
Sesli Konuşun (STT → LLM → TTS pipeline)
Sesli bir konuşmanın anatomisi
Yapay zeka ile sesli konuşma, 3 API'den oluşan bir zincirdir:
`
[Siz konuşursunuz] → Mikrofon → STT (Whisper) → metin
↓
LLM (Claude/GPT)
↓
[Siz duyarsınız] ← Hoparlör ← TTS (pf_dora) ← metin`
Her adımın bir gecikmesi vardır. Deneyimin doğal hissettirmesi (insan konuşması gibi) için toplam sürenin 1,5 saniyenin altında kalması gerekir. 2026'da bu ulaşılabilir bir hedef olmakla birlikte dikkatli bir mühendislik gerektirmektedir.
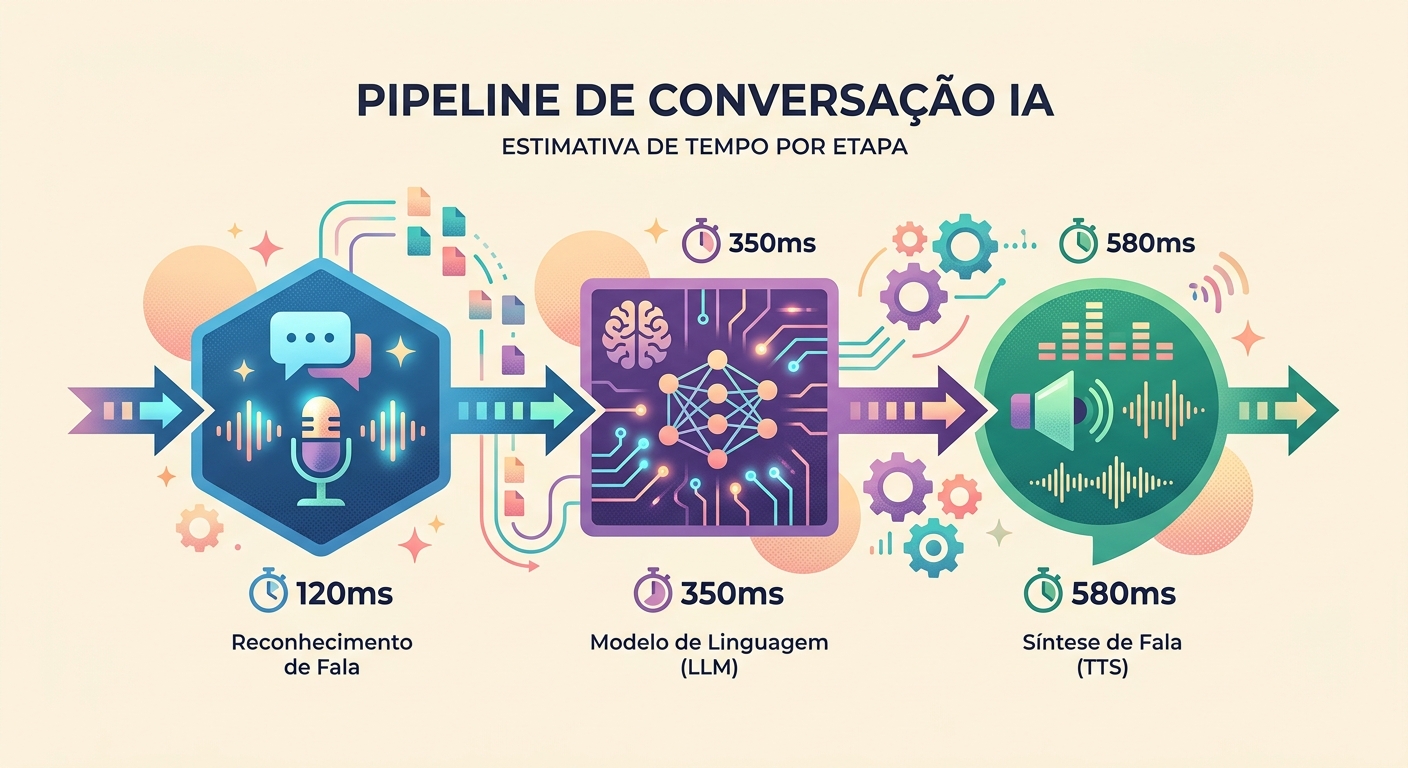
2026'da gerçekçi gecikme süreleri
Brainiall'daki gerçek konuşmada yapılan ölçümler:
- Ses yakalama (mikrofon → WAV): ~100ms (donanıma bağlı)
- STT (Whisper Large v3): 3-5 saniyelik cümle için 300-600ms
- LLM (hız için Claude Haiku): ilk token için 400-900ms
- TTS (unified-api üzerinden pf_dora): 3-5 saniyelik ses için 300-500ms
- Oynatma (hoparlör gecikmesi): ~50ms
İlk tokenden sese toplam süre: 1150-2150ms. Model erken "konuşmaya" başlarsa (streaming) bu kabul edilebilir bir değerdir.
Streaming her şeydir
Streaming olmadan her adım bir öncekinin bitmesini bekler: 600ms + 900ms + 500ms = minimum 2000ms.
Streaming ile:
- STT, siz henüz konuşurken transkripsiyon yapmaya başlayabilir (VAD — Voice Activity Detection)
- LLM, STT tamamlanmadan token üretmeye başlar (niyet tahminiyle)
- TTS, LLM son kelimeleri üretirken ilk kelimeleri seslendirmeye başlar
Efektif gecikme 400-700ms'ye düşer. Doğal hissettirir.
VAD: dinlemeyi ne zaman durdurmak gerekir
En ince sorun: konuşmayı bitirdiğinizi tespit etmek. Çok erken kesilirse cümleniz yarıda kalır. Çok geç kesilirse 500ms gecikme eklenir.
Teknikler:
- 600ms mutlak sessizlik: basit ama düşünme sırasındaki doğal duraklamaları kaldıramaz
- Silero VAD: cümle sonunu <50ms içinde ~%95 doğrulukla tespit eden sinir ağı modeli
- STT'den güven skoru: Whisper güven değeri döndürür; düşerse konuşma muhtemelen bitmiştir
- Kesinti tespiti: kullanıcı tekrar konuşmaya başlar → devam eden TTS iptal edilir, döngü yeniden başlar
Brainiall, Silero VAD ve dinamik sessizlik eşiği kullanır (ortama göre otomatik ayarlanır).
Gecikme ve kalite için model seçimi
Sesli modda genellikle hız kazanmak için LLM kalitesinden biraz ödün vermek mantıklıdır:
- Claude Haiku 4.5: ~400ms ilk token, doğrudan yanıtlar, ₺2/1M token
- GPT-5 mini: ~350ms, Haiku'dan daha yaratıcı, ₺3/1M token
- Gemini 3 Flash: ~250ms, kısa yanıtlar için mükemmel, ₺2/1M token
Kalitenin gecikmeden önemli olduğu konuşmalar için (örn: ayrıntılı dil öğretmeni), Claude Sonnet 4.6 veya tam GPT-5'e geçin.
Sesli modun iyi çözdüğü kullanım senaryoları
- Dil konuşma pratiği: doğal yanıt veren yapay zeka ile İngilizce konuşma alıştırması yapın
- Eller serbest asistan: araba kullanırken, yemek pişirirken, egzersiz yaparken
- Erişilebilirlik: yazmakta güçlük çeken kişiler için
- Yürüyüşte beyin fırtınası: yazmak yerine konuşarak fikir kaydetme
- Özel ders: soru ve hızlı yanıt, daha doğal bir öğretim akışı
- Kurumsal — telefon müşteri hizmetleri: eski tarz IVR sistemlerini doğal konuşmayla değiştirme
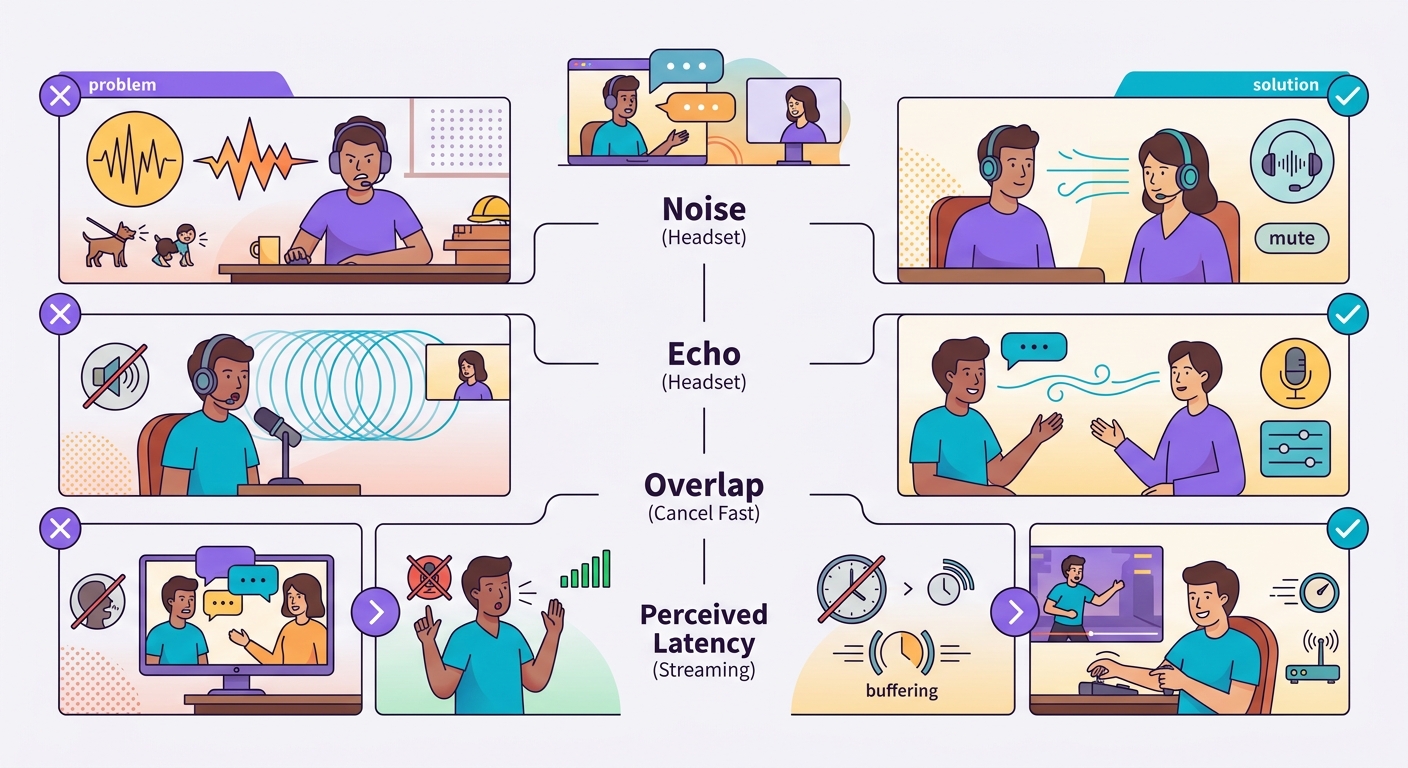
Yaygın tuzaklar
- Arka plan gürültüsü: ortam sesi VAD'ın başarısız olmasına neden olur; kulaklık veya yönlü mikrofon kullanın
- TTS yankısı: hoparlör dizüstü bilgisayarın hoparlörüyse mikrofon TTS'i yakalayıp geri transkribe edebilir; kulaklık kullanın
- Konuşma çakışması: kullanıcı sözü keser, sistem geç tepki verir = hayal kırıklığı; hızlı iptal mekanizması uygulayın
- Algılanan gecikme ve gerçek gecikme: 1 saniyelik gecikme metinde kabul edilebilir görünür, seste yavaş hissettirir; mümkün olduğunda <500ms'ye optimize edin
Tarayıcıda temel uygulama
Hızlı deneme için:
`javascript
// 1. Yakalama
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Her 500ms'de chunk gönder
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. LLM'e gönder, yanıt al
// 4. Yanıtı /api/tts'e gönder, sonucu oynat
};
mediaRecorder.start(500);`
Brainiall bunu sohbette hazır olarak sunar: mikrofon simgesine tıklayın ve basılı tutun.
Hemen şimdi deneyin
Brainiall sohbetinde mikrofon simgesine tıklayın ve basılı tutun. Konuşun, bırakın, metin ve ses olarak yanıt alın. Pro planı (₺29) tam ses desteği içerir; Business planı premium seslerin ve öncelikli gecikmenin kilidini açar.