
Narre qualquer texto em 9 idiomas com 54 vozes neurais
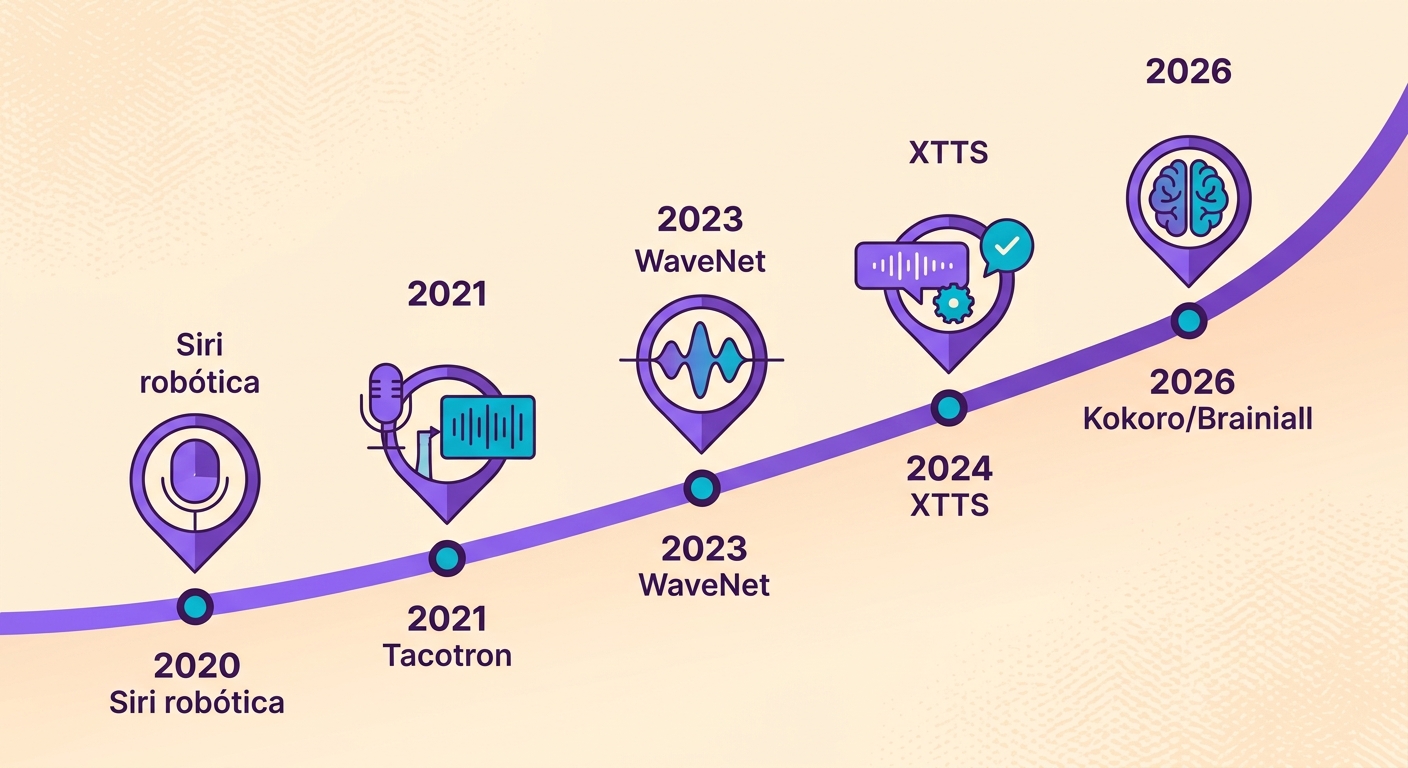
A evolução do TTS em 5 anos
Até 2020, Text-to-Speech soava robótico — a geração da Siri original. De 2021 a 2023, aprendemos a usar modelos WaveNet e Tacotron para chegar em voz natural. De 2024 em diante, modelos de uma escala nova (XTTS, Kokoro, VALL-E) trouxeram três avanços decisivos:
1. Tamanho pequeno: Kokoro tem apenas 82 milhões de parâmetros — 100× menor que os gigantes antigos, mas mesma qualidade
2. Inferência em tempo real: RTF (Real-Time Factor) < 0.2 em uma GPU de entrada; ou seja, 1 minuto de áudio é sintetizado em menos de 12 segundos
3. Prosódia natural: entonação, ênfase, ritmo — não mais "monótono com vírgula"
Os 9 idiomas da Brainiall
- Português brasileiro: pf_dora (feminina adulta), pm_alex, pm_santa (masculinas)
- Inglês americano: af_heart, af_bella, af_nicole, am_adam, am_michael
- Inglês britânico: bf_emma, bm_george, bm_lewis
- Espanhol: ef_lucia, em_carlos
- Francês: ff_juliette, fm_louis
- Alemão: gf_sophia, gm_max
- Italiano: if_chiara, im_marco
- Chinês mandarim: zf_mei, zm_wei
- Japonês: jf_haruka, jm_kenji
Cada voz tem sua personalidade: pf_dora é clara e educativa (usamos nos cursos da Brainiall Academy), am_adam é profissional corporativo, af_heart tem tom mais emocional.
Como escolher a voz certa para o contexto
- E-learning / tutoriais: vozes neutras e articuladas (pf_dora, am_adam)
- Marketing / anúncios: vozes mais dinâmicas e expressivas (af_heart, am_michael)
- Audiobooks: vozes quentes e narrativas (af_bella, bm_george)
- Notícias: vozes formais e claras (pm_santa, am_adam)
- Chatbots / assistentes: vozes friendly e rápidas (af_nicole, pm_alex)
Dica prática: gere 3-5 segundos de teste com 3 vozes candidatas antes de sintetizar um texto longo. A preferência é sempre subjetiva.
🎧 Ouça a narração completa (vídeo demo em produção)
Controlando velocidade e tom
Os parâmetros mais úteis:
- speed: 0.25 a 4.0 — default 1.0. Use 0.85 para audiobooks (narração calma), 1.15 para conteúdo educativo, 1.3+ só para prévias rápidas
- format: mp3, wav, ogg. MP3 é default (melhor compressão); WAV para quando você vai editar o áudio depois; OGG para streaming web
- pitch: alguns modelos aceitam, ajuste em semitons (-5 a +5)
Não vá a extremos: speed > 2.0 fica incompreensível, < 0.5 fica artificial.
Limites técnicos e de uso
- Máximo por request: 4000 caracteres — aproximadamente 4 parágrafos. Textos longos requerem chunking
- Idiomas mistos: cada voz fala bem seu idioma principal; misturar (ex: texto PT com palavras em inglês) pode sair com pronúncia hesitante
- Nomes próprios estrangeiros: pronuncie foneticamente no prompt — "Maicrosoft" em vez de "Microsoft"
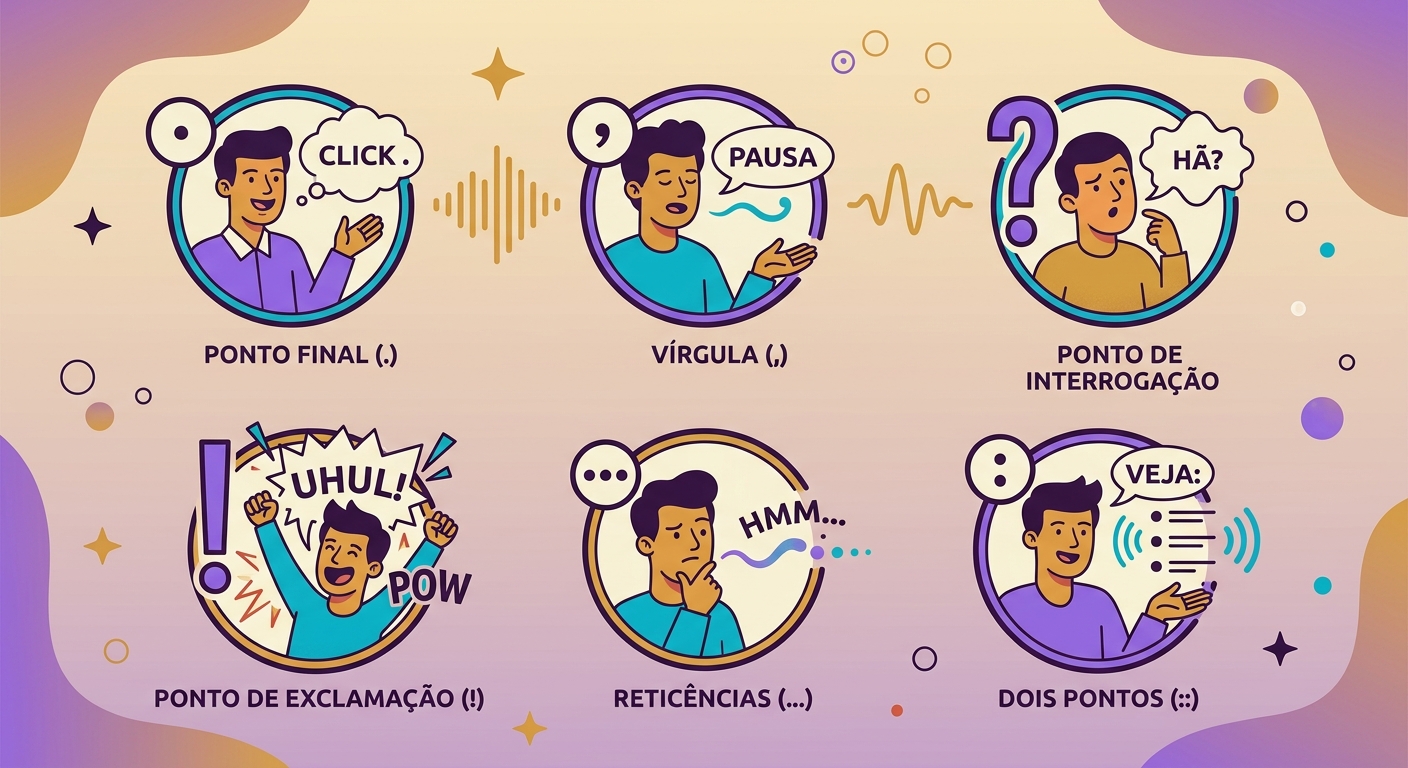
- Pontuação importa: vírgulas = pausa curta, reticências = pausa longa, ponto final = queda de tom
- Emojis: a maioria dos modelos ignora ou lê como palavra ("sorrindo") — remova antes
Casos de uso práticos
- Narração de cursos: como fazemos na Academy — rápido, barato, consistente
- Audiolivros caseiros: converta PDFs/EPUBs em MP3 para ouvir no carro
- Acessibilidade: converta seu blog em áudio para leitores com dificuldade de leitura
- Podcasts automáticos: converta newsletters em formato podcast para distribuição
- Voz para vídeos: substitua voice-over caro por TTS quando timing não é crítico
Teste agora mesmo
No chat Brainiall, envie uma mensagem e clique no ícone 🔊 na resposta para ouvir com TTS. Ou na rota /api/tts via API. Plano Pro R$29 permite uso generoso de TTS; Business R$99 inclui créditos API para integrações externas.