
Tự động tìm CPF, RG và email trong tài liệu
PII là gì và tại sao LGPD bắt buộc bạn phải tìm kiếm nó
PII (Personally Identifiable Information) là bất kỳ dữ liệu nào có thể xác định danh tính một người: tên, CPF, RG, email, số điện thoại, địa chỉ, thông tin ngân hàng, ảnh, dữ liệu sinh trắc học. Theo LGPD (Luật 13.709/2018), nếu bạn lưu trữ PII của người dùng Brazil, bạn cần:
1. Biết nơi mỗi PII được lưu trữ
2. Có khả năng xuất toàn bộ PII của một người dùng theo yêu cầu (điều 18)
3. Xóa hoàn toàn khi người dùng yêu cầu "quyền được quên"
4. Kiểm tra ai đã truy cập từng dữ liệu cá nhân và khi nào
Vấn đề: PII thường bị phân tán trong log, email, tài liệu Word, ticket hỗ trợ, ảnh chụp màn hình, cơ sở dữ liệu lịch sử. Tìm PII thủ công là điều không thể đối với công ty có hơn 100 nhân viên.

Các loại PII đặc thù của Brazil
Các mô hình NER (Named Entity Recognition) quốc tế nhận diện tốt tên, email, số điện thoại, địa chỉ. Đối với Brazil, chúng ta cần nhận diện đặc thù:
- CPF: định dạng 000.000.000-00 hoặc 00000000000 + xác thực chữ số kiểm tra
- CNPJ: 00.000.000/0000-00 hoặc 14 chữ số
- RG: định dạng thay đổi theo bang (SP: 00.000.000-0, các bang khác khác nhau)
- CEP: 00000-000 hoặc 8 chữ số
- Số thẻ cử tri: 12 chữ số
- PIS/PASEP: 11 chữ số có xác thực
- Bằng lái xe (CNH): 11 chữ số
Brainiall sử dụng mô hình ONNX tùy chỉnh được huấn luyện trên tài liệu Brazil kết hợp với regex đã được xác thực để nắm bắt các loại này với độ chính xác 98%+.
Sự khác biệt giữa phát hiện và ẩn danh hóa
Phát hiện chỉ là bước đầu tiên. Việc xử lý tiếp theo phụ thuộc vào ngữ cảnh:
- Ẩn danh hóa có thể đảo ngược: thay thế bằng token (ví dụ:
CPF_USR_42) và giữ ánh xạ trong vault được mã hóa. Hữu ích cho phân tích tổng hợp mà không lộ danh tính. - Biên tập hoàn toàn: thay thế bằng
[REDACTED]. Hữu ích khi xuất bản log hoặc báo cáo ra bên ngoài. - Giả danh hóa: thay thế bằng giá trị hợp lý nhưng giả (CPF không hợp lệ với định dạng đúng). Hữu ích cho môi trường kiểm thử.
- Xóa bỏ: xóa hoàn toàn. Dành cho các yêu cầu theo GDPR/LGPD điều 18.
Endpoint của Brainiall cung cấp cả 4 chế độ thông qua tham số mode.
Tích hợp vào pipeline của bạn
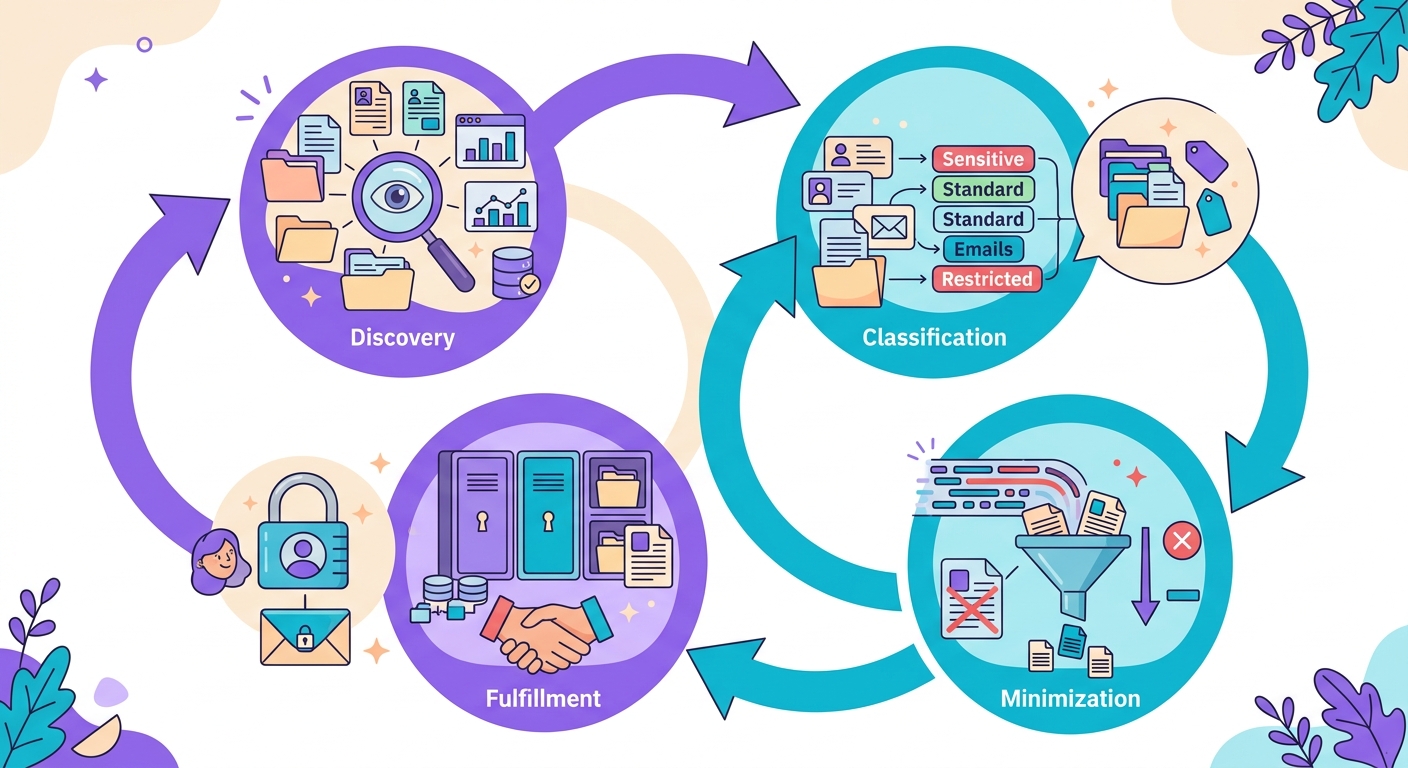
Quy trình điển hình trong doanh nghiệp:
1. Khám phá: quét định kỳ (hàng tuần) trên tất cả các nguồn dữ liệu — cơ sở dữ liệu, S3, log, email
2. Phân loại: đánh dấu vị trí PII, loại và mức độ nghiêm trọng
3. Tối thiểu hóa: PII không còn cần thiết = xóa hoặc chuyển sang cold storage được mã hóa
4. Xử lý yêu cầu: khi người dùng yêu cầu xuất/xóa, định vị nhanh qua index
API phát hiện chỉ là một lớp trong pipeline này. Bạn cũng cần hạ tầng metadata, audit log và bản đồ dữ liệu.
Những cạm bẫy thường gặp
- Dương tính giả: số điện thoại ngẫu nhiên trong văn bản về "đường dây 555-1234" có thể bị đánh dấu là số điện thoại thật
- Ngữ cảnh quan trọng: "CPF của tôi là 000.000.000-00" so với "tài liệu liệt kê các CPF ẩn danh" — trường hợp thứ hai không phải PII thật
- Base64: PII ẩn trong các chuỗi được mã hóa sẽ không được phát hiện nếu không giải mã trước
- Lỗi OCR: CPF được quét với ký tự bị nhầm (chữ O thay vì số 0) sẽ bị bỏ qua
- Tên ghép: "Maria dos Santos" dễ nhận diện; "José" đứng một mình có thể chỉ là một từ thông thường
Dùng thử ngay bây giờ
Trong chat Brainiall, hãy yêu cầu "phát hiện PII trong văn bản này: [dán nội dung]". Hoặc qua API tại /api/nlp/pii. Để tuân thủ ở quy mô doanh nghiệp, gói Business $19 cung cấp batch API và lưu trữ audit log trong 12 tháng.