
Klonen Sie Ihre Stimme mit 10 Sekunden Audio
Warum 10 Sekunden heute ausreichen (vor 2 Jahren reichten sie nicht)
Bis 2023 erforderte das Klonen einer Stimme zwischen 30 Minuten und einigen Stunden sauberer Studioaufnahmen, bei denen ein spezifisches Korpus vorgelesen wurde. Heute erledigen Modelle wie Kokoro TTS und XTTS v2 dieselbe Aufgabe mit 6 bis 15 Sekunden Referenzaudio, in jedem halbwegs ruhigen Umfeld.
Was hat sich verändert? Die Architektur. Moderne Modelle trennen, was man sagt (Inhalt), von der Art, wie man es sagt (Klangfarbe, Prosodie, Rhythmus). Ein kleiner Encoder extrahiert Ihr „Stimmenprofil" in wenigen hundert Millisekunden; anschließend kann beliebiger Text unter Verwendung dieses Profils synthetisiert werden. Das Synthesemodell selbst weiß bereits, wie man Portugiesisch, Englisch oder eine andere Sprache spricht – es „malt" den Text lediglich mit Ihrer Stimme.
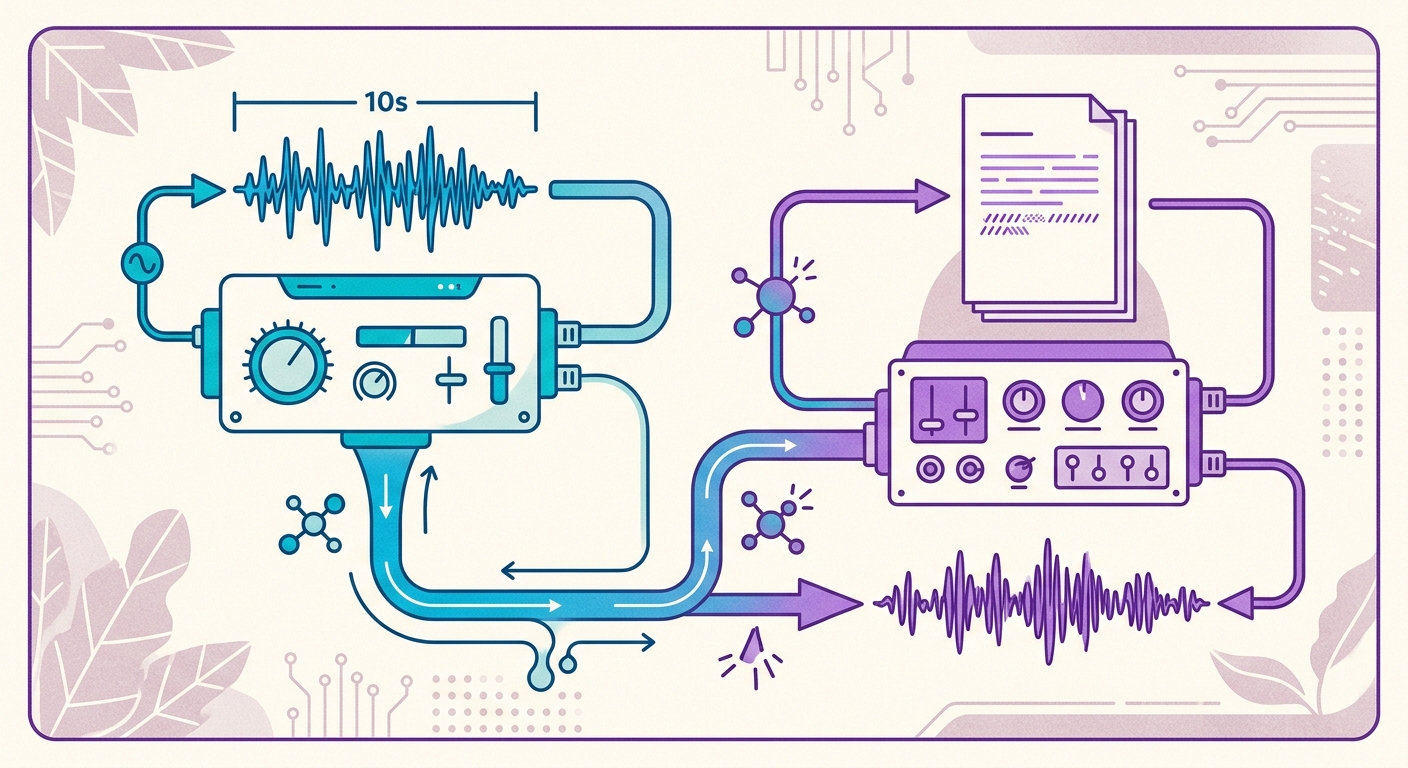
Die Brainiall-Pipeline in der Praxis
Bei Brainiall verwenden wir ein natives Sprachmodell, das auf einer dedizierten GPU läuft, mit 54 vortrainierten Stimmen in 9 Sprachen — darunter 3 neuronale Stimmen auf Brasilianischem Portugiesisch (pf_dora, pm_alex, pm_santa). Um eine neue Stimme zu klonen, läuft der Prozess wie folgt ab:
1. Sie nehmen 10 Sekunden auf, in denen Sie irgendetwas auf Portugiesisch sprechen (zum Beispiel, indem Sie diesen Absatz vorlesen)
2. Der Encoder extrahiert Ihr „Voice Embedding" — einen Vektor aus 512 Zahlen
3. Der Synthesizer erhält den Text, den Sie vertonen möchten, + Ihr Embedding
4. Sie erhalten eine MP3 innerhalb von 2-4 Sekunden zurück (Echtzeit < 1, das heißt, die Synthese ist schneller als das endgültige Audio)
Wenn es natürlich klingt, wenn es noch roboterhaft klingt
Funktioniert hervorragend wenn:
- Ihre Referenzaudio sauber ist (geringes Hintergrundrauschen, kein Echo)
- Sie in neutralem Ton sprechen, ohne Lachen oder extreme Ausrufe
- Der zu vertonende Text in derselben Sprache wie die Aufnahme ist
- Kurze bis mittellange Sätze (bis zu 30 Wörter pro Satz)
Schlägt noch fehl wenn:
- Sie sehr spezifische Emotionen verlangen (explosiver Zorn, Weinen)
- Der Text viele Fremdnamen oder seltene Fachbegriffe enthält
- Die ursprüngliche Aufnahme Umgebungsgeräusche hatte — das Modell kopiert das Rauschen mit
- Sehr lange Audios (>2 Minuten) beginnen prosodisch zu „driften
Die ethischen Grenzen (wichtig)
Stimmen ohne Einwilligung zu klonen ist ein ernstes rechtliches und ethisches Problem. Bei Brainiall:
- Geklonte Stimmen sind mit Ihrem Konto verknüpft und nur Sie können sie verwenden
- Wir klonen niemals Stimmen Dritter aus öffentlichen Audioaufnahmen ohne ausdrückliche Genehmigung des Inhabers
- Generierte Inhalte durchlaufen eine Moderation, bevor sie ausgeliefert werden (wir erkennen Versuche der politischen Imitation oder der Imitation von Prominenten)
- Sie können Ihr Voice Embedding jederzeit unter Meine Daten löschen (LGPD)
Voice Cloning hat leistungsstarke legitime Anwendungsfälle: Bücher in Ihrer eigenen Stimme zu vertonen, Inhalte in mehreren Sprachen zu erstellen und dabei Ihre Identität beizubehalten, sowie Barrierefreiheit für Menschen, die ihre Stimme verloren haben. Nutzen Sie es verantwortungsbewusst.
Teste jetzt gleich
Im Brainiall-Chat klicken Sie auf das Mikrofon im Eingabefeld, nehmen Sie 10 Sekunden auf (beliebiger Inhalt) und schreiben Sie anschließend einen Text zum Vorlesen. Das Klonen selbst ist bis zu 3 Versuche pro Monat kostenlos. Der Pro-Plan für €5,49 schaltet 100 Bilder und 10 Videos/Monat frei, zusätzlich zu den 54 fertigen Stimmen — viele davon klingen bereits natürlicher als eine von einem Laien geklonte Stimme.