
Narrate any text in 9 languages with 54 neural voices
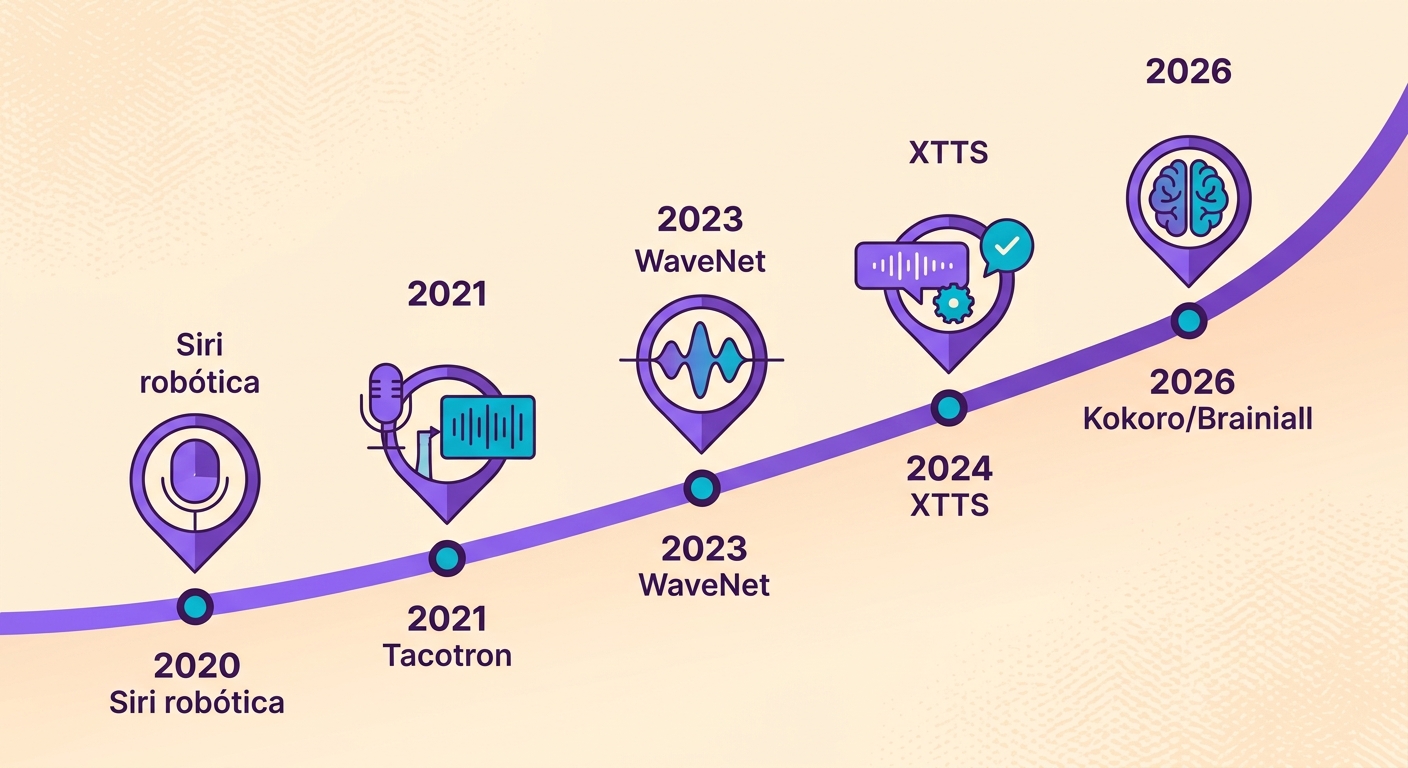
The evolution of TTS over 5 years
Until 2020, Text-to-Speech sounded robotic — think the original Siri era. From 2021 to 2023, we learned to use WaveNet and Tacotron models to achieve natural-sounding voices. From 2024 onward, a new generation of models (XTTS, Kokoro, VALL-E) brought three game-changing advances:
1. Small footprint: Kokoro has just 82 million parameters — 100× smaller than the old giants, yet delivers the same quality
2. Real-time inference: RTF (Real-Time Factor) < 0.2 on an entry-level GPU; meaning 1 minute of audio is synthesized in under 12 seconds
3. Natural prosody: intonation, emphasis, rhythm — no more "monotone with a comma"
Brainiall's 9 languages
- Brazilian Portuguese: pf_dora (adult female), pm_alex, pm_santa (male)
- American English: af_heart, af_bella, af_nicole, am_adam, am_michael
- British English: bf_emma, bm_george, bm_lewis
- Spanish: ef_lucia, em_carlos
- French: ff_juliette, fm_louis
- German: gf_sophia, gm_max
- Italian: if_chiara, im_marco
- Mandarin Chinese: zf_mei, zm_wei
- Japanese: jf_haruka, jm_kenji
Each voice has its own personality: pf_dora is clear and educational (we use her in Brainiall Academy courses), am_adam has a corporate professional tone, and af_heart carries a more emotional feel.
How to choose the right voice for the context
- E-learning / tutorials: neutral and articulate voices (pf_dora, am_adam)
- Marketing / ads: dynamic and expressive voices (af_heart, am_michael)
- Audiobooks: warm and narrative voices (af_bella, bm_george)
- News: formal and clear voices (pm_santa, am_adam)
- Chatbots / assistants: friendly and fast voices (af_nicole, pm_alex)
Pro tip: generate 3–5 seconds of test audio with 3 candidate voices before synthesizing a long text. Preference is always subjective.
Controlling speed and pitch
The most useful parameters:
- speed: 0.25 to 4.0 — default 1.0. Use 0.85 for audiobooks (calm narration), 1.15 for educational content, 1.3+ only for quick previews
- format: mp3, wav, ogg. MP3 is the default (best compression); WAV when you plan to edit the audio afterward; OGG for web streaming
- pitch: some models support it — adjust in semitones (-5 to +5)
Avoid extremes: speed > 2.0 becomes incomprehensible, and < 0.5 sounds unnatural.
Technical and usage limits
- Maximum per request: 4,000 characters — roughly 4 paragraphs. Longer texts require chunking
- Mixed languages: each voice performs best in its primary language; mixing (e.g., Portuguese text with English words) may result in hesitant pronunciation
- Foreign proper nouns: spell them out phonetically in the prompt — "Maicrosoft" instead of "Microsoft"
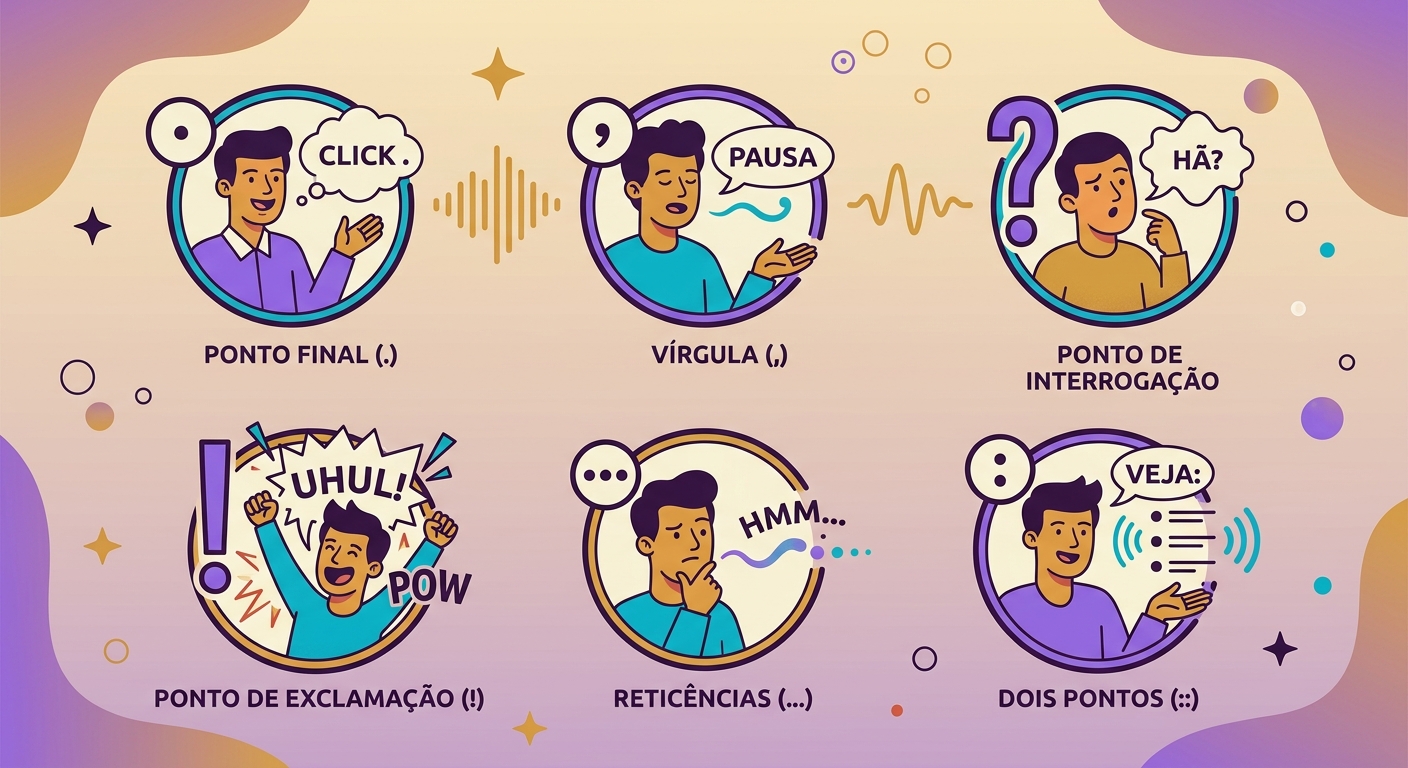
- Punctuation matters: commas = short pause, ellipses = long pause, period = falling tone
- Emojis: most models ignore them or read them as words ("smiling") — remove them beforehand
Practical use cases
- Course narration: just like we do at the Academy — fast, affordable, and consistent
- Home audiobooks: convert PDFs/EPUBs into MP3s to listen to on the go
- Accessibility: turn your blog into audio for readers with reading difficulties
- Automated podcasts: convert newsletters into podcast format for distribution
- Video voiceovers: replace expensive voice-over work with TTS when precise timing isn't critical
Try it right now
In the Brainiall chat, send a message and click the 🔊 icon on the response to hear it with TTS. Or use the /api/tts route via API. The Pro plan at $29 allows generous TTS usage; the Business plan at $99 includes API credits for external integrations.