
Kloning suara Anda hanya dengan 10 detik audio
Mengapa 10 detik sudah cukup sekarang (dulu tidak bisa)
Hingga tahun 2023, mengkloning suara membutuhkan 30 menit hingga beberapa jam rekaman bersih di studio, dengan membaca korpus tertentu. Kini, model seperti Kokoro TTS dan XTTS v2 melakukan hal yang sama hanya dengan 6 hingga 15 detik audio referensi, di lingkungan mana pun yang cukup tenang.
Apa yang berubah? Arsitekturnya. Model modern memisahkan apa yang Anda ucapkan (konten) dari cara Anda mengucapkannya (timbre, prosodi, ritme). Sebuah encoder kecil mengekstrak "profil vokal" Anda dalam beberapa ratus milidetik; setelah itu, teks apa pun dapat disintesis menggunakan profil tersebut. Model sintesis itu sendiri sudah tahu cara berbicara dalam bahasa Indonesia, Inggris, atau bahasa lainnya — ia hanya "mewarnai" teks dengan suara Anda.
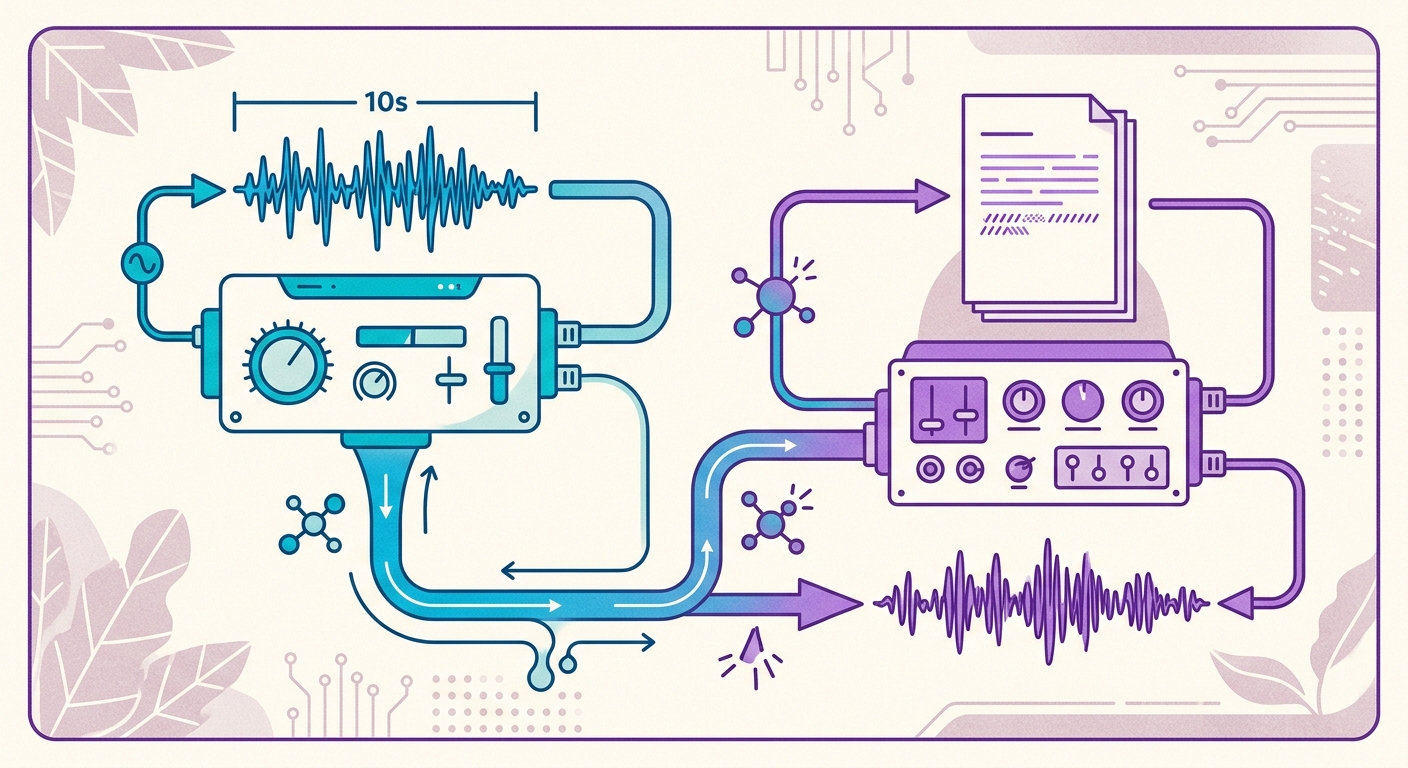
Pipeline Brainiall dalam praktiknya
Di Brainiall, kami menggunakan model suara native yang berjalan di GPU khusus, dengan 54 suara yang telah dilatih dalam 9 bahasa — termasuk 3 suara neural dalam bahasa Indonesia. Untuk mengkloning suara baru, alurnya adalah:
1. Anda merekam 10 detik berbicara apa saja dalam bahasa Indonesia (misalnya, membaca paragraf ini)
2. Encoder mengekstrak "voice embedding" Anda — sebuah vektor berisi 512 angka
3. Synthesizer menerima teks yang ingin Anda narasikan + embedding Anda
4. Anda menerima file MP3 dalam 2–4 detik (waktu nyata < 1, artinya sintesis lebih cepat dari durasi audio akhir)
Kapan hasilnya natural, kapan masih terdengar robotik
Hasilnya sangat baik ketika:
- Audio referensi Anda bersih (kebisingan latar belakang rendah, tanpa gema)
- Anda berbicara dengan nada netral, tanpa tawa atau ekspresi berlebihan
- Teks yang dinarasikan menggunakan bahasa yang sama dengan sampel
- Kalimat pendek hingga sedang (maksimal 30 kata per kalimat)
Masih kurang optimal ketika:
- Anda meminta emosi yang sangat spesifik (kemarahan meledak-ledak, tangisan)
- Teks mengandung banyak nama asing atau jargon teknis yang jarang digunakan
- Sampel asli memiliki kebisingan latar — model ikut menyalin kebisingan tersebut
- Audio yang sangat panjang (>2 menit) mulai mengalami "drift" secara prosodik
Batas-batas etis (penting)
Mengkloning suara tanpa persetujuan adalah masalah hukum dan etika yang serius. Di Brainiall:
- Suara yang dikloning terhubung ke akun Anda dan hanya Anda yang dapat menggunakannya
- Kami tidak pernah mengkloning suara pihak ketiga dari audio publik tanpa izin eksplisit dari pemiliknya
- Konten yang dihasilkan melalui moderasi sebelum dikirimkan (kami mendeteksi upaya peniruan tokoh politik atau selebriti)
- Anda dapat menghapus voice embedding Anda kapan saja di Data Saya
Voice cloning memiliki kegunaan yang sah dan powerful: menarasikan buku dengan suara Anda sendiri, membuat konten dalam berbagai bahasa sambil mempertahankan identitas Anda, serta aksesibilitas bagi mereka yang kehilangan kemampuan berbicara. Gunakan dengan penuh tanggung jawab.
Coba sekarang juga
Di chat Brainiall, klik ikon mikrofon di kolom input, rekam 10 detik (konten apa saja), lalu ketik teks yang ingin dinarasikan. Kloning suara itu sendiri gratis hingga 3 kali percobaan per bulan. Paket Pro membuka akses ke 100 gambar dan 10 video per bulan, ditambah 54 suara siap pakai — banyak di antaranya sudah terdengar lebih natural dibandingkan suara kloning dari rekaman amatir.