
Metinlerdeki dili otomatik olarak tespit edin
Otomatik dil tespiti neden bu kadar işe yarar
Gerçek hayattan senaryolar:
- Çok dilli chatbot: Kullanıcı "Hola, como estoy?" yazar → İspanyolca tespit edilir → Varsayılan dil yerine İspanyolca yanıt verilir
- Küresel içerik akışı: Haber toplayıcı, çeviri yapmadan önce makaleleri dile göre gruplamak zorundadır
- Destek: Japonca gelen bir destek talebi Japonya ekibine yönlendirilmeli, Brezilya ekibine değil
- Moderasyon: Hassas içerik kuralları bölgeye ve dile göre farklılık gösterir
- Analitik: Kitlenizin dilsel çeşitliliğini ölçün
Facebook'un açık kaynaklı modeli fastText language identification, 176 dili metin başına 10ms'den kısa sürede tespit eder.
Model dilleri nasıl ayırt eder
fastText, her kelimeyi karakter n-gram'ları (subword'ler) olarak temsil eder. Ardından bu vektörleri toplar ve softmax regresyonu ile sınıflandırır. Neden işe yarar:
- Portekizcede "ção", "nh", "lh" gibi karakteristik yapılar bulunur
- İngilizcede "th", "ing", "ed" kalıpları öne çıkar
- Almancada "sch", "ch", "äöü" karakteristiktir
- Pinyin ile yazılmış Mandarin, hanzi'den tamamen farklı örüntüler sergiler
Model, n-gram'ların istatistiksel imzasına bakarak karar verir. 3 kelimeden kısa metinler belirsiz olabilir; 20 ve üzeri kelime içeren metinlerde doğruluk %99'u aşar.
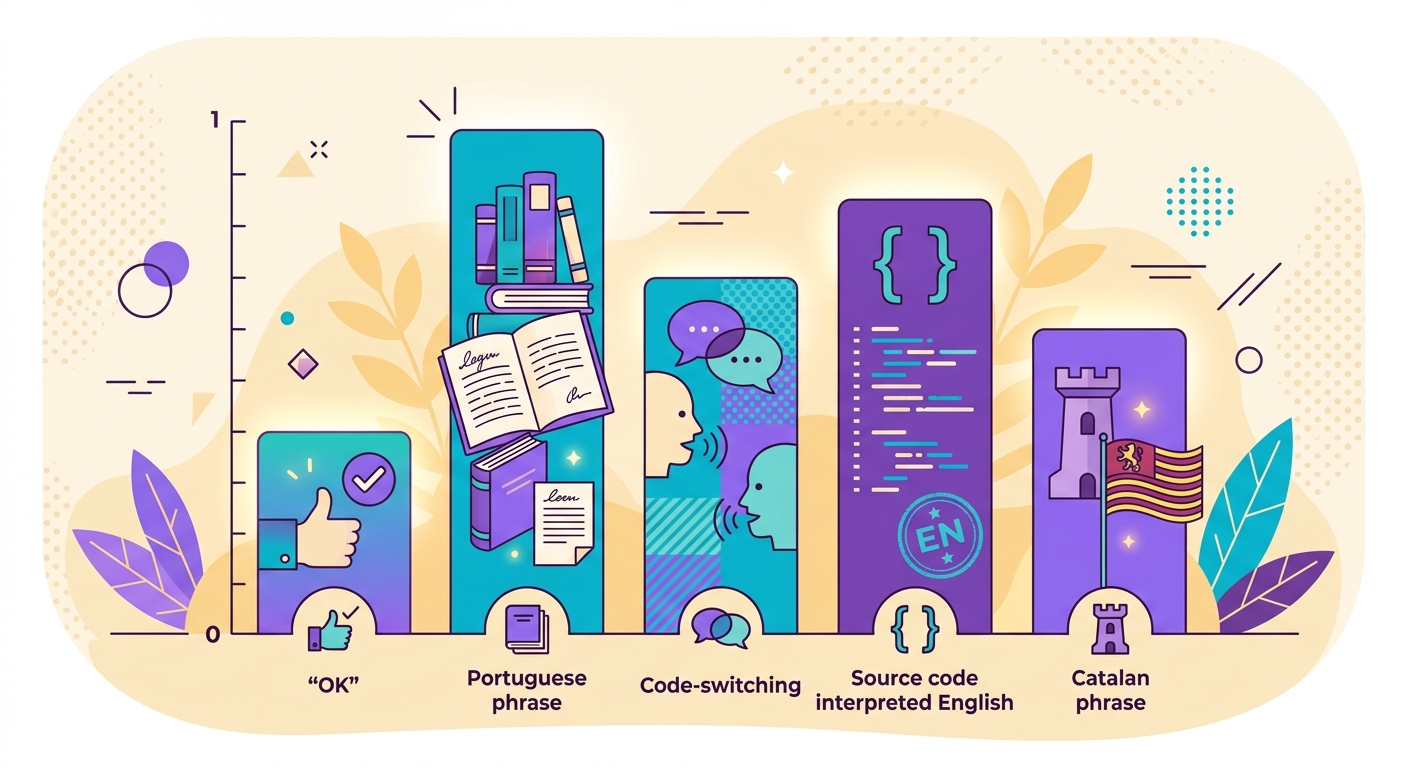
Zorlu durumlar ve nasıl başa çıkılır
- Code-switching: İki dili karıştıran metinler ("Hello, tudo bem?") — model baskın dili döndürür, ancak güven skoru düşer
- Yakın diller: Portekizce, İspanyolca ve Katalanca — fastText %90+ doğrulukla çalışır, ancak sınır durumlar mevcuttur
- Transliterasyon: Pinyin ile yazılmış Çince veya Latin harflerle yazılmış Arapça — model bunları yanlışlıkla "İngilizce" olarak algılayabilir
- Çok kısa metinler: "OK" gibi ifadeler herhangi bir dile ait olabilir — düşük güven skoru döner, eşik değeri kullanmanız şarttır
- Kaynak kodu: Programlama kodu "İngilizce" olarak tespit edilir — gerekirse önceden filtreleyin
Önerilen eşik: Yalnızca güven skoru 0,75'in üzerindeki tespitleri kabul edin. Altında kalanları "bilinmiyor" olarak işaretleyin ve insan onayına gönderin.
Stack'inize entegrasyon
Tipik Python örneği:
`python
import httpx
r = httpx.post(
"https://api.brainiall.com/api/nlp/language",
json={"text": "Hola, ¿cómo estás hoy?"},
headers={"Authorization": "Bearer brnl-xxx"}
)
# {"language": "es", "confidence": 0.96, "top_3": [
# {"lang": "es", "conf": 0.96},
# {"lang": "pt", "conf": 0.02},
# {"lang": "ca", "conf": 0.01}
# ]}`
Düşük güven durumlarında alternatifleri göstermek istediğinizde top_3 kullanın (örn: "İspanyolca gibi görünüyor, ancak Katalanca olabilir — lütfen onaylayın").
Gelişmiş kullanım senaryoları
- NLP ön işleme: Duygu analizinden önce dili tespit edin ve doğru modele yönlendirin
- Filtreleme: Büyük veri setlerinde hedef dil dışındaki metinleri temizleyin
- Trafik yönlendirme: Çok dilli kümeler arasında yük dengelemesi yapın
- Segmentasyon: Karışık dil içeren uzun belgeleri dile göre bölümlere ayırın
- Arama: Kullanıcıların "bu platformda yalnızca Türkçe içerikleri göster" gibi sorgular yapmasına olanak tanıyın
Hemen deneyin
Brainiall sohbet arayüzünde "bu metnin dilini tespit et: [yapıştırın]" yazmanız yeterli. API: /api/nlp/language. Tipik gecikme süresi 10ms'nin altında — gerçek zamanlı kullanım için idealdir. Pro planında cömert kullanım hakkı mevcuttur; Business planı ise toplu işlem için Batch API içerir.