
Phát hiện ngôn ngữ trong văn bản đa ngôn ngữ
Tại sao tự động phát hiện ngôn ngữ lại hữu ích
Các tình huống thực tế:
- Chatbot đa ngôn ngữ: người dùng viết "Hola, como estoy?" → phát hiện tiếng Tây Ban Nha → trả lời bằng tiếng Tây Ban Nha (thay vì ngôn ngữ mặc định)
- Bảng tin toàn cầu: trình tổng hợp tin tức cần nhóm bài viết theo ngôn ngữ trước khi dịch
- Hỗ trợ khách hàng: ticket bằng tiếng Nhật cần được chuyển đến đội Nhật Bản, không phải đội khác
- Kiểm duyệt nội dung: quy tắc về nội dung nhạy cảm thay đổi theo khu vực và ngôn ngữ
- Analytics: đo lường sự đa dạng ngôn ngữ trong cộng đồng người dùng của bạn
Mô hình fastText language identification, mã nguồn mở từ Facebook, phát hiện 176 ngôn ngữ trong chưa đến 10ms mỗi đoạn văn bản.
Mô hình phân biệt ngôn ngữ như thế nào
fastText biểu diễn mỗi từ dưới dạng n-gram ký tự (subwords), sau đó tổng hợp các vector đó và phân loại bằng hồi quy softmax. Lý do hoạt động hiệu quả:
- Tiếng Bồ Đào Nha có các đặc trưng "ção", "nh", "lh"
- Tiếng Anh có các đặc trưng "th", "ing", "ed"
- Tiếng Đức có "sch", "ch", "äöü"
- Tiếng Trung viết bằng pinyin có các mẫu hoàn toàn khác so với hanzi
Mô hình nhìn vào dấu hiệu thống kê của các n-gram để đưa ra quyết định. Văn bản ngắn (dưới 3 từ) thường mơ hồ; văn bản từ 20 từ trở lên đạt độ chính xác > 99%.
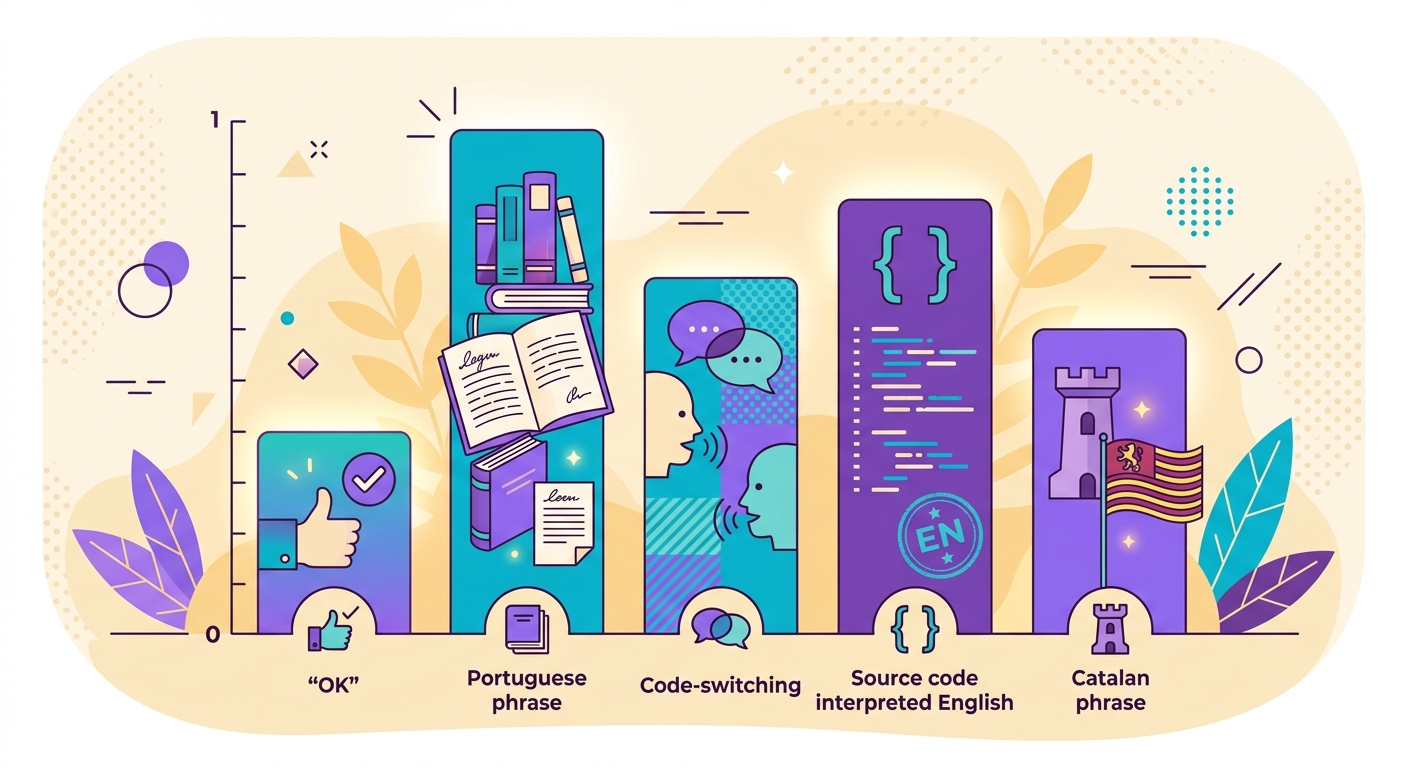
Các trường hợp khó và cách xử lý
- Code-switching: văn bản trộn lẫn 2 ngôn ngữ ("Hello, tudo bem?") — mô hình trả về ngôn ngữ chiếm ưu thế kèm score thấp hơn
- Ngôn ngữ gần nhau: tiếng Bồ Đào Nha vs Tây Ban Nha vs Catalan — fastText đạt 90%+ nhưng vẫn có trường hợp ranh giới mờ
- Phiên âm: tiếng Trung viết bằng pinyin, tiếng Ả Rập bằng chữ Latin — mô hình có thể nhận nhầm là "tiếng Anh"
- Văn bản quá ngắn: "OK" có thể thuộc bất kỳ ngôn ngữ nào — luôn trả về score thấp, bạn nên dùng ngưỡng threshold
- Mã nguồn lập trình: code thường bị nhận diện là "tiếng Anh" — nên lọc trước nếu cần
Ngưỡng khuyến nghị: chỉ chấp nhận kết quả phát hiện khi confidence > 0.75. Dưới mức đó, đánh dấu là "unknown" và chuyển cho con người xử lý.
Tích hợp vào stack của bạn
Ví dụ Python điển hình:
`python
import httpx
r = httpx.post(
"https://api.brainiall.com/api/nlp/language",
json={"text": "Hola, ¿cómo estás hoy?"},
headers={"Authorization": "Bearer brnl-xxx"}
)
# {"language": "es", "confidence": 0.96, "top_3": [
# {"lang": "es", "conf": 0.96},
# {"lang": "pt", "conf": 0.02},
# {"lang": "ca", "conf": 0.01}
# ]}`
Sử dụng top_3 khi bạn muốn hiển thị các lựa chọn thay thế trong trường hợp độ tin cậy thấp (ví dụ: "Có vẻ là tiếng Tây Ban Nha, nhưng cũng có thể là tiếng Catalan — vui lòng xác nhận").
Các trường hợp sử dụng nâng cao
- Tiền xử lý NLP: trước khi phân tích cảm xúc, phát hiện ngôn ngữ và định tuyến đến mô hình phù hợp
- Lọc dữ liệu: loại bỏ văn bản không thuộc ngôn ngữ mục tiêu trong các tập dữ liệu lớn
- Định tuyến lưu lượng: cân bằng tải giữa các cluster đa ngôn ngữ
- Phân đoạn: chia tài liệu dài theo ngôn ngữ khi nội dung bị trộn lẫn
- Tìm kiếm: cho phép người dùng lọc "chỉ hiển thị nội dung bằng tiếng Việt trên nền tảng này"
Dùng thử ngay bây giờ
Nhập "phát hiện ngôn ngữ của đoạn văn bản này: [dán vào]" trong chat Brainiall. API tại /api/nlp/language. Độ trễ thông thường < 10ms — phù hợp cho các ứng dụng real-time. Gói Pro có hạn mức sử dụng rộng rãi; gói Business bao gồm batch API.