
Nâng cấp hình ảnh lên 4K mà không mất chất lượng
Tại sao "zoom" truyền thống luôn làm mờ ảnh
Khi bạn phóng to ảnh trong Photoshop bằng Bicubic hay Lanczos, thuật toán sẽ lấp đầy các pixel mới bằng cách tính trung bình có trọng số của các pixel lân cận. Về mặt toán học thì rất gọn gàng, nhưng kết quả luôn bị mờ — vì thông tin không tồn tại thì không thể xuất hiện. Bạn lấy một ảnh 512×512 (262k pixel) rồi "bịa ra" 768 nghìn pixel trung gian từ những gì đã có sẵn.
AI hiện đại giải quyết vấn đề này theo cách hoàn toàn khác: thay vì nội suy, nó tạo ra những gì có thể đã ở đó. Các mô hình như Real-ESRGAN được huấn luyện trên hàng triệu cặp ảnh (độ phân giải thấp, độ phân giải cao) và học cách "ảo hóa" các chi tiết hợp lý — tóc, da, kết cấu, đường viền — nhất quán với những gì bạn thấy trong ảnh gốc.
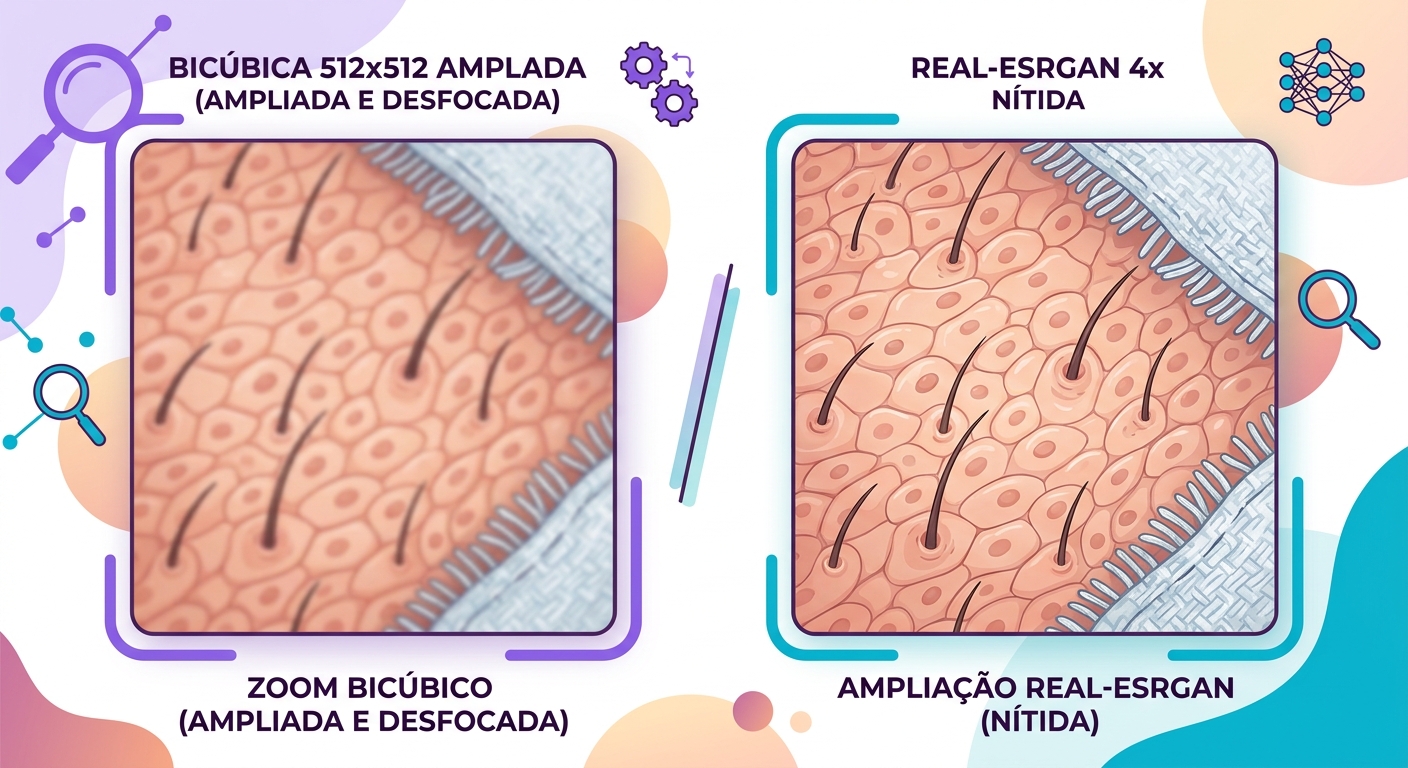
Những gì mô hình "biết" về ảnh thực
Real-ESRGAN và các mô hình tương tự được huấn luyện trên các bộ dữ liệu khổng lồ gồm ảnh ở nhiều tỷ lệ khác nhau. Chúng học các prior thống kê — tức là các pixel lân cận "thường trông như thế nào" khi nằm trong vùng da, vải, kim loại hay lá cây. Khi bạn đưa vào một ảnh độ phân giải thấp, mô hình sẽ nhận định: "vùng này có lẽ là má; má ở độ phân giải cao thường có những đặc điểm như thế này".
Điều này rất mạnh mẽ nhưng có một tác dụng phụ: mô hình sẽ tạo ra các chi tiết trông có vẻ đúng nhưng không trung thực với ảnh gốc. Với ảnh báo chí hay pháp y thì đây là vấn đề; còn với mục đích sáng tạo thì đó chính xác là điều bạn muốn.
Khi nào dùng Real-ESRGAN, GFPGAN hay các mô hình khác
Việc chọn mô hình phụ thuộc vào nội dung bạn muốn phóng to:
- Real-ESRGAN: dùng đa năng (ảnh chụp, ảnh màn hình, đồ họa). Cho độ sắc nét "tự nhiên" hơn. Chi phí tính toán ở mức trung bình.
- GFPGAN: chuyên biệt cho khuôn mặt. Nếu ảnh có người, nên xử lý khuôn mặt riêng — GFPGAN tái tạo mắt, miệng và tóc với chất lượng vượt trội cho vùng đó.
- SwinIR: lựa chọn thận trọng hơn — ít "ảo hóa" hơn, trung thực hơn. Phù hợp với ảnh kỹ thuật hoặc tài liệu.
- Pipeline kết hợp: Real-ESRGAN cho toàn bộ ảnh, sau đó GFPGAN thay thế riêng các vùng khuôn mặt. Tại Brainiall, chúng tôi tự động thực hiện kết hợp này khi phát hiện khuôn mặt trong ảnh.
Những hạn chế bạn cần biết
- Chữ trong ảnh: các chữ nhỏ sẽ bị méo mó nếu ảnh đầu vào quá kém. Mô hình "biết" chữ trông như thế nào nhưng không thể đọc nội dung gốc — nếu không phân biệt được B với 8 trong ảnh gốc, AI sẽ chọn một cái rồi tiếp tục.
- Nhiễu bị khuếch đại: ảnh có nhiều hạt nhiễu sẽ bị "tạo thêm" nhiễu cùng với các chi tiết. Hãy khử nhiễu trước khi upscale để có kết quả sạch.
- Artifact JPEG: nếu ảnh gốc có các khối nén JPEG rõ ràng, mô hình có thể làm chúng nổi bật hơn. Dùng preset "anti-artifact" khi có sẵn.
- Tác phẩm nghệ thuật: tranh vẽ, minh họa, đồ họa vector có thể bị "quá thực" — hãy dùng các mô hình chuyên biệt cho nghệ thuật (ví dụ Real-ESRGAN Anime) trong những trường hợp này.
Các trường hợp sử dụng xứng đáng với công sức
- Phục hồi ảnh cũ: ảnh scan 600×400 → có thể in ở chất lượng 4K
- Thương mại điện tử: ảnh nhà cung cấp độ phân giải thấp → chất lượng cao sẵn sàng đăng web
- In ấn: ảnh web dùng cho banner hoặc biển quảng cáo ngoài trời mà không bị vỡ hạt
- Tài liệu cũ: ảnh chụp màn hình game thập niên 90, video quay từ VHS, v.v.
Thử ngay bây giờ
Trong chat Brainiall, hãy gửi một ảnh độ phân giải thấp và yêu cầu "upscale ảnh này lên 4x". Ghi rõ trong prompt nếu ảnh có khuôn mặt (để kích hoạt kết hợp GFPGAN). Kết quả trong 3-8 giây tùy kích thước ảnh. Gói Pro 29R$ bao gồm 100 lần upscale/tháng.