
Phát hiện độc hại trong bình luận bằng AI
Thảm họa Perspective: chuyện gì đã xảy ra
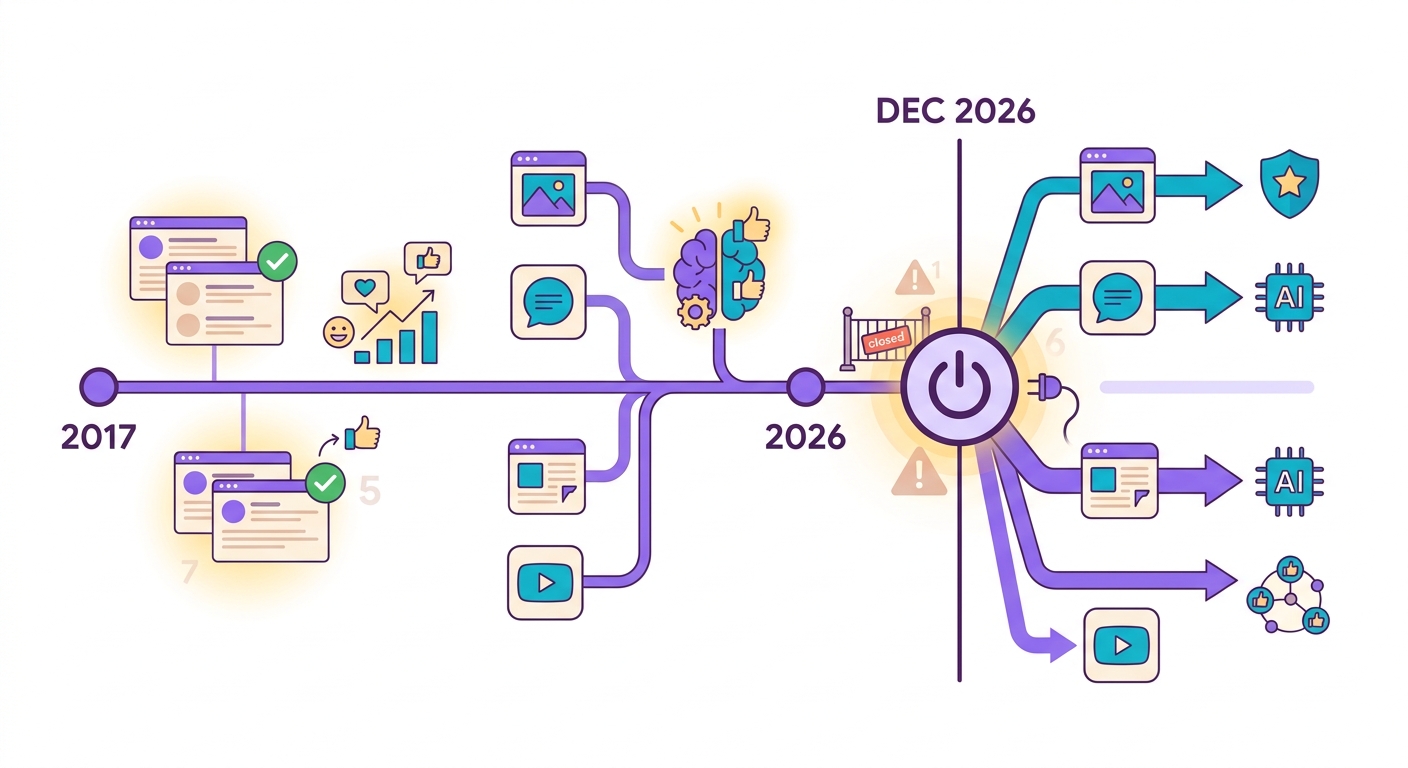
Vào tháng 10/2024, Google thông báo rằng Perspective API — dịch vụ phát hiện nội dung độc hại miễn phí được sử dụng nhiều nhất thế giới — sẽ ngừng hoạt động vào tháng 12/2026. Các nền tảng phụ thuộc vào nó (Reddit, New York Times, The Guardian, hàng nghìn diễn đàn) có 2 năm để chuyển đổi.
Vấn đề là: Perspective hoàn toàn miễn phí. Các giải pháp thương mại thay thế như Azure Content Safety và AWS Comprehend tính phí từ 1 USD cho mỗi 1.000 lượt phân tích. Với một diễn đàn lớn có 100k bình luận/ngày, con số đó lên tới 3.000 USD/tháng chỉ riêng cho kiểm duyệt.
Brainiall cung cấp giải pháp kiểm duyệt với các mô hình Detoxify + Unitary chạy trên ONNX cục bộ (CPU), với chi phí dưới 0,001 R$ mỗi lượt phân tích — rẻ hơn 100 lần.
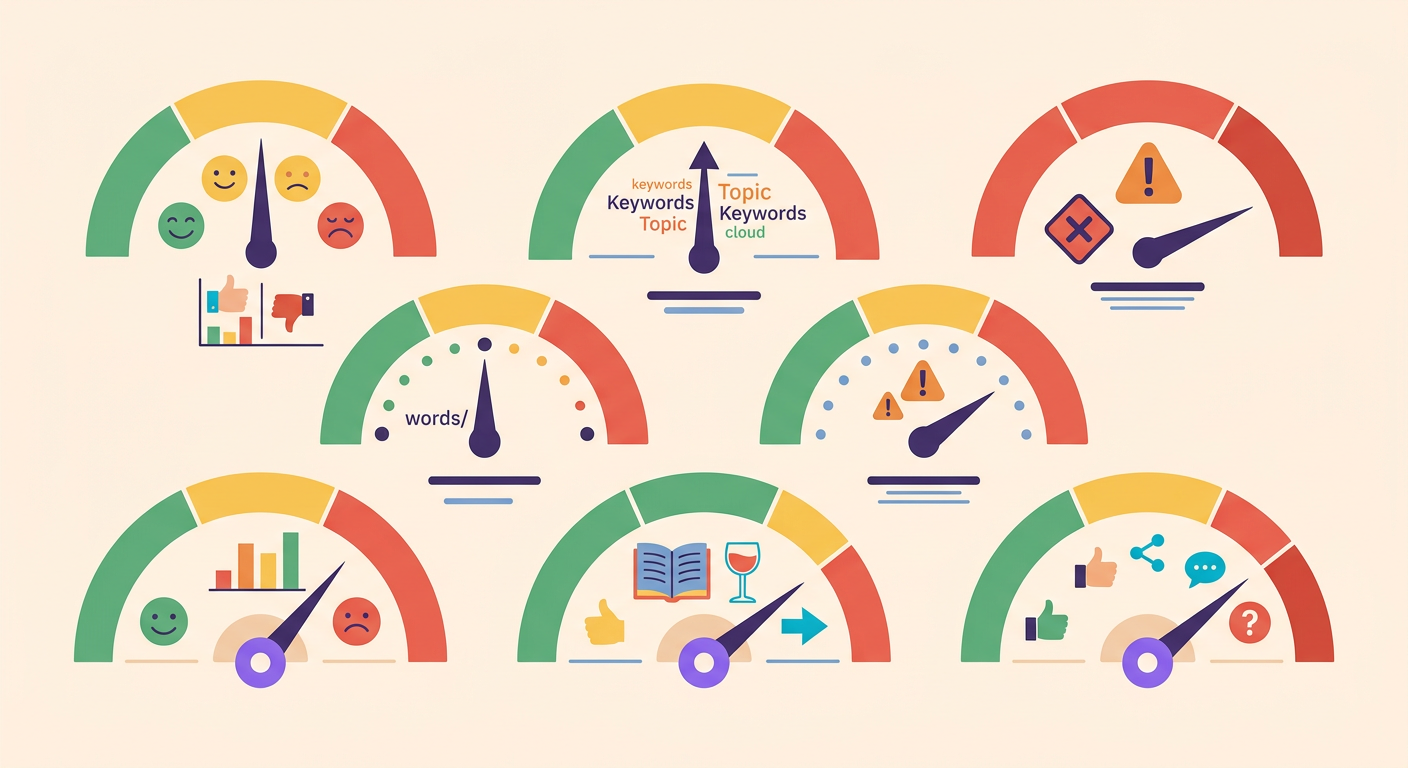
7 danh mục quan trọng cần biết
Detoxify phân loại văn bản theo 7 chiều với điểm từ 0 đến 1:
1. Toxicity: xúc phạm chung, hung hăng
2. Severe toxicity: đe dọa, thù hận cực đoan
3. Obscene: ngôn ngữ tục tĩu và thô lỗ
4. Threat: đe dọa bạo lực thể chất
5. Insult: tấn công cá nhân trực tiếp
6. Identity hate: phân biệt đối xử dựa trên nhóm (chủng tộc, giới tính, tôn giáo)
7. Sexual explicit: nội dung khiêu dâm rõ ràng
Chính sách của bạn sẽ quyết định các ngưỡng. Ví dụ phổ biến: chặn nếu severe_toxicity > 0,5 HOẶC identity_hate > 0,6 HOẶC threat > 0,3. Các từ tục đơn lẻ (obscene > 0,8) thường chỉ nhận cảnh báo, không bị chặn.
Vấn đề với tiếng Việt và ngôn ngữ địa phương
Detoxify được huấn luyện bằng tiếng Anh. Hiệu quả đạt 95%+ với các bình luận tiếng Anh. Với các ngôn ngữ khác, độ chính xác giảm xuống còn 75-85% — các từ địa phương và tiếng lóng đặc thù (nhiều từ không mang tính xúc phạm) khiến mô hình bị nhầm lẫn.
Tại Brainiall, chúng tôi sử dụng thêm một lớp bổ sung: một bộ phân loại lai kết hợp:
- Detoxify đa ngôn ngữ (70% quyết định)
- Danh sách từ ngữ địa phương đặc thù (20%)
- LLM nhỏ (Gemma 3 hoặc tương tự) cho các trường hợp ranh giới (10%)
Cách này nâng độ chính xác lên 92%+ trong khi vẫn duy trì độ trễ dưới 80ms.
Khi AI mắc sai lầm nghiêm trọng
- Mỉa mai: "Tuyệt vời, cảm ơn vì đã phá hủy cuộc đời tôi!" — điểm tích cực, nhưng nội dung thực sự thù địch
- Châm biếm hợp lệ: các bình luận chính trị hài hước có thể bị đánh dấu là tấn công
- Bối cảnh y tế: "tôi đang giết chết bệnh nhân vì làm việc quá sức" (nhân viên y tế kiệt sức) — cảnh báo dương tính giả
- Trích dẫn: một bài viết trích dẫn nội dung phân biệt chủng tộc để phê phán nó lại bị phân tích như chính nội dung đó
- Code-switching: người dùng trộn lẫn nhiều ngôn ngữ và emoji khiến mô hình bị rối
Giải pháp thực tế: kết hợp điểm tự động với kiểm duyệt mềm (yêu cầu xác nhận trước khi đăng) thay vì chặn cứng đối với các trường hợp ranh giới.
Tích hợp vào nền tảng của bạn
Quy trình được khuyến nghị:
1. Người dùng nhập bình luận → gửi POST /api/toxicity với { text }
2. API trả về { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Code của bạn quyết định: chặn, cảnh báo, hoặc phê duyệt
4. Nếu cảnh báo, hiển thị "Hãy xem lại — nội dung này có thể gây khó chịu cho một số người" trước khi đăng
5. Với các trường hợp bị chặn, ghi log + thông báo cho đội kiểm duyệt thủ công
Không nên kiểm duyệt 100% tự động. Luôn duy trì hàng đợi thủ công cho các trường hợp ranh giới.
Thử ngay bây giờ
Trong chat Brainiall, hãy nhập "phân tích độ độc hại của bình luận này: [dán vào đây]". Hoặc sử dụng API tại route /api/nlp/toxicity. Gói Pro $5.99 bao gồm 10.000 lượt phân tích/tháng; gói Business có hàng đợi ưu tiên + xử lý hàng loạt hàng triệu lượt.