
Finden Sie CPF, RG und E-Mail in Dokumenten automatisch
Was ist PII und warum verpflichtet dich die LGPD dazu, es zu finden
PII (Personally Identifiable Information) sind alle Daten, die eine Person identifizieren: Name, Steueridentifikationsnummer, Personalausweisnummer, E-Mail, Telefon, Adresse, Bankdaten, Foto, Biometrie. Gemäß der LGPD (Lei 13.709/2018) müssen Sie, wenn Sie PII brasilianischer Nutzer speichern, folgendes sicherstellen:
1. Wissen, wo jede PII gespeichert ist
2. Alle PII eines Nutzers auf Anfrage exportieren können (Art. 18)
3. Diese vollständig löschen, wenn der Nutzer das „Recht auf Vergessenwerden" beansprucht
4. Protokollieren, wer wann auf welche personenbezogenen Daten zugegriffen hat
Das Problem: PII verteilt sich auf Logs, E-Mails, Word-Dokumente, Support-Tickets, Screenshots, historische Datenbanken. PII manuell zu finden ist in einem Unternehmen mit mehr als 100 Mitarbeitern unmöglich.

Die spezifischen PII-Typen Brasiliens
Internationale NER-Modelle (Named Entity Recognition) erkennen Namen, E-Mail-Adressen, Telefonnummern und Adressen gut. Für Brasilien benötigen wir eine spezifische Erkennung:
- CPF: Format 000.000.000-00 oder 00000000000 + Validierung der Prüfziffern
- CNPJ: 00.000.000/0000-00 oder 14 Ziffern
- RG: Format variiert je nach Bundesstaat (SP: 00.000.000-0, andere Bundesstaaten unterschiedlich)
- CEP: 00000-000 oder 8 Ziffern
- Wählerausweis (Título de eleitor): 12 Ziffern
- PIS/PASEP: 11 Ziffern mit Validierung
- Führerschein (CNH): 11 Ziffern
Brainiall verwendet ein benutzerdefiniertes ONNX-Modell, das auf brasilianischen Dokumenten trainiert wurde, sowie validierte reguläre Ausdrücke (Regex), um diese Typen mit einer Genauigkeit von 98%+ zu erfassen.
Unterschied zwischen Erkennung und Anonymisierung
Erkennen ist nur der erste Schritt. Was danach zu tun ist, hängt vom Kontext ab:
- Reversible Anonymisierung: Ersetzen durch Token (z.B.
CPF_USR_42) mit Speicherung des Mappings in einem verschlüsselten Vault. Nützlich für aggregierte Analysen ohne Preisgabe der Identität. - Vollständige Schwärzung: Ersetzen durch
[REDACTED]. Nützlich für die externe Veröffentlichung von Logs oder Berichten. - Pseudonymisierung: Ersetzen durch einen plausiblen, aber falschen Wert (ungültige CPF mit korrektem Format). Nützlich für Testumgebungen.
- Löschung: Vollständiges Entfernen. Für GDPR/LGPD Art. 18-Anfragen.
Der Endpoint von Brainiall bietet alle 4 Modi über den Parameter mode an.
Integrieren mit Ihrer Pipeline
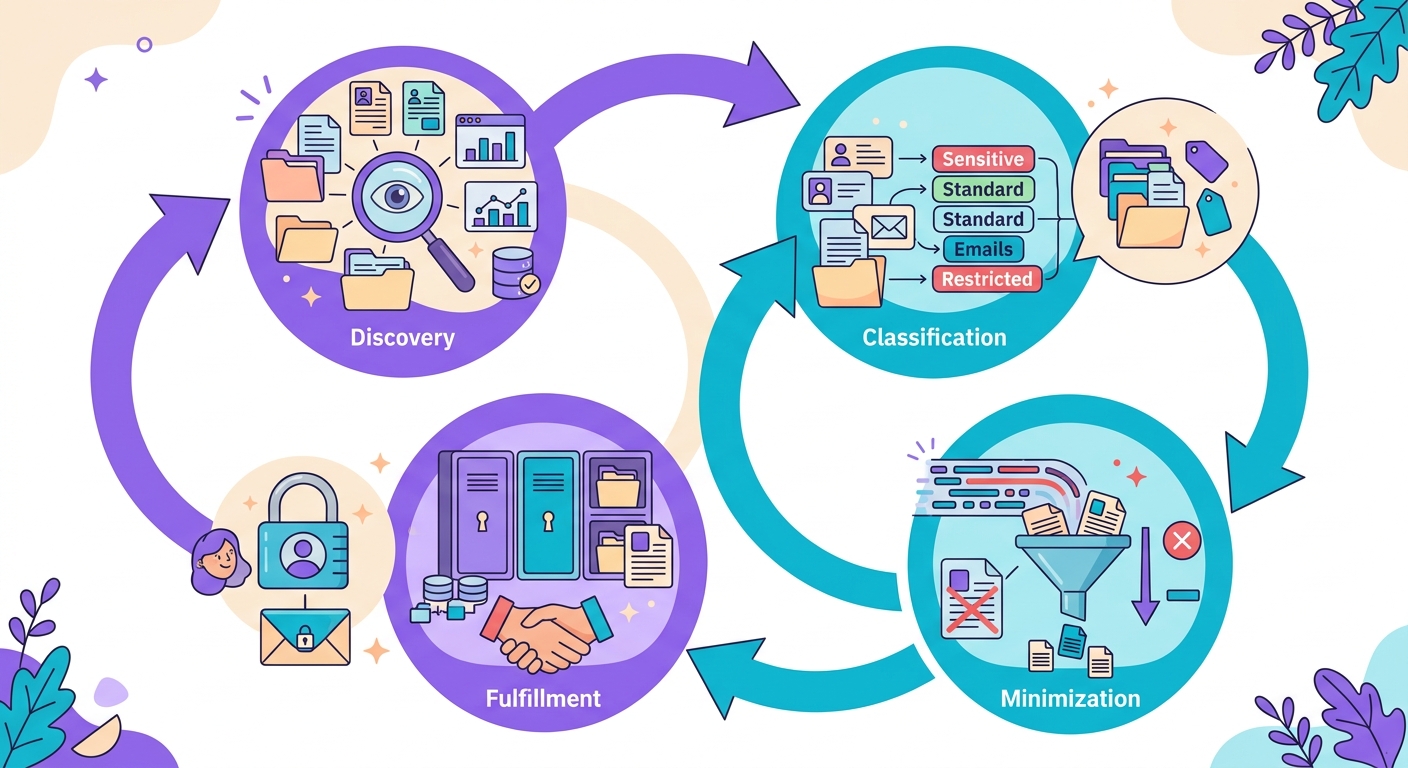
Typischer Ablauf in einem Unternehmen:
1. Discovery: periodischer (wöchentlicher) Scan aller Datenquellen — Datenbanken, S3, Logs, E-Mail
2. Klassifizierung: markieren, wo PII vorhanden ist, welcher Typ, Kritikalität
3. Minimierung: PII-Daten, die nicht mehr benötigt werden = löschen oder in verschlüsselten Cold Storage verschieben
4. Request fulfillment: wenn der Nutzer Export/Löschung anfordert, schnelle Lokalisierung über Index
Die Erkennungs-API ist nur eine Schicht dieser Pipeline. Sie benötigen außerdem eine Metadaten-Infrastruktur, ein Audit-Log und ein Mapping.
Häufige Fallstricke
- Falsche Positive: Eine zufällige Telefonnummer in einem Text über "Leitung 555-1234" kann als echte Telefonnummer markiert werden
- Kontext ist wichtig: "meine CPF ist 000.000.000-00" vs. "das Dokument listete anonyme CPFs auf" — das zweite ist keine echte PII
- Base64: In kodierten Strings versteckte PII wird ohne vorherige Dekodierung nicht erkannt
- OCR-Fehler: Gescannte CPFs mit vertauschten Zeichen (O statt 0) bleiben unbemerkt
- Zusammengesetzte Namen: "Maria dos Santos" ist einfach; "José" allein kann nur ein gewöhnliches Wort sein
Teste jetzt gleich
Im Brainiall-Chat bitten Sie um „PII in diesem Text erkennen: [Inhalt einfügen]". Oder über API unter /api/nlp/pii. Für unternehmensweite Compliance bietet Business €18 Batch-API + Audit-Log-Aufbewahrung für 12 Monate.