
GPT-5 vs Claude Sonnet vs Gemini 3 Pro: nên chọn cái nào?
Lựa chọn mô hình quan trọng hơn bạn nghĩ
Vào năm 2026, sự khác biệt giữa các mô hình top-tier là rõ rệt trong từng tác vụ cụ thể. Bỏ qua việc thử nghiệm 2-3 lựa chọn và đi thẳng với cái nổi tiếng nhất (GPT) có thể khiến bạn tốn gấp 2-3 lần token hoặc nhận kết quả kém hơn 20% cho trường hợp của bạn.
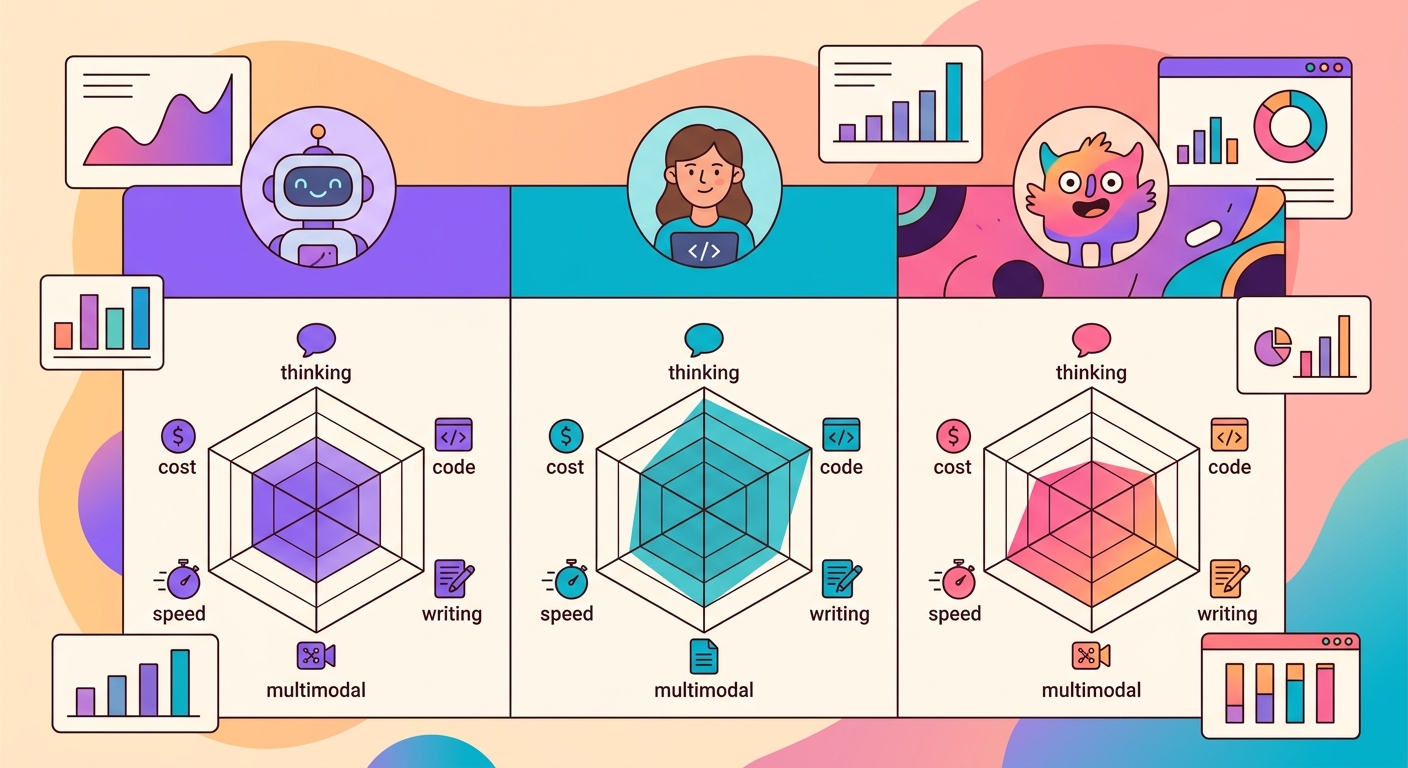
3 mô hình thống trị trên Brainiall:
- Claude Sonnet 4.6 (Anthropic): tốt nhất cho lập luận phức tạp, viết văn bản dài, lập trình
- GPT-5 (OpenAI): tốt nhất cho đa phương thức (hình ảnh + văn bản + code), sáng tạo
- Gemini 3 Pro (Google): tốt nhất cho ngữ cảnh cực lớn (1M+ token), độ trễ thấp
Chi phí thực tế năm 2026 (mỗi triệu token)
| Mô hình | Input | Output | Ghi chú |
|--------|-------|--------|-------|
| Claude Sonnet 4.6 | R$ 15 | R$ 75 | Cache hit giảm input 10 lần |
| GPT-5 | R$ 12 | R$ 60 | Rẻ hơn theo token |
| Gemini 3 Pro | R$ 7 | R$ 35 | Chi phí/chất lượng tốt nhất |
| Claude Haiku 4.5 | R$ 2 | R$ 10 | Nhanh, phù hợp tác vụ đơn giản |
Với một chatbot hội thoại trung bình (100 tin nhắn, ~500 token mỗi tin), chi phí hàng ngày rơi vào khoảng R$ 10-50. Với ứng dụng xử lý hàng loạt (phân tích 10.000 tài liệu), con số này tăng lên R$ 500-2000.
Khi nào dùng từng mô hình
Claude Sonnet 4.6 cho:
- Soạn thảo tài liệu dài (báo cáo, bài luận, phân tích pháp lý)
- Code review và refactoring
- Phân tích sắc thái trong văn bản (văn học, triết học)
- Tác vụ đòi hỏi tuân theo hướng dẫn phức tạp
- Agent với chuỗi lập luận dài
GPT-5 cho:
- Phản hồi sáng tạo mở (brainstorming, kịch bản)
- Đa phương thức khi hình ảnh + văn bản đều quan trọng
- Phản hồi nhanh và trực tiếp
- Trường hợp bạn muốn "mô hình tổng quát nhất có thể"
- Code Python và JavaScript tiêu chuẩn
Gemini 3 Pro cho:
- Xử lý tài liệu khổng lồ (sách, toàn bộ codebase)
- Ứng dụng yêu cầu độ trễ thấp (<1 giây)
- Phân tích video (đa phương thức video gốc)
- Tác vụ khoa học và toán học
- Triển khai quy mô lớn khi chi phí là yếu tố quan trọng
Kiểm thử trường hợp của bạn với 3 pipeline giống hệt nhau
Đừng tin vào các benchmark chung chung. Hãy tự tạo bộ đánh giá của mình:
1. Chọn 20 ví dụ đại diện cho cách dùng thực tế của bạn
2. Chạy cùng một prompt trên cả 3 mô hình
3. Đánh giá kết quả ẩn danh (không biết cái nào là cái nào)
4. Đo lường: độ chính xác, độ trễ, chi phí
Nhiều khi mô hình "kém hơn" theo benchmark chung lại là tốt nhất cho trường hợp của bạn, vì tác vụ của bạn có những đặc điểm riêng mà benchmark không nắm bắt được.
Sử dụng qua Brainiall
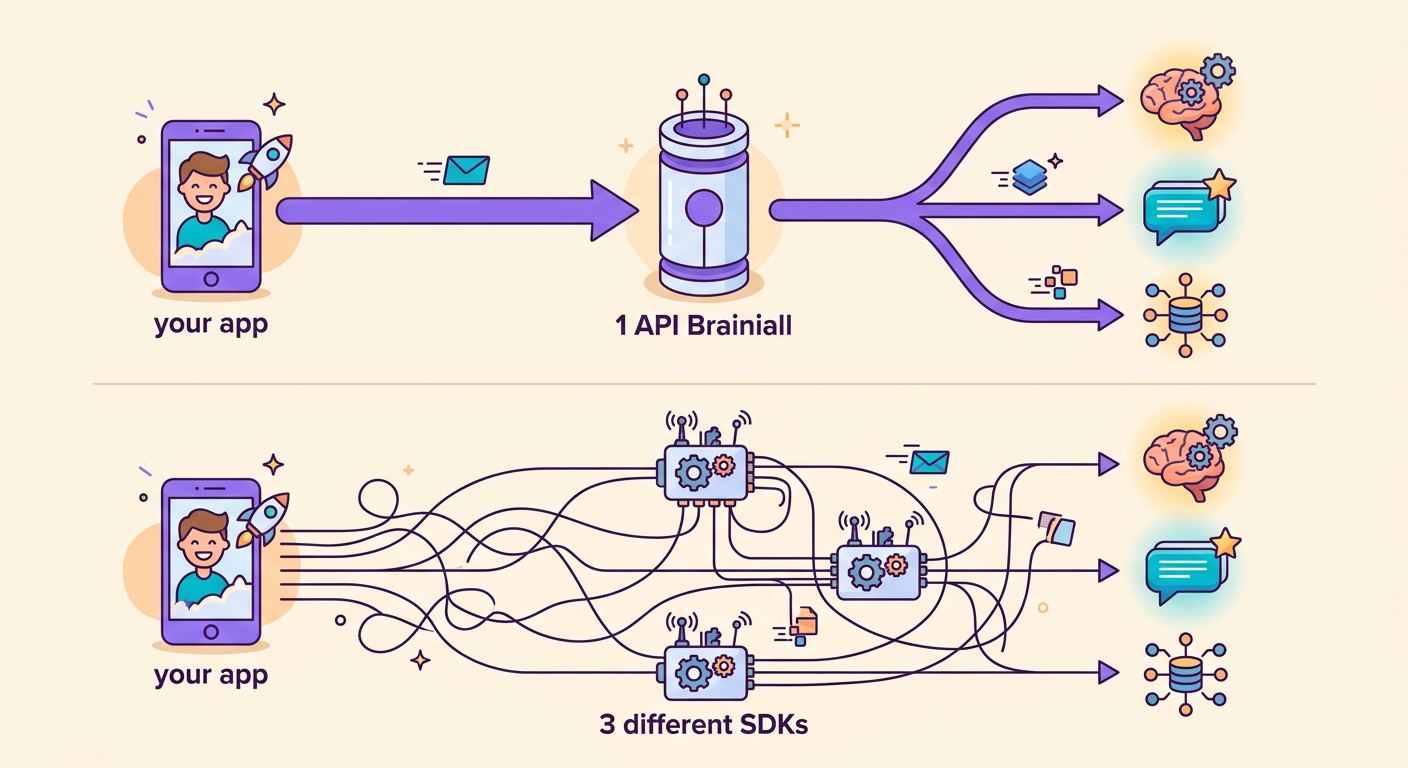
Lợi thế lớn nhất của gateway chúng tôi: bạn đổi mô hình chỉ bằng cách thay 1 chuỗi ký tự.
`python
import httpx
def ask(model, prompt):
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={"model": model, "messages": [{"role":"user","content":prompt}]},
headers={"Authorization": "Bearer brnl-xxx"}
)
return r.json()["choices"][0]["message"]["content"]
for m in ["claude-sonnet-4-6", "gpt-5", "gemini-3-pro"]:
print(m, ":", ask(m, "Explique entropia em 3 frases."))`
Không có Brainiall, bạn sẽ cần 3 tài khoản, 3 SDK, 3 hệ thống thanh toán riêng biệt. Với gateway duy nhất, mọi thứ trở nên minh bạch và liền mạch.
Những bẫy thường gặp khi so sánh
- Prompt không trung lập: nếu prompt của bạn được tối ưu cho GPT, Claude có thể trông kém hơn một cách không công bằng
- Chỉ một ví dụ: độ biến thiên giữa các lần chạy rất cao; hãy thực hiện tối thiểu N=20+
- Sai chỉ số đo: chỉ đo độ chính xác sẽ bỏ qua chi phí/độ trễ/độ ổn định
- Bỏ qua cache: Claude có cache prompt giúp giảm chi phí 10 lần cho các hệ thống lặp lại
- Không kiểm thử bằng tiếng Việt: tất cả đều tốt bằng tiếng Anh; với tiếng Việt, sự khác biệt rõ rệt hơn nhiều
Thử ngay bây giờ
Trong chat Brainiall, chọn một mô hình từ menu thả xuống phía trên và đặt câu hỏi của bạn. Sau đó chuyển sang mô hình khác và so sánh. Gói Pro $5.99 cho phép truy cập 15 mô hình; gói Business mở khóa tất cả.