
Đọc bất kỳ văn bản nào bằng 9 ngôn ngữ với 54 giọng nói thần kinh
Sự tiến hóa của TTS trong 5 năm
Trước năm 2020, Text-to-Speech nghe rất máy móc — thế hệ của Siri nguyên bản. Từ 2021 đến 2023, chúng ta học cách sử dụng các mô hình WaveNet và Tacotron để đạt được giọng nói tự nhiên hơn. Từ năm 2024 trở đi, các mô hình thế hệ mới (XTTS, Kokoro, VALL-E) đã mang lại ba bước đột phá quan trọng:
1. Kích thước nhỏ gọn: Kokoro chỉ có 82 triệu tham số — nhỏ hơn 100× so với các mô hình khổng lồ trước đây, nhưng chất lượng tương đương
2. Suy luận thời gian thực: RTF (Real-Time Factor) < 0.2 trên GPU phổ thông; nghĩa là 1 phút âm thanh được tổng hợp trong chưa đầy 12 giây
3. Ngữ điệu tự nhiên: âm điệu, nhấn mạnh, nhịp điệu — không còn "đều đều như đọc danh sách"
9 ngôn ngữ của Brainiall
- Tiếng Bồ Đào Nha Brazil: pf_dora (nữ trưởng thành), pm_alex, pm_santa (nam)
- Tiếng Anh Mỹ: af_heart, af_bella, af_nicole, am_adam, am_michael
- Tiếng Anh Anh: bf_emma, bm_george, bm_lewis
- Tiếng Tây Ban Nha: ef_lucia, em_carlos
- Tiếng Pháp: ff_juliette, fm_louis
- Tiếng Đức: gf_sophia, gm_max
- Tiếng Ý: if_chiara, im_marco
- Tiếng Trung phổ thông: zf_mei, zm_wei
- Tiếng Nhật: jf_haruka, jm_kenji
Mỗi giọng nói có cá tính riêng: pf_dora rõ ràng và mang tính giáo dục (chúng tôi sử dụng trong các khóa học của Brainiall Academy), am_adam mang phong cách chuyên nghiệp doanh nghiệp, af_heart có giọng điệu cảm xúc hơn.
Cách chọn giọng nói phù hợp với từng ngữ cảnh
- E-learning / hướng dẫn: giọng trung tính và rõ ràng (pf_dora, am_adam)
- Marketing / quảng cáo: giọng năng động và biểu cảm (af_heart, am_michael)
- Sách nói: giọng ấm áp và kể chuyện (af_bella, bm_george)
- Tin tức: giọng trang trọng và rõ ràng (pm_santa, am_adam)
- Chatbot / trợ lý: giọng thân thiện và nhanh nhẹn (af_nicole, pm_alex)
Mẹo thực tế: tạo đoạn thử nghiệm 3-5 giây với 3 giọng ứng viên trước khi tổng hợp văn bản dài. Sở thích luôn mang tính chủ quan.
Kiểm soát tốc độ và âm điệu
Các tham số hữu ích nhất:
- speed: 0.25 đến 4.0 — mặc định 1.0. Dùng 0.85 cho sách nói (narration thư thái), 1.15 cho nội dung giáo dục, 1.3+ chỉ dùng để xem trước nhanh
- format: mp3, wav, ogg. MP3 là mặc định (nén tốt nhất); WAV khi bạn cần chỉnh sửa âm thanh sau đó; OGG cho streaming web
- pitch: một số mô hình hỗ trợ, điều chỉnh theo semitone (-5 đến +5)
Đừng đi đến cực đoan: speed > 2.0 sẽ khó nghe, < 0.5 sẽ nghe giả tạo.
Giới hạn kỹ thuật và sử dụng
- Tối đa mỗi request: 4000 ký tự — khoảng 4 đoạn văn. Văn bản dài cần chunking
- Ngôn ngữ hỗn hợp: mỗi giọng nói tốt nhất ở ngôn ngữ chính của nó; trộn lẫn (ví dụ: văn bản tiếng Bồ với từ tiếng Anh) có thể phát âm không tự nhiên
- Tên riêng nước ngoài: hãy viết theo phiên âm trong prompt — "Maicrosoft" thay vì "Microsoft"
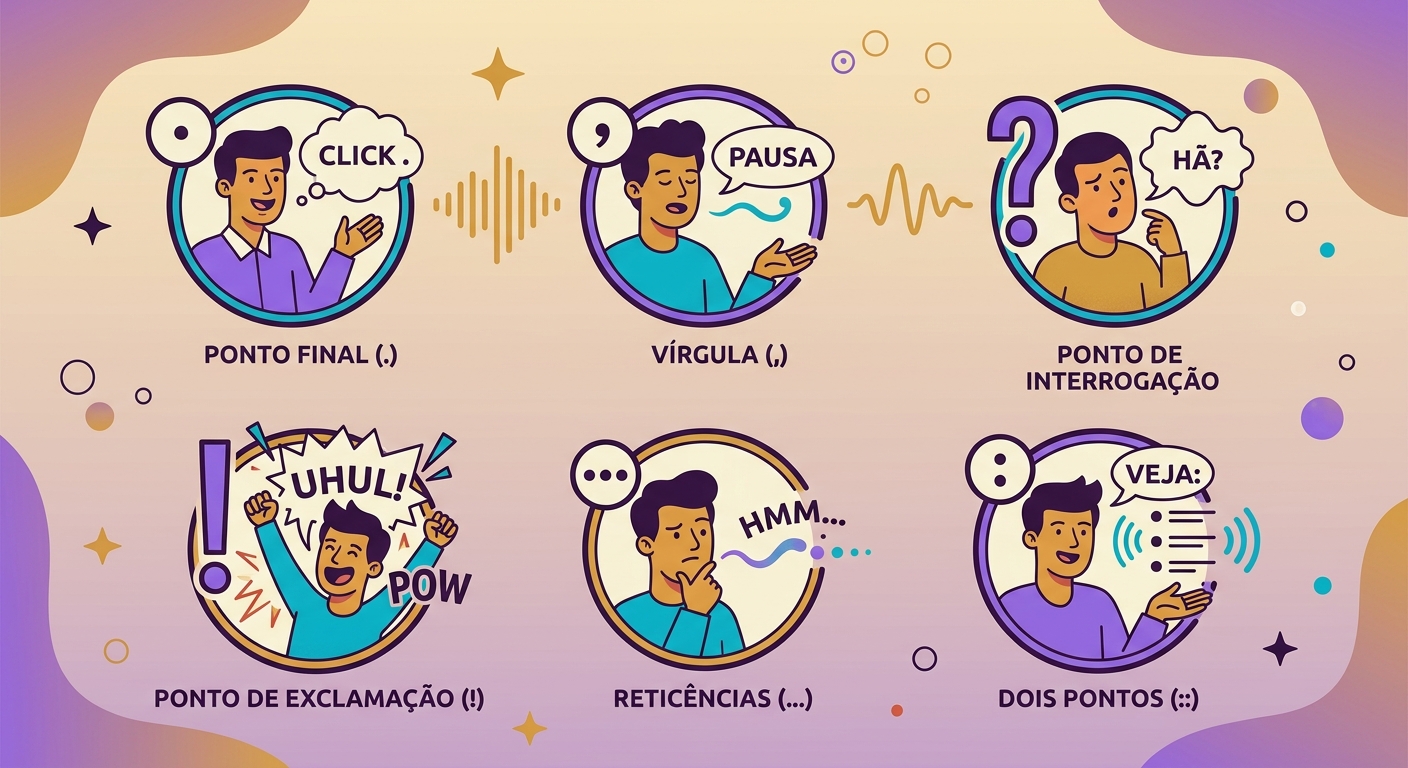
- Dấu câu quan trọng: dấu phẩy = dừng ngắn, dấu chấm lửng = dừng dài, dấu chấm = hạ giọng
- Emoji: hầu hết các mô hình bỏ qua hoặc đọc thành từ ("đang cười") — hãy xóa trước khi dùng
Các trường hợp sử dụng thực tế
- Narration khóa học: như chúng tôi làm tại Academy — nhanh, tiết kiệm, nhất quán
- Sách nói tự làm: chuyển đổi PDF/EPUB thành MP3 để nghe trên xe
- Khả năng tiếp cận: chuyển blog của bạn thành âm thanh cho người đọc gặp khó khăn với chữ viết
- Podcast tự động: chuyển đổi newsletter sang định dạng podcast để phân phối
- Giọng nói cho video: thay thế voice-over đắt tiền bằng TTS khi timing không phải yếu tố then chốt
Thử ngay bây giờ
Trong chat Brainiall, gửi một tin nhắn và nhấp vào biểu tượng 🔊 trong phản hồi để nghe bằng TTS. Hoặc qua route /api/tts via API. Gói Pro $5.99 cho phép sử dụng TTS rộng rãi; gói Business $19 bao gồm tín dụng API cho các tích hợp bên ngoài.