
Converse por voz (STT → LLM → TTS pipeline)
A anatomia de uma conversa por voz
Conversa por voz com IA é uma cadeia de 3 APIs:
`
[Você fala] → Microfone → STT (Whisper) → texto
↓
LLM (Claude/GPT)
↓
[Você ouve] ← Alto-falante ← TTS (pf_dora) ← texto`
Cada etapa tem latência. Para a experiência parecer natural (conversa humana), o total precisa ficar abaixo de 1.5 segundos. Em 2026, isso é alcançável mas exige engenharia cuidadosa.
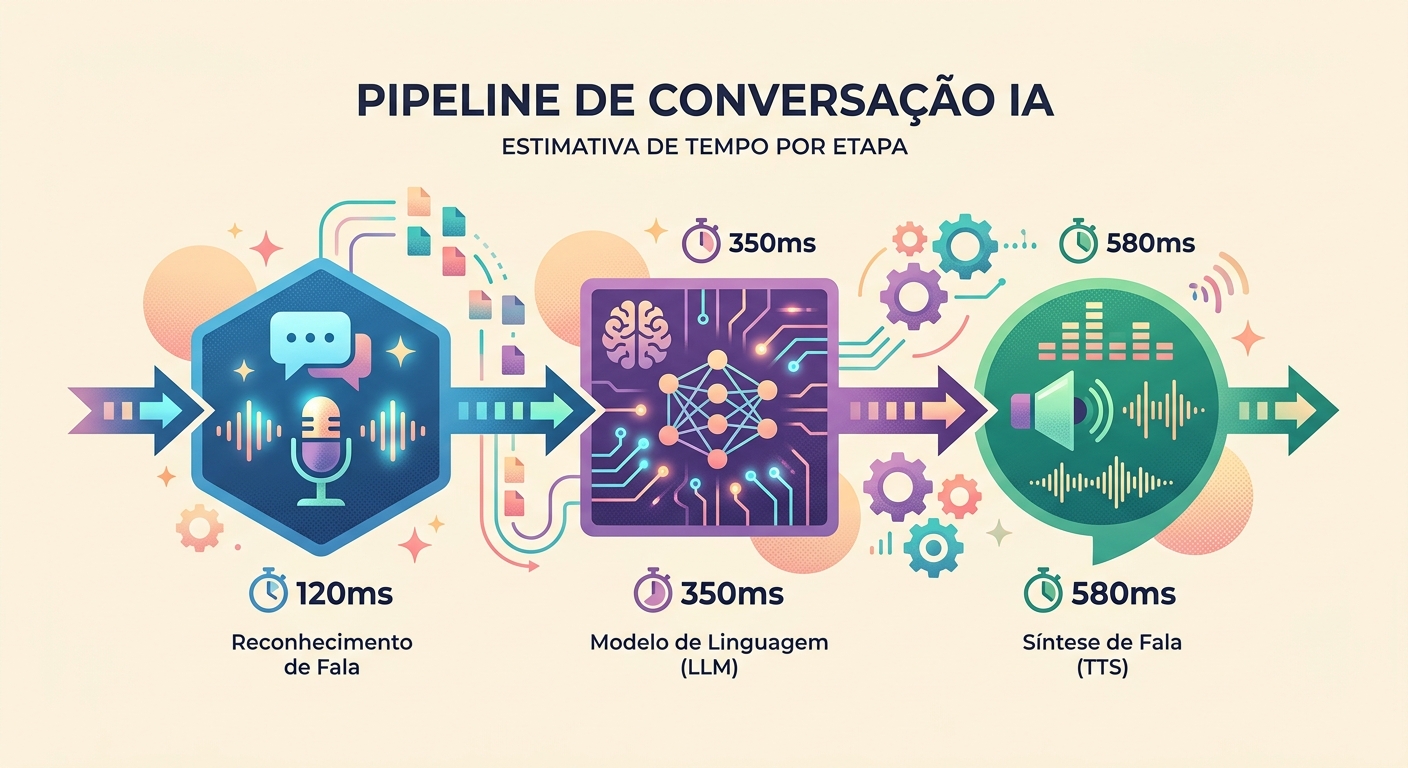
Latência realista em 2026
Medição em conversa real na Brainiall:
- Captura de áudio (mic → WAV): ~100ms (depende do hardware)
- STT (Whisper Large v3): 300-600ms para frase de 3-5s
- LLM (Claude Haiku para velocidade): 400-900ms primeira token
- TTS (pf_dora via unified-api): 300-500ms para 3-5s de áudio
- Playback (latência speaker): ~50ms
Total first-token-to-speech: 1150-2150ms. Aceitável se o modelo começa a "falar" cedo (streaming).
Streaming é tudo
Sem streaming, cada etapa espera a anterior terminar: 600ms + 900ms + 500ms = 2000ms mínimo.
Com streaming:
- STT pode começar transcrevendo enquanto você ainda fala (VAD — Voice Activity Detection)
- LLM começa a gerar tokens antes do STT terminar (com alguma previsão da intenção)
- TTS começa narrar as primeiras palavras enquanto LLM ainda gera as últimas
Latência efetiva cai para 400-700ms. Parece natural.
🎧 Ouça a narração completa (vídeo demo em produção)
VAD: quando parar de ouvir
O problema mais sutil: detectar que você parou de falar. Se parar cedo demais, corta sua frase. Se parar tarde, adiciona 500ms de latência.
Técnicas:
- Silêncio absoluto por 600ms: simples mas não lida com pausas naturais de pensamento
- Silero VAD: modelo neural que detecta fim de frase com ~95% precisão em <50ms
- Confidence from STT: Whisper retorna confidence; se cair, provavelmente terminou
- Interruption detection: usuário volta a falar → cancela TTS em andamento, recomeça ciclo
A Brainiall usa Silero VAD + threshold dinâmico de silêncio (ajusta com base no ambiente).
Escolha do modelo para latência vs qualidade
Em voice mode, geralmente vale sacrificar um pouco de qualidade de LLM para ganhar velocidade:
- Claude Haiku 4.5: ~400ms first token, respostas diretas, R$ 2/1M tokens
- GPT-5 mini: ~350ms, mais criativo que Haiku, R$ 3/1M tokens
- Gemini 3 Flash: ~250ms, excelente para respostas curtas, R$ 2/1M tokens
Para conversas onde qualidade > latência (ex: tutor de idiomas detalhado), suba para Claude Sonnet 4.6 ou GPT-5 completo.
Casos de uso que voice-mode resolve bem
- Treino de conversação em idiomas: pratique falar inglês com IA que responde naturalmente
- Assistente hands-free: dirigindo, cozinhando, exercitando
- Acessibilidade: pessoas com dificuldade de digitar
- Brainstorming em caminhadas: gravar ideias falando em vez de escrever
- Tutoria: pergunta + resposta rápida, fluxo didático mais natural
- Empresa — atendimento telefônico: substituir URA burra por conversação natural
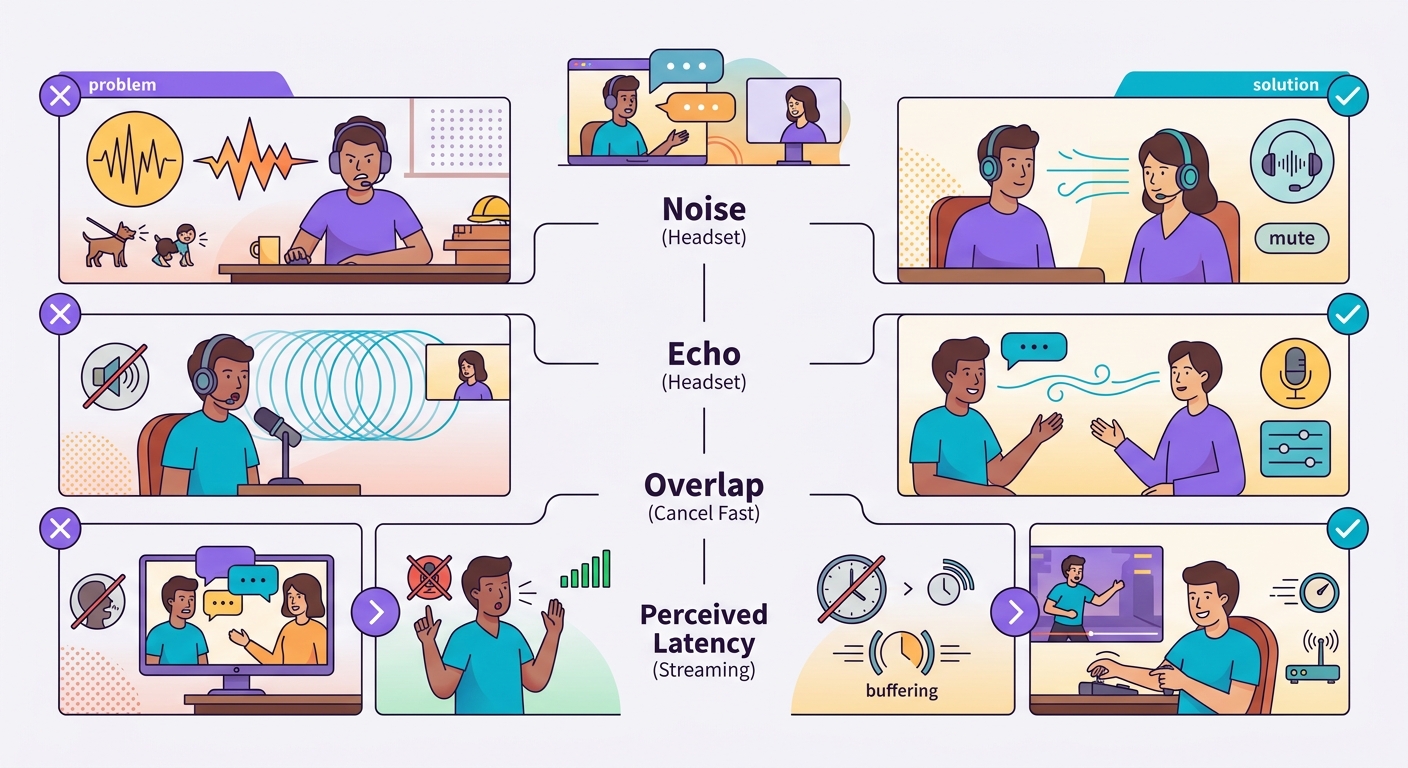
Armadilhas comuns
- Barulho de fundo: captura ambiente faz VAD falhar; use headset ou mic direcionado
- Eco do próprio TTS: se speaker é alto-falante do laptop, mic pode captar o TTS e transcrever de volta; use headset
- Overlap de fala: usuário interrompe, sistema demora a reagir = frustração; implementar cancelamento rápido
- Latência percebida vs real: latência de 1s parece ok em texto, parece lenta em voz; otimize para <500ms quando possível
Implementação básica no browser
Para experimentação rápida:
`javascript
// 1. Captura
const stream = await navigator.mediaDevices.getUserMedia({audio: true});
const mediaRecorder = new MediaRecorder(stream);
// 2. Envia chunks a cada 500ms
mediaRecorder.ondataavailable = async (e) => {
const formData = new FormData();
formData.append('file', e.data);
const r = await fetch('/api/transcribe', {method:'POST', body: formData});
const {text} = await r.json();
// 3. Envia para LLM, recebe resposta
// 4. Envia resposta para /api/tts, toca resultado
};
mediaRecorder.start(500);`
A Brainiall já oferece isso pronto no chat: clique no microfone e pressione-and-hold.
Teste agora mesmo
No chat Brainiall, clique no ícone de microfone e pressione-and-hold. Fale, solte, receba resposta em texto + áudio. Pro R$29 inclui voz completa; Business desbloqueia vozes premium + latência priority.