
Nhân bản giọng nói của bạn chỉ với 10 giây âm thanh
Tại sao 10 giây là đủ ngày nay (nhưng 2 năm trước thì không)
Cho đến năm 2023, việc nhân bản giọng nói đòi hỏi từ 30 phút đến vài giờ thu âm sạch trong phòng thu, đọc theo một kịch bản cụ thể. Ngày nay, các mô hình như Kokoro TTS và XTTS v2 có thể làm điều tương tự chỉ với 6 đến 15 giây âm thanh tham chiếu, trong bất kỳ môi trường nào tương đối yên tĩnh.
Điều gì đã thay đổi? Kiến trúc mô hình. Các mô hình hiện đại tách biệt những gì bạn nói (nội dung) khỏi cách bạn nói (âm sắc, ngữ điệu, nhịp điệu). Một encoder nhỏ gọn trích xuất "hồ sơ giọng nói" của bạn chỉ trong vài trăm mili giây; sau đó, bất kỳ văn bản nào cũng có thể được tổng hợp bằng hồ sơ đó. Bản thân mô hình tổng hợp đã biết cách nói tiếng Việt, tiếng Anh hay ngôn ngữ khác — nó chỉ đang "tô màu" văn bản bằng giọng nói của bạn.
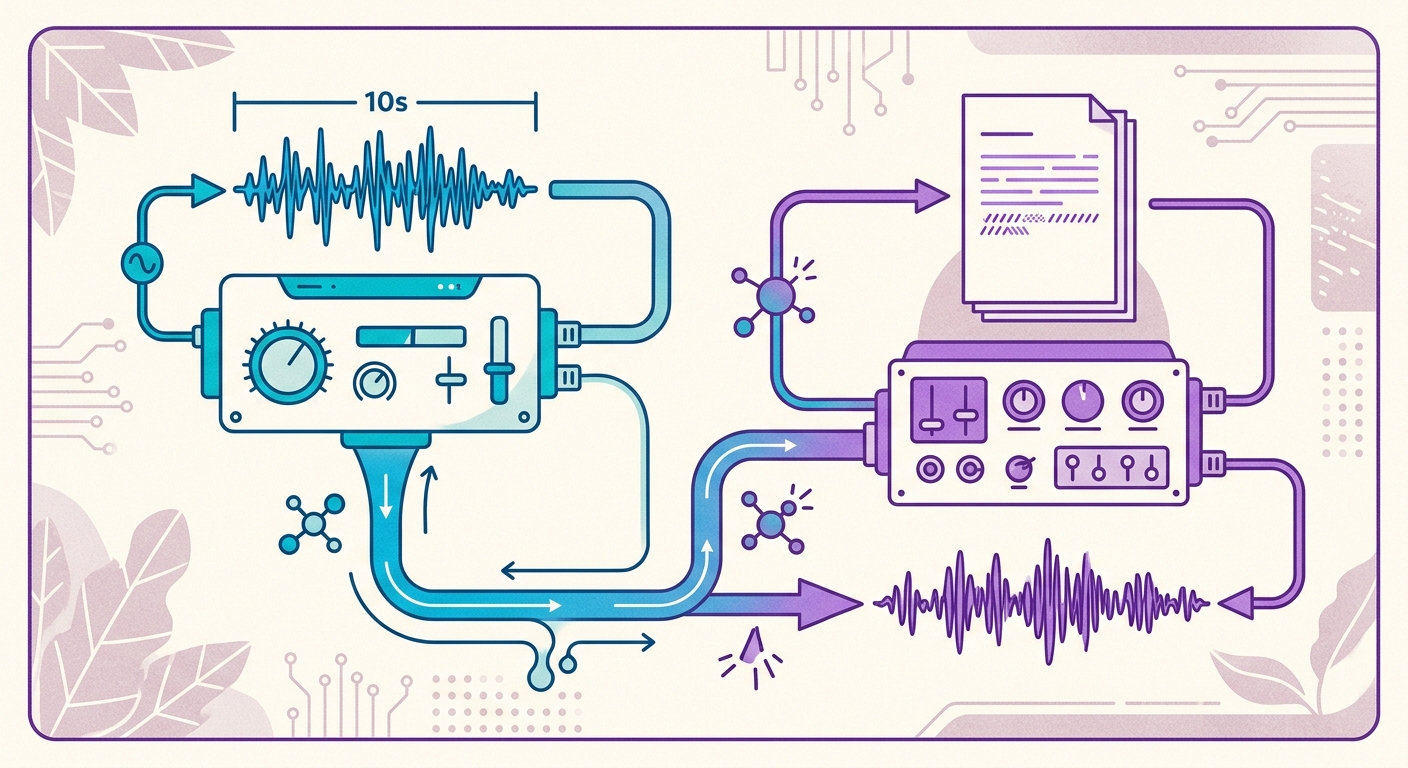
Pipeline của Brainiall trong thực tế
Tại Brainiall, chúng tôi sử dụng mô hình giọng nói gốc chạy trên GPU chuyên dụng, với 54 giọng đọc được huấn luyện sẵn trong 9 ngôn ngữ — bao gồm 3 giọng neural tiếng Việt (pf_dora, pm_alex, pm_santa). Để nhân bản một giọng nói mới, quy trình diễn ra như sau:
1. Bạn thu âm 10 giây nói bất kỳ nội dung gì bằng tiếng Việt (ví dụ: đọc đoạn văn này)
2. Encoder trích xuất "voice embedding" của bạn — một vector gồm 512 con số
3. Synthesizer nhận văn bản bạn muốn đọc + embedding của bạn
4. Bạn nhận lại file MP3 trong 2-4 giây (thời gian thực < 1, tức là tổng hợp nhanh hơn chính đoạn âm thanh đầu ra)
Khi nào nghe tự nhiên, khi nào vẫn còn robot
Kết quả xuất sắc khi:
- Âm thanh tham chiếu của bạn sạch (tiếng ồn nền thấp, không có tiếng vang)
- Bạn nói với giọng trung tính, không có tiếng cười hay thán từ thái quá
- Văn bản cần đọc cùng ngôn ngữ với mẫu âm thanh
- Câu ngắn đến trung bình (tối đa 30 từ mỗi câu)
Vẫn còn hạn chế khi:
- Bạn yêu cầu cảm xúc quá cụ thể (tức giận dữ dội, khóc lóc)
- Văn bản có nhiều tên nước ngoài hoặc thuật ngữ kỹ thuật hiếm gặp
- Mẫu gốc có tiếng ồn môi trường — mô hình sẽ sao chép cả tiếng ồn đó
- Âm thanh quá dài (>2 phút) bắt đầu bị "drift" về mặt ngữ điệu
Giới hạn đạo đức (quan trọng)
Nhân bản giọng nói mà không có sự đồng ý là vấn đề pháp lý và đạo đức nghiêm trọng. Tại Brainiall:
- Giọng nói được nhân bản gắn liền với tài khoản của bạn và chỉ bạn mới có thể sử dụng
- Chúng tôi không bao giờ nhân bản giọng nói của bên thứ ba từ các âm thanh công khai mà không có sự cho phép rõ ràng từ chủ sở hữu
- Nội dung được tạo ra sẽ qua kiểm duyệt trước khi giao (chúng tôi phát hiện các nỗ lực mạo danh chính trị hoặc người nổi tiếng)
- Bạn có thể xóa voice embedding của mình bất cứ lúc nào trong Dữ liệu của tôi
Voice cloning có những ứng dụng hợp pháp mạnh mẽ: đọc sách bằng chính giọng của bạn, tạo nội dung đa ngôn ngữ trong khi vẫn giữ bản sắc cá nhân, hỗ trợ tiếp cận cho những người đã mất khả năng nói. Hãy sử dụng có trách nhiệm.
Thử ngay bây giờ
Trong chat Brainiall, nhấp vào biểu tượng micro ở ô nhập liệu, thu âm 10 giây (bất kỳ nội dung gì), sau đó nhập văn bản bạn muốn đọc. Bản thân tính năng nhân bản là miễn phí với tối đa 3 lần thử mỗi tháng. Gói Pro giúp bạn mở khóa 100 hình ảnh và 10 video/tháng, cùng với 54 giọng đọc có sẵn — nhiều trong số đó đã nghe tự nhiên hơn cả giọng nhân bản từ người dùng nghiệp dư.