
Erkennen Sie Toxizität in Kommentaren mit KI
Die Apokalypse Perspective: was geschah
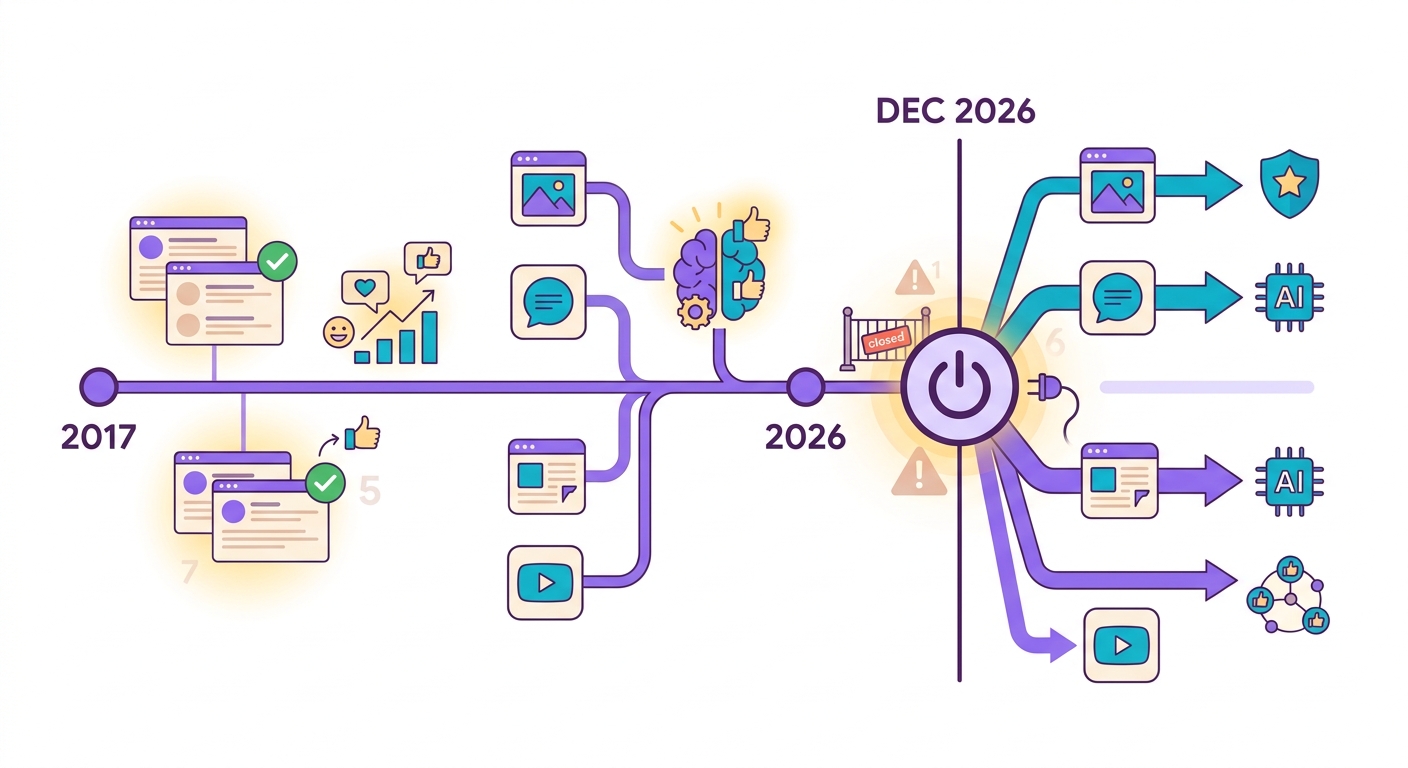
Im Oktober 2024 kündigte Google an, dass die Perspective API — der weltweit meistgenutzte kostenlose Toxizitätserkennungsdienst — im Dezember 2026 eingestellt wird. Plattformen, die davon abhängig waren (Reddit, New York Times, The Guardian, Tausende von Foren), haben 2 Jahre Zeit für die Migration.
Das Problem: Perspective war kostenlos. Kommerzielle Alternativen wie Azure Content Safety und AWS Comprehend berechnen ab US$ 1 pro 1.000 Analysen. Für ein großes Forum mit 100.000 Kommentaren/Tag werden daraus allein für die Moderation 3.000 $/Monat.
Brainiall bietet Moderation mit Detoxify + Unitary Modellen an, die lokal in ONNX (CPU) laufen und weniger als R$ 0,001 pro Analyse kosten — 100-mal günstiger.
Die 7 Kategorien, die wichtig sind
Detoxify klassifiziert Text in 7 Dimensionen mit einem Score von 0 bis 1:
1. Toxicity: allgemeine Beleidigung, Aggressivität
2. Severe toxicity: Bedrohung, extremer Hass
3. Obscene: Schimpfwörter und vulgäre Sprache
4. Threat: Androhung physischer Gewalt
5. Insult: direkter persönlicher Angriff
6. Identity hate: gruppenbasierte Diskriminierung (Rasse, Geschlecht, Religion)
7. Sexual explicit: sexuell explizite Inhalte
Ihre Policy legt die Thresholds fest. Gängiges Beispiel: blockieren, wenn severe_toxicity > 0,5 ODER identity_hate > 0,6 ODER threat > 0,3. Einzelne Schimpfwörter (obscene > 0,8) werden in der Regel mit einer Warnung durchgelassen, nicht blockiert.
Das Problem mit PT-BR
Detoxify wurde auf Englisch trainiert. Es funktioniert zu 95%+ bei englischen Kommentaren. Bei brasilianischem Portugiesisch sinkt die Genauigkeit auf 75-85% — die regionalen Ausdrücke und spezifischen Slangbegriffe (viele davon nicht beleidigend) verwirren das Modell.
Bei Brainiall verwenden wir eine zusätzliche Schicht: einen hybriden Klassifikator, der Folgendes kombiniert:
- Detoxify multilingual (70% der Entscheidung)
- Liste spezifischer PT-BR-Wörter (20%)
- LLM small (Gemma 3 oder ähnlich) für Grenzfälle (10%)
Dies erhöht die Genauigkeit auf 92%+ in PT-BR bei einer Latenz von < 80ms.
Wenn die KI gefährlich irrt
- Sarkasmus: "Ich liebte es, wie du mein Leben ruiniert hast, danke!" — positiver Score, aber der Text ist feindselig
- Legitime Satire: humoristische politische Kritik kann als Angriff markiert werden
- Medizinischer Kontext: "Ich werde den Patienten durch so viel Arbeit umbringen" (erschöpfter Gesundheitsarbeiter) — falsches positives Flag
- Zitate: Ein Artikel, der einen rassistischen Beitrag zitiert, um ihn zu kritisieren, wird wie der rassistische Beitrag selbst analysiert
- Code-switching: Wer Englisch + Portugiesisch + Emojis mischt, verwirrt das Modell
Praktische Lösung: Kombinieren Sie den automatischen Score mit Soft-Moderation (Bestätigung vor der Veröffentlichung anfordern) anstelle von Hard-Block bei Grenzfällen.
Integrando in Ihre Plattform
Empfohlener Ablauf:
1. Benutzer gibt Kommentar ein → fetch POST /api/toxicity mit { text }
2. API gibt zurück { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Ihr Code entscheidet: blockieren, warnen oder genehmigen
4. Bei Warnung wird vor der Veröffentlichung angezeigt: „Überprüfen – könnte einige Benutzer beleidigen"
5. Bei Blockierungen: Log + Benachrichtigung der menschlichen Moderation
Führen Sie keine 100% automatische Moderation durch. Halten Sie immer eine menschliche Warteschlange für Grenzfälle bereit.
Teste jetzt gleich
Im Brainiall-Chat fragen Sie "analysiere die Toxizität dieses Kommentars: [hier einfügen]". Oder über die API unter der Route /api/nlp/toxicity. Der Pro-Plan für €5,49 umfasst 10.000 Analysen/Monat; Business hat Priority-Warteschlange + Batch von Millionen.