0 akan sulit dipahami, sedangkan < 0.5 terdengar tidak natural.
Batasan teknis dan penggunaan
- Maksimum per request: 4000 karakter — sekitar 4 paragraf. Teks panjang memerlukan chunking
- Bahasa campuran: setiap suara paling optimal pada bahasa utamanya; mencampur bahasa (misalnya teks PT dengan kata-kata bahasa Inggris) dapat menghasilkan pengucapan yang kurang tepat
- Nama asing: tuliskan secara fonetis dalam prompt — misalnya "Maicrosoft" sebagai ganti "Microsoft"
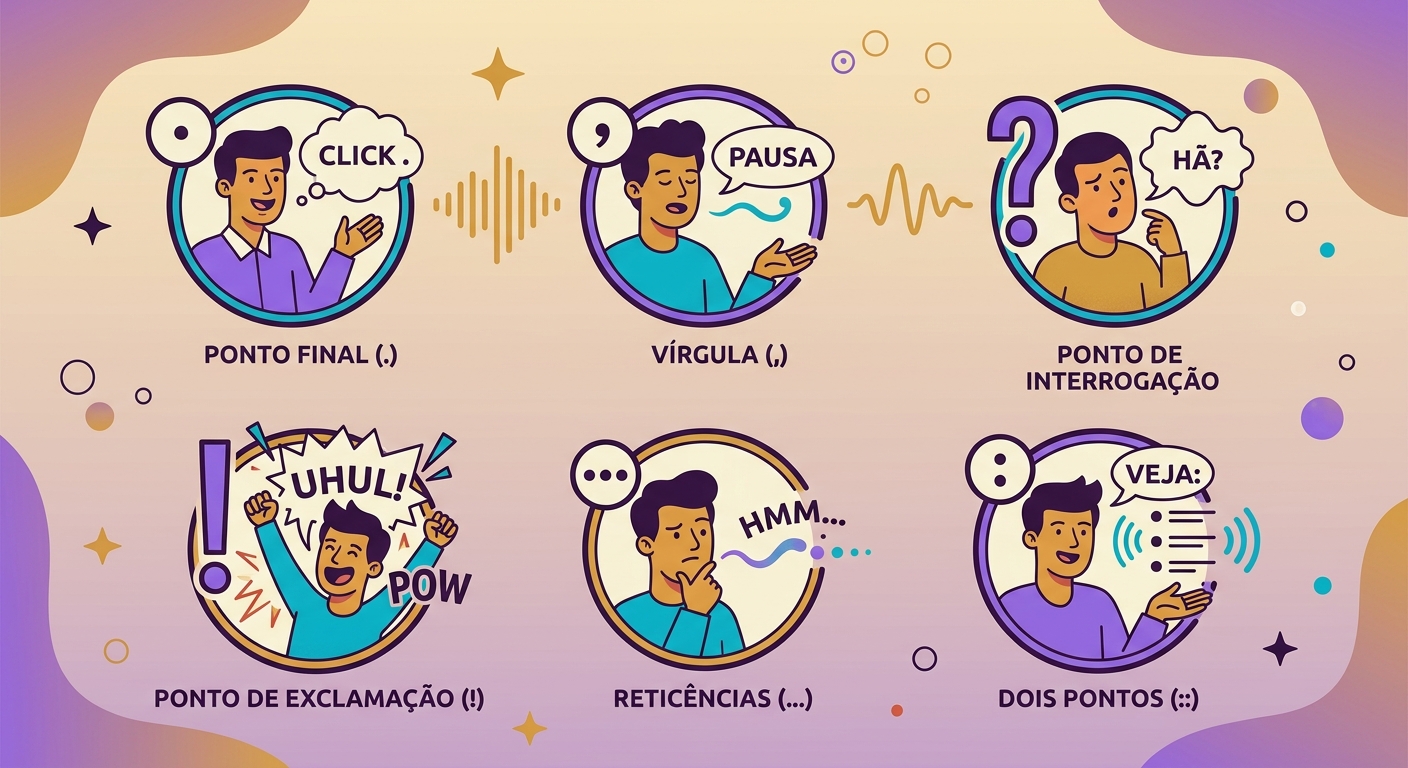
- Tanda baca sangat penting: koma = jeda pendek, elipsis = jeda panjang, titik = penurunan nada
- Emoji: sebagian besar model mengabaikannya atau membacanya sebagai kata (misalnya "tersenyum") — hapus sebelum diproses
Contoh penggunaan praktis
- Narasi kursus: seperti yang kami lakukan di Academy — cepat, hemat biaya, dan konsisten
- Audiobook mandiri: konversi PDF/EPUB menjadi MP3 untuk didengarkan saat berkendara
- Aksesibilitas: ubah konten blog Anda menjadi audio bagi pembaca dengan kesulitan membaca
- Podcast otomatis: konversi newsletter ke format podcast untuk distribusi yang lebih luas
- Suara untuk video: gantikan voice-over mahal dengan TTS saat sinkronisasi waktu bukan prioritas utama
Coba sekarang juga
Di chat Brainiall, kirim pesan dan klik ikon 🔊 pada respons untuk mendengarkannya dengan TTS. Atau gunakan rute /api/tts melalui API. Paket Pro Rp 49rb memungkinkan penggunaan TTS yang leluasa; paket Business Rp 199rb mencakup kredit API untuk integrasi eksternal.