
GPT-5 vs Claude Sonnet vs Gemini 3 Pro: Welches sollte man wählen?
Die Wahl des Modells ist wichtiger als Sie denken
Im Jahr 2026 ist der Unterschied zwischen Top-Tier-Modellen bei spezifischen Aufgaben deutlich spürbar. Darauf zu verzichten, 2-3 Optionen zu testen, und direkt mit dem bekanntesten (GPT) zu arbeiten, kann 2-3x mehr Tokens kosten oder in Ihrem spezifischen Fall 20% schlechtere Ergebnisse liefern.
Die 3 dominanten Modelle in Brainiall:
- Claude Sonnet 4.6 (Anthropic): am besten für komplexes Denken, lange Texte, Code
- GPT-5 (OpenAI): am besten für Multimodal (Bild+Text+Code), Kreativität
- Gemini 3 Pro (Google): am besten für riesige Kontexte (1M+ Tokens), niedrige Latenz
Reale Kosten im Jahr 2026 (pro Million Token)
| Modell | Input | Output | Hinweise |
|--------|-------|--------|---------|
| Claude Sonnet 4.6 | R$ 15 | R$ 75 | Cache-Treffer reduziert Input um das 10-fache |
| GPT-5 | R$ 12 | R$ 60 | Günstiger pro Token |
| Gemini 3 Pro | R$ 7 | R$ 35 | Bestes Preis-Leistungs-Verhältnis |
| Claude Haiku 4.5 | R$ 2 | R$ 10 | Schnell, gut für einfache Aufgaben |
Für einen durchschnittlichen Konversations-Chatbot (100 Nachrichten, ~500 Token jeweils) belaufen sich die täglichen Kosten auf R$ 10-50. Für Batch-Anwendungen (Analyse von 10.000 Dokumenten) steigen sie auf R$ 500-2000.
Wann welches verwendet werden sollte
Claude Sonnet 4.6 für:
- Verfassen langer Dokumente (Berichte, Aufsätze, juristische Analysen)
- Code Review und Refactoring
- Nuancenanalyse in Texten (Literatur, Philosophie)
- Aufgaben, die das Befolgen komplexer Anweisungen erfordern
- Agenten mit langen Reasoning-Ketten
GPT-5 für:
- Offene kreative Antworten (Brainstorming, Drehbücher)
- Multimodal, wo Bild + Text wichtig sind
- Schnelle und direkte Antworten
- Fälle, in denen Sie das „generischste Modell überhaupt" wünschen
- Standard Python- und JavaScript-Code
Gemini 3 Pro für:
- Verarbeitung sehr großer Dokumente (Bücher, gesamte Codebasen)
- Anwendungen mit kritischer Latenz (<1s)
- Videoanalyse (natives multimodales Video)
- Wissenschaftliche und mathematische Aufgaben
- Produktion im großen Maßstab, bei der Kosten eine Rolle spielen
Testen Sie Ihren Anwendungsfall mit 3 identischen Pipelines
Vertrauen Sie keinen generischen Benchmarks. Erstellen Sie Ihr eigenes Eval:
1. Wählen Sie 20 repräsentative Beispiele aus Ihrem tatsächlichen Anwendungsfall
2. Führen Sie denselben Prompt bei allen 3 Modellen aus
3. Bewerten Sie die Antworten blind (ohne zu wissen, welche welche ist)
4. Messen Sie: Accuracy, Latenz, Kosten
Oft ist das in generischen Benchmarks „schlechteste" Modell das beste für Ihren Fall, weil Ihre Aufgabe spezifische Eigenschaften hat, die der Benchmark nicht erfasst.
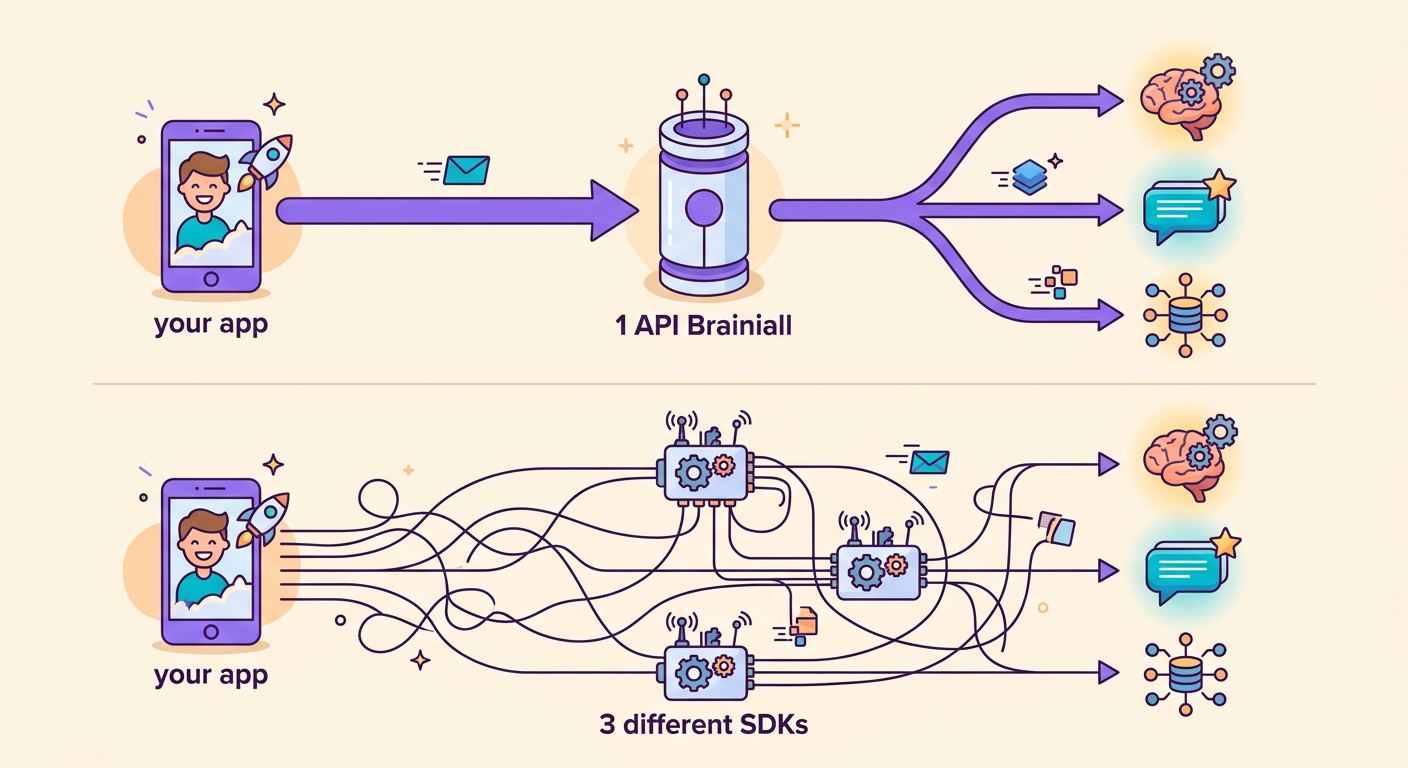
Verwendung über Brainiall
Der große Vorteil unseres Gateways: Sie wechseln das Modell, indem Sie 1 String ändern.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Erkläre Entropie in 3 Sätzen."))`
Ohne Brainiall bräuchten Sie 3 Konten, 3 SDKs, 3 separate Abrechnungen. Mit einem einzigen Gateway ist es transparent.
Fallen beim Vergleichen
- Nicht neutraler Prompt: Wenn Ihr Prompt für GPT optimiert wurde, kann Claude unfairerweise schlechter abschneiden
- Nur ein Beispiel: Die Variabilität zwischen Runs ist hoch; führen Sie mindestens N=20+ durch
- Falsche Metrik: Nur Accuracy zu messen ignoriert Kosten/Latenz/Robustheit
- Cache ignorieren: Claude hat einen Prompt-Cache, der die Kosten für wiederholte Systeme um das 10-fache reduziert
- Kein Testen auf PT-BR: Alle sind gut auf Englisch; auf PT-BR ist der Unterschied größer
Teste jetzt gleich
Im Brainiall-Chat wählen Sie ein Modell im oberen Dropdown aus und stellen Sie Ihre Frage. Wechseln Sie zu einem anderen Modell und vergleichen Sie. Pro für €5,49 gibt Zugang zu 15 Modellen; Business schaltet alle frei.