
Narrez n'importe quel texte en 9 langues avec 54 voix neurales
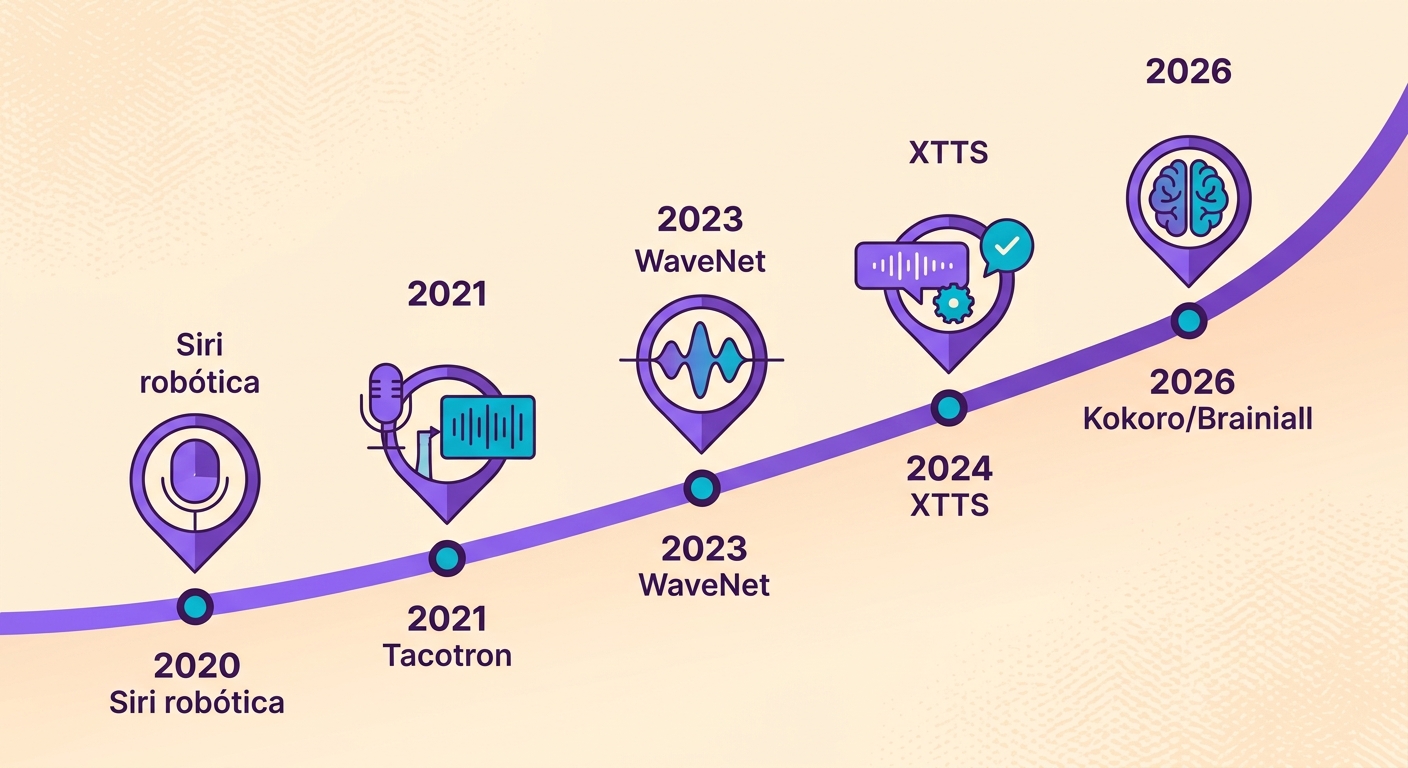
L'évolution du TTS en 5 ans
Jusqu'en 2020, le Text-to-Speech sonnait robotique — c'était l'ère de la Siri originale. De 2021 à 2023, nous avons appris à utiliser les modèles WaveNet et Tacotron pour atteindre une voix naturelle. À partir de 2024, des modèles d'une toute nouvelle envergure (XTTS, Kokoro, VALL-E) ont apporté trois avancées décisives :
1. Taille réduite : Kokoro ne compte que 82 millions de paramètres — 100× plus petit que les anciens géants, pour une qualité identique
2. Inférence en temps réel : RTF (Real-Time Factor) < 0.2 sur un GPU d'entrée de gamme ; autrement dit, 1 minute d'audio est synthétisée en moins de 12 secondes
3. Prosodie naturelle : intonation, emphase, rythme — fini le "monotone avec virgule"
Les 9 langues de Brainiall
- Portugais brésilien : pf_dora (féminine adulte), pm_alex, pm_santa (masculines)
- Anglais américain : af_heart, af_bella, af_nicole, am_adam, am_michael
- Anglais britannique : bf_emma, bm_george, bm_lewis
- Espagnol : ef_lucia, em_carlos
- Français : ff_juliette, fm_louis
- Allemand : gf_sophia, gm_max
- Italien : if_chiara, im_marco
- Chinois mandarin : zf_mei, zm_wei
- Japonais : jf_haruka, jm_kenji
Chaque voix a sa propre personnalité : pf_dora est claire et pédagogique (nous l'utilisons dans les cours de la Brainiall Academy), am_adam est professionnel et corporate, af_heart a une tonalité plus émotionnelle.
Comment choisir la bonne voix selon le contexte
- E-learning / tutoriels : voix neutres et bien articulées (pf_dora, am_adam)
- Marketing / publicités : voix dynamiques et expressives (af_heart, am_michael)
- Livres audio : voix chaleureuses et narratives (af_bella, bm_george)
- Actualités : voix formelles et claires (pm_santa, am_adam)
- Chatbots / assistants : voix conviviales et fluides (af_nicole, pm_alex)
Conseil pratique : générez 3 à 5 secondes de test avec 3 voix candidates avant de synthétiser un texte long. La préférence reste toujours subjective.
Contrôler la vitesse et le ton
Les paramètres les plus utiles :
- speed : de 0.25 à 4.0 — valeur par défaut 1.0. Utilisez 0.85 pour les livres audio (narration apaisée), 1.15 pour le contenu éducatif, 1.3+ uniquement pour des aperçus rapides
- format : mp3, wav, ogg. MP3 est la valeur par défaut (meilleure compression) ; WAV si vous comptez éditer l'audio ensuite ; OGG pour le streaming web
- pitch : certains modèles l'acceptent, ajustez en demi-tons (-5 à +5)
Évitez les extrêmes : speed > 2.0 devient incompréhensible, < 0.5 sonne artificiel.
Limites techniques et d'utilisation
- Maximum par requête : 4 000 caractères — soit environ 4 paragraphes. Les textes longs nécessitent un découpage (chunking)
- Langues mixtes : chaque voix excelle dans sa langue principale ; mélanger les langues (ex : texte en portugais avec des mots en anglais) peut produire une prononciation hésitante
- Noms propres étrangers : écrivez-les phonétiquement dans le prompt — "Maïcrosoft" plutôt que "Microsoft"
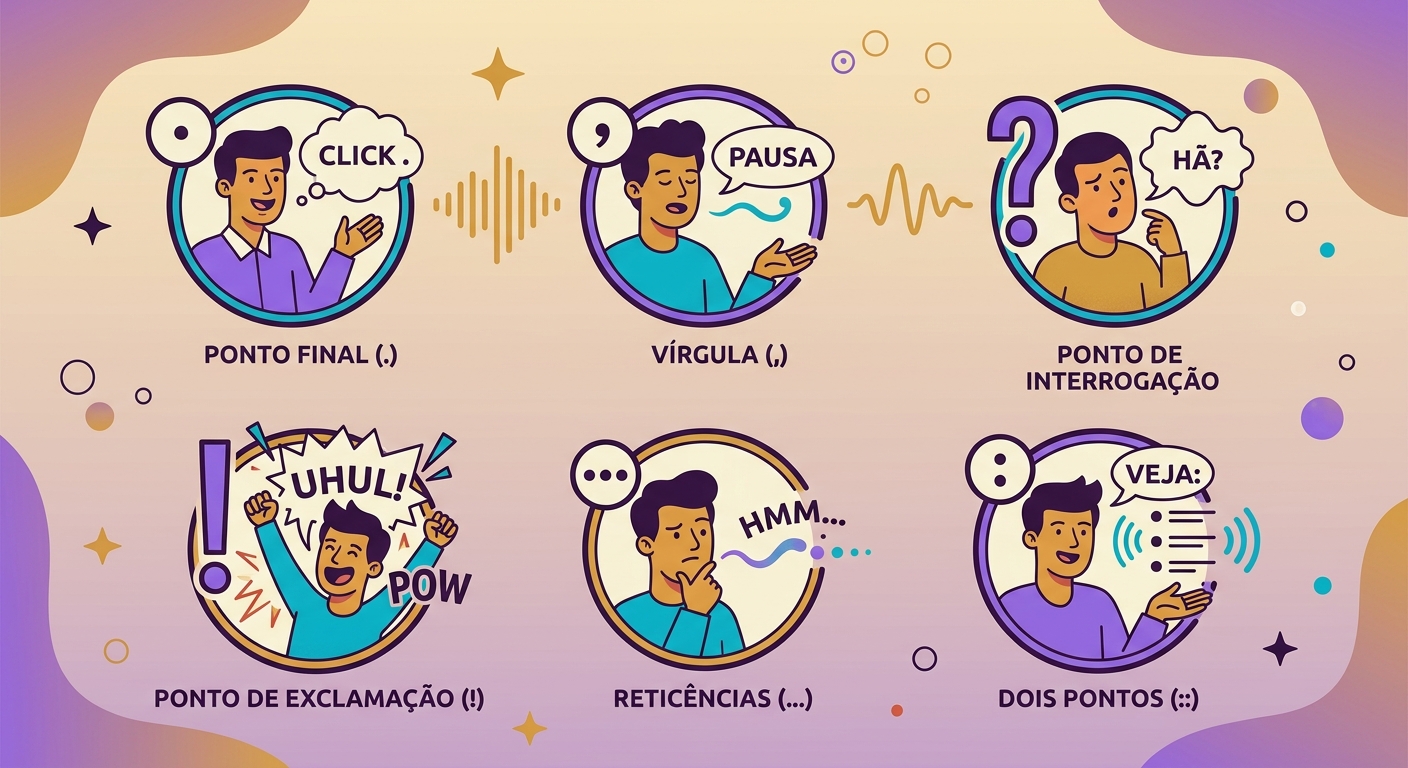
- La ponctuation compte : virgule = pause courte, points de suspension = pause longue, point final = baisse de ton
- Emojis : la plupart des modèles les ignorent ou les lisent comme un mot ("souriant") — supprimez-les avant la synthèse
Cas d'usage concrets
- Narration de cours : comme nous le faisons à l'Academy — rapide, économique et cohérent
- Livres audio maison : convertissez vos PDF/EPUB en MP3 pour les écouter en voiture
- Accessibilité : transformez votre blog en audio pour les lecteurs ayant des difficultés de lecture
- Podcasts automatiques : convertissez vos newsletters en format podcast pour la distribution
- Voix pour vidéos : remplacez la voix off coûteuse par du TTS lorsque le timing n'est pas critique
Testez dès maintenant
Dans le chat Brainiall, envoyez un message et cliquez sur l'icône 🔊 dans la réponse pour l'écouter avec TTS. Ou via la route /api/tts par API. Le plan Pro à 29 R$ offre une utilisation généreuse du TTS ; le plan Business à 99 R$ inclut des crédits API pour les intégrations externes.