
GPT-5 vs Claude Sonnet vs Gemini 3 Pro: hangisini seçmeli?
Model seçimi düşündüğünüzden çok daha önemli
2026'da üst düzey modeller arasındaki fark belirli görevlerde oldukça belirgin. 2-3 seçeneği test etmeden doğrudan en ünlüsüne (GPT) gitmek, token başına 2-3 kat daha fazla maliyet çıkarabilir ya da sizin özel durumunuzda %20 daha kötü sonuç verebilir.
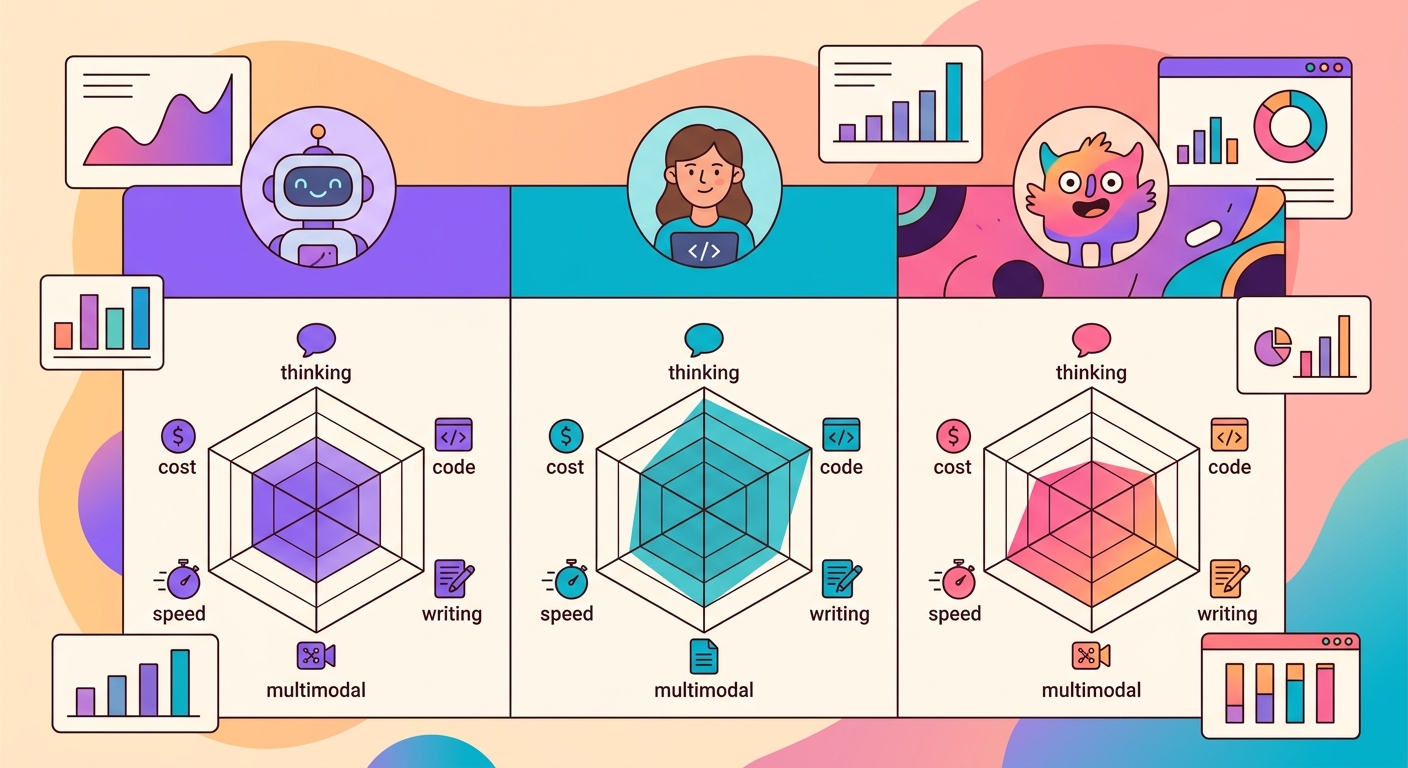
Brainiall'daki 3 baskın model:
- Claude Sonnet 4.6 (Anthropic): karmaşık akıl yürütme, uzun yazı ve kod için en iyi
- GPT-5 (OpenAI): multimodal (görsel+metin+kod) ve yaratıcılık için en iyi
- Gemini 3 Pro (Google): devasa bağlamlar (1M+ token) ve düşük gecikme için en iyi
2026'daki gerçek maliyetler (milyon token başına)
| Model | Girdi | Çıktı | Notlar |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | ₺15 | ₺75 | Cache hit girdiyi 10x azaltır |
| GPT-5 | ₺12 | ₺60 | Token başına daha ucuz |
| Gemini 3 Pro | ₺7 | ₺35 | En iyi maliyet/kalite oranı |
| Claude Haiku 4.5 | ₺2 | ₺10 | Hızlı, basit görevler için ideal |
Ortalama bir konuşma chatbotu için (100 mesaj, her biri ~500 token), günlük maliyet ₺10-50 arasında kalır. Toplu işlem uygulamalarında (10 bin belge analizi) bu rakam ₺500-2000'e çıkabilir.
Her birini ne zaman kullanmalı
Claude Sonnet 4.6 şunlar için:
- Uzun belge yazımı (raporlar, makaleler, hukuki analizler)
- Code review ve refactoring
- Metinlerde nüans analizi (edebiyat, felsefe)
- Karmaşık talimatları takip etmeyi gerektiren görevler
- Uzun akıl yürütme zincirine sahip ajanlar
GPT-5 şunlar için:
- Açık uçlu yaratıcı yanıtlar (beyin fırtınası, senaryolar)
- Görsel + metnin birlikte önemli olduğu multimodal kullanımlar
- Hızlı ve doğrudan yanıtlar
- "Mümkün olan en genel modeli" istediğiniz durumlar
- Standart Python ve JavaScript kodu
Gemini 3 Pro şunlar için:
- Büyük belgeleri işleme (kitaplar, tüm kod tabanları)
- Gecikmenin kritik olduğu uygulamalar (<1s)
- Video analizi (yerel video multimodal desteği)
- Bilimsel ve matematiksel görevler
- Maliyetin önemli olduğu büyük ölçekli üretim
Kendi durumunuzu 3 özdeş pipeline ile test edin
Genel benchmark'lara güvenmeyin. Kendi değerlendirmenizi oluşturun:
1. Gerçek kullanımınızı temsil eden 20 örnek seçin
2. Aynı prompt'u 3 modelde de çalıştırın
3. Yanıtları kör olarak değerlendirin (hangisinin hangisi olduğunu bilmeden)
4. Şunları ölçün: doğruluk, gecikme, maliyet
Genel benchmark'larda "daha kötü" görünen model, çoğu zaman sizin durumunuz için en iyi seçenek olabilir; çünkü görevinizin benchmark'ın yakalayamadığı kendine özgü özellikleri vardır.
Brainiall üzerinden kullanım
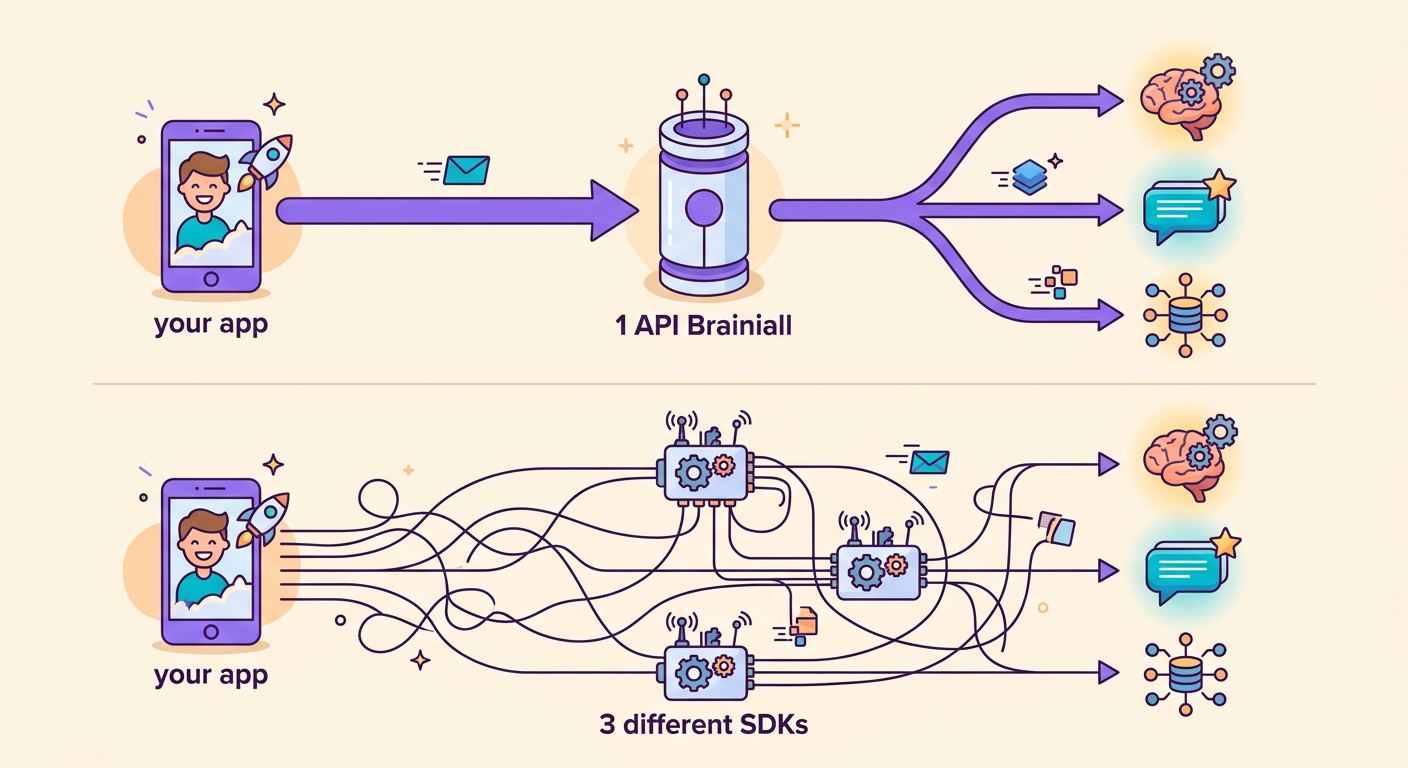
Gateway'imizin en büyük avantajı: 1 string değiştirerek modeli değiştirebilirsiniz.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Entropiyi 3 cümlede açıkla."))`
Brainiall olmadan 3 ayrı hesap, 3 ayrı SDK ve 3 ayrı faturalama sistemi kurmanız gerekirdi. Tek gateway ile her şey şeffaf ve zahmetsiz.
Karşılaştırma yaparken dikkat edilmesi gereken tuzaklar
- Taraflı prompt: prompt'unuz GPT için optimize edildiyse Claude haksız yere daha kötü görünebilir
- Tek örnek yeterli değil: çalıştırmalar arasındaki değişkenlik yüksektir; en az N=20 yapın
- Yanlış metrik: yalnızca doğruluğu ölçmek maliyet/gecikme/sağlamlığı göz ardı eder
- Cache'i atlamak: Claude, tekrarlayan sistemlerde maliyeti 10x düşüren prompt cache özelliğine sahiptir
- Türkçe'de test etmemek: tüm modeller İngilizce'de iyidir; Türkçe'de fark çok daha belirgindir
Hemen şimdi test edin
Brainiall sohbetinde üstteki açılır menüden bir model seçin ve sorunuzu sorun. Ardından başka bir modele geçip karşılaştırın. Pro planı ₺29'a 15 modele erişim sağlar; Business planı ise tüm modellerin kilidini açar.