
Narra cualquier texto en 9 idiomas con 54 voces neurales
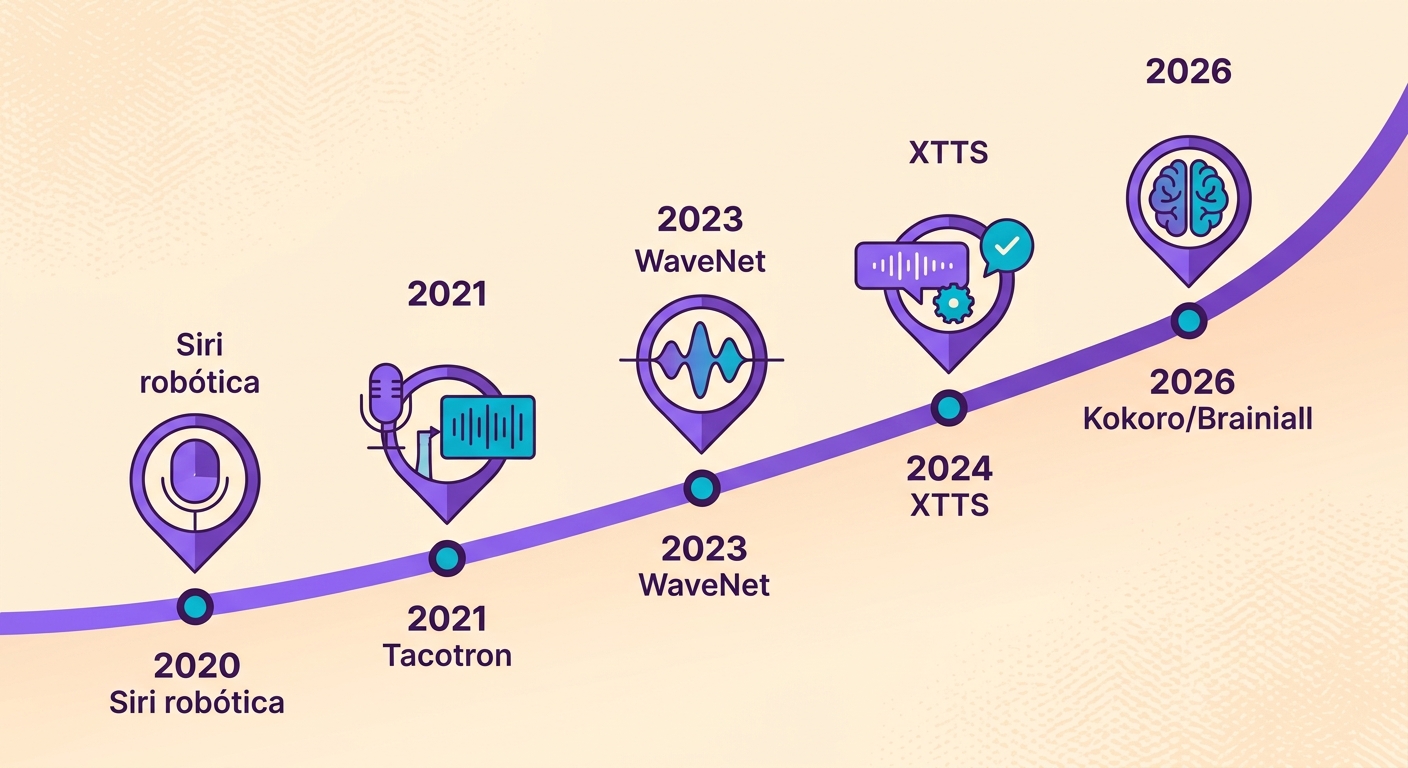
La evolución del TTS en 5 años
Hasta 2020, el Text-to-Speech sonaba robótico — la era de la Siri original. Entre 2021 y 2023, aprendimos a usar modelos WaveNet y Tacotron para lograr una voz natural. A partir de 2024, modelos de una escala completamente nueva (XTTS, Kokoro, VALL-E) trajeron tres avances decisivos:
1. Tamaño reducido: Kokoro tiene apenas 82 millones de parámetros — 100× más pequeño que los gigantes de antes, con la misma calidad
2. Inferencia en tiempo real: RTF (Real-Time Factor) < 0.2 en una GPU de entrada; es decir, 1 minuto de audio se sintetiza en menos de 12 segundos
3. Prosodia natural: entonación, énfasis, ritmo — nada de ese tono "monótono con coma"
Los 9 idiomas de Brainiall
- Portugués brasileño: pf_dora (femenina adulta), pm_alex, pm_santa (masculinas)
- Inglés americano: af_heart, af_bella, af_nicole, am_adam, am_michael
- Inglés británico: bf_emma, bm_george, bm_lewis
- Español: ef_lucia, em_carlos
- Francés: ff_juliette, fm_louis
- Alemán: gf_sophia, gm_max
- Italiano: if_chiara, im_marco
- Chino mandarín: zf_mei, zm_wei
- Japonés: jf_haruka, jm_kenji
Cada voz tiene su propia personalidad: pf_dora es clara y educativa (la usamos en los cursos de Brainiall Academy), am_adam tiene un perfil profesional corporativo y af_heart transmite un tono más emocional.
Cómo elegir la voz adecuada según el contexto
- E-learning / tutoriales: voces neutras y bien articuladas (pf_dora, am_adam)
- Marketing / anuncios: voces más dinámicas y expresivas (af_heart, am_michael)
- Audiolibros: voces cálidas y narrativas (af_bella, bm_george)
- Noticias: voces formales y claras (pm_santa, am_adam)
- Chatbots / asistentes: voces amigables y ágiles (af_nicole, pm_alex)
Consejo práctico: genera 3-5 segundos de prueba con 3 voces candidatas antes de sintetizar un texto largo. La preferencia siempre es subjetiva.
Control de velocidad y tono
Los parámetros más útiles:
- speed: de 0.25 a 4.0 — valor por defecto 1.0. Usa 0.85 para audiolibros (narración tranquila), 1.15 para contenido educativo, 1.3+ solo para vistas previas rápidas
- format: mp3, wav, ogg. MP3 es el formato por defecto (mejor compresión); WAV cuando vayas a editar el audio después; OGG para streaming web
- pitch: algunos modelos lo admiten, ajústalo en semitonos (-5 a +5)
Evita los extremos: con speed > 2.0 el audio se vuelve incomprensible, y con < 0.5 suena artificial.
Límites técnicos y de uso
- Máximo por solicitud: 4000 caracteres — aproximadamente 4 párrafos. Los textos largos requieren chunking
- Idiomas mezclados: cada voz rinde mejor en su idioma principal; mezclar (por ejemplo, texto en español con palabras en inglés) puede generar una pronunciación vacilante
- Nombres propios extranjeros: escríbelos fonéticamente en el prompt — "Maicrosoft" en lugar de "Microsoft"
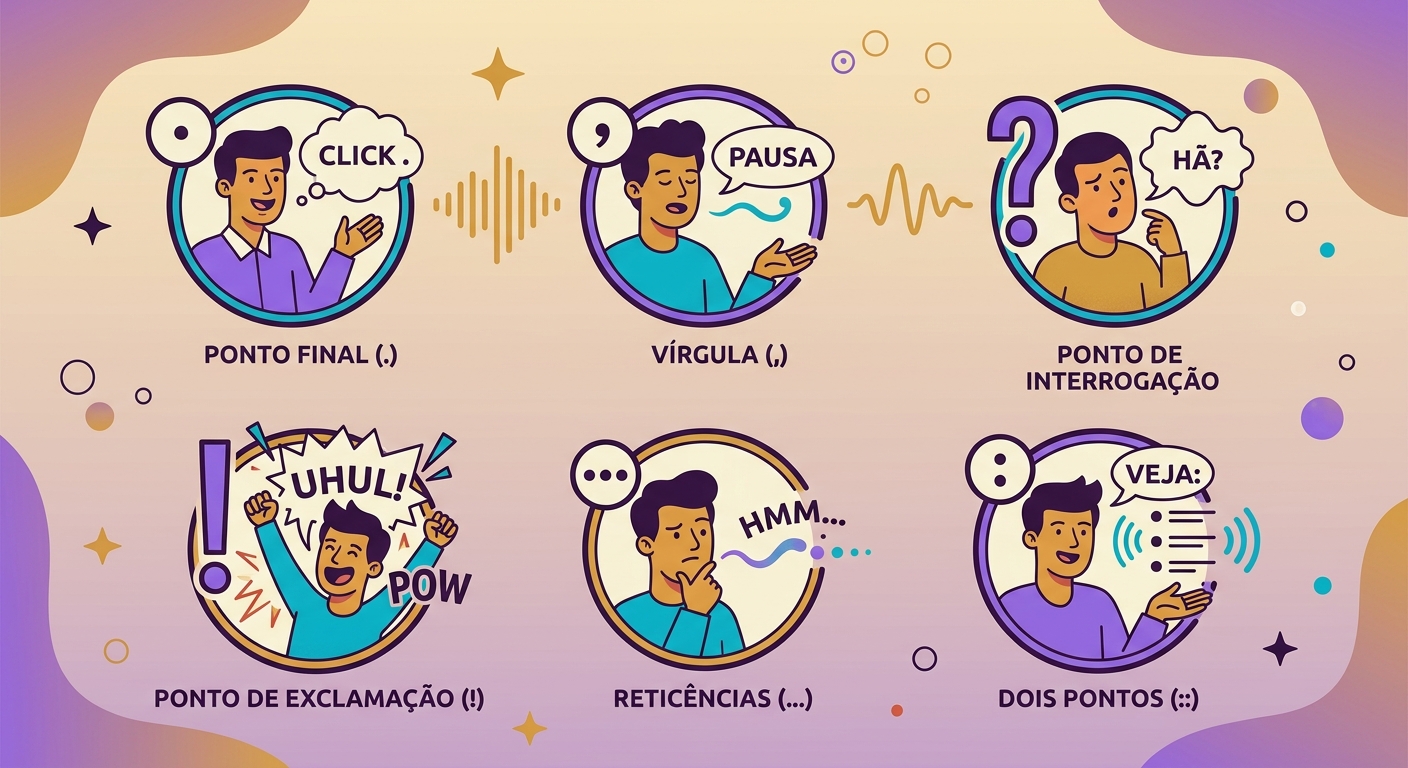
- La puntuación importa: comas = pausa corta, puntos suspensivos = pausa larga, punto final = caída de tono
- Emojis: la mayoría de los modelos los ignora o los lee como palabra ("sonriendo") — elimínalos antes de sintetizar
Casos de uso prácticos
- Narración de cursos: como hacemos en la Academy — rápido, económico y consistente
- Audiolibros caseros: convierte PDFs/EPUBs en MP3 para escuchar en el coche
- Accesibilidad: convierte tu blog en audio para lectores con dificultades de lectura
- Podcasts automáticos: transforma newsletters en formato podcast para su distribución
- Voz para videos: reemplaza el costoso voice-over por TTS cuando el timing no es crítico
Pruébalo ahora mismo
En el chat de Brainiall, envía un mensaje y haz clic en el ícono 🔊 de la respuesta para escucharlo con TTS. También puedes hacerlo a través de la ruta /api/tts vía API. El plan Pro permite un uso generoso de TTS; el plan Business incluye créditos API para integraciones externas.