
Conversa con un PDF de 300 páginas
Por qué los PDFs son un problema especial
Los PDFs son difíciles porque combinan 3 mundos:
1. Texto estructurado: párrafos, listas, notas al pie
2. Layout visual: columnas, tablas, diagramas, gráficos
3. Imágenes: fotos, logos, capturas de pantalla incrustadas
El PDF es un formato visual-first: preserva la apariencia en cualquier dispositivo. Pero el texto es solo un subproducto — extraer el contenido semántico original no siempre es sencillo.
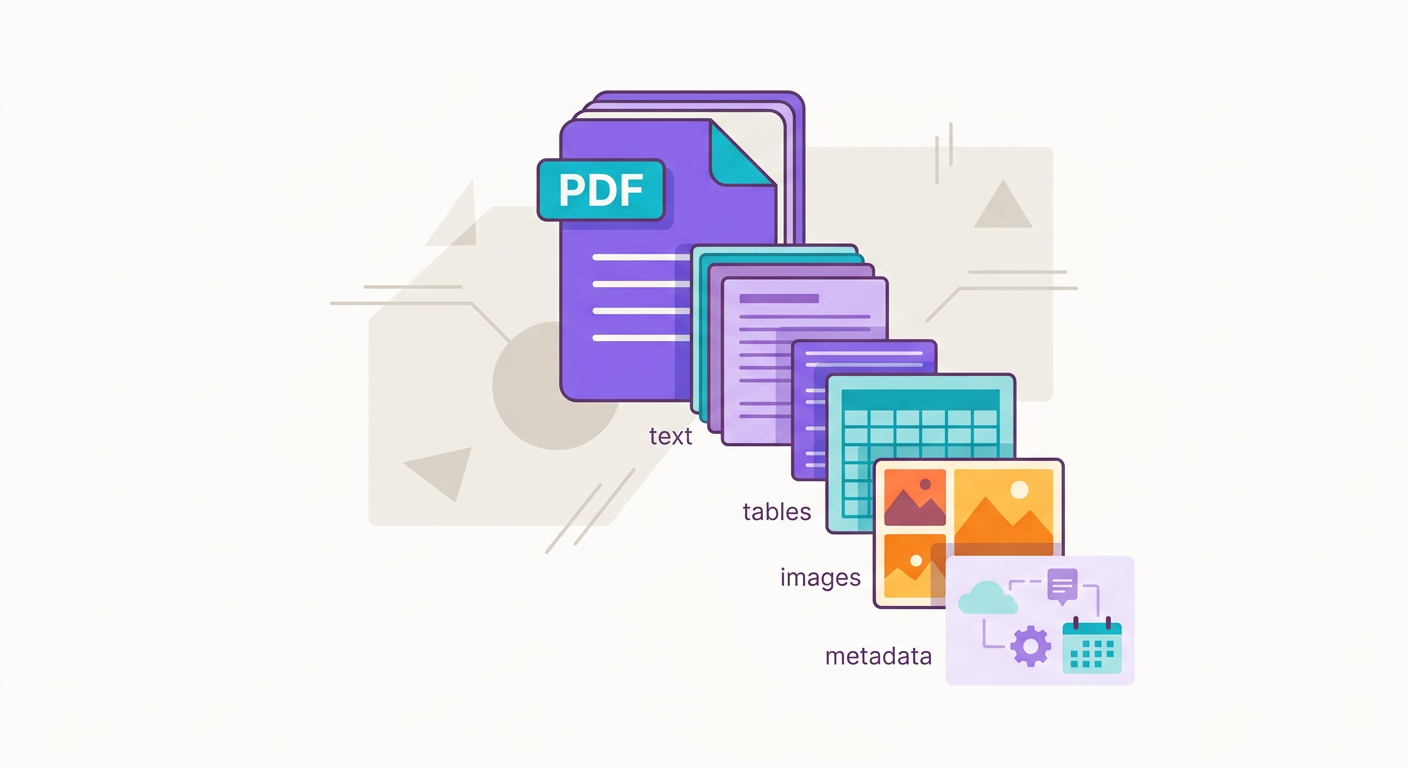
En Brainiall, cuando envías un PDF:
- Extrae texto raw (pdfplumber o pdfium)
- Detecta tablas (camelot o tabula)
- Convierte páginas en imágenes
- Aplica OCR (Whisper-OCR o Mistral-OCR) en páginas sin texto extraíble
- Descubre la estructura jerárquica (encabezados, secciones)
- Opcionalmente: resume + vectoriza para RAG
Flujo de conversación: RAG vs contexto completo
Dos estrategias según el tamaño:
PDF < 50 páginas (~100k tokens):
- Envía el texto completo en el prompt de Claude Sonnet o Gemini Pro
- El modelo "ve" todo y responde basándose en el contexto completo
- Ventaja: no se pierde ninguna información
- Desventaja: costoso para múltiples preguntas (cada request reprocesa el PDF)
PDF > 50 páginas:
- Usa RAG (Retrieval Augmented Generation)
- Divide el PDF en chunks de ~500 tokens
- Vectoriza cada chunk
- Ante la pregunta del usuario, busca los 5-10 chunks semánticamente más relevantes
- Envía SOLO esos chunks en el prompt
- Ventaja: económico + escalable
- Desventaja: si el modelo necesita conectar información de partes distantes, puede perder contexto
Brainiall decide automáticamente qué estrategia usar según el tamaño del PDF.
Casos de uso prácticos
- Documentos legales: conversar con un contrato de 80 páginas para encontrar cláusulas
- Papers académicos: "¿cuáles son los principales argumentos en contra de la tesis del autor?"
- Informes financieros: "compara el crecimiento del Q3 vs Q4 en este 10-K"
- Manuales técnicos: "¿cuál es el procedimiento para resetear el equipo?"
- Libros de texto: tutoría privada sobre cualquier tema
- Expedientes jurídicos: buscar fechas, partes y hechos relevantes en autos de 500+ páginas
Errores comunes a evitar
- Tablas complejas: las tablas anidadas o combinadas pueden salir confusas en el texto extraído; usa OCR de imágenes como fallback
- Fórmulas matemáticas: el LaTeX en PDFs se convierte en texto ilegible; los modelos vision lo resuelven mejor
- Documentos digitalizados antiguos: los PDFs que son solo imágenes (sin texto) requieren OCR que puede cometer errores
- Idiomas poco comunes: las lenguas con pocos recursos tienen peor OCR
- PDF con seguridad: los PDFs con protección de copia pueden bloquear la extracción — se necesita contraseña
Preguntas que funcionan bien vs. mal
Bien:
- "¿Cuál es el argumento central del capítulo 3?"
- "Lista todas las fechas mencionadas en este informe"
- "Compara las conclusiones de la sección 4 y la sección 7"
- "¿Cuál fue el ingreso neto en 2025?"
Mal:
- "Resume este PDF completo en 2 párrafos" (requiere contexto completo que puede perderse en RAG)
- "¿Cuál es el tono emocional del autor al final?" (matiz difícil de capturar en chunks)
- "¿Qué hay en la imagen de la página 45?" (requiere vision específico)

Integración vía API
`python
import httpx
# Primero, sube el PDF
with open("contrato.pdf", "rb") as f:
r = httpx.post(
"https://api.brainiall.com/v1/files",
files={"file": f},
headers={"Authorization": "Bearer brnl-xxx"}
)
file_id = r.json()["id"]
# Luego, chat referenciando el archivo
r = httpx.post(
"https://api.brainiall.com/v1/chat/completions",
json={
"model": "claude-sonnet-4-6",
"messages": [
{"role": "user", "content": [
{"type": "text", "text": "Lista todas las partes de este contrato"},
{"type": "file", "file_id": file_id}
]}
]
},
headers={"Authorization": "Bearer brnl-xxx"}
)`
Pruébalo ahora mismo
En el chat de Brainiall, arrastra un PDF al área de entrada y haz tus preguntas. Hasta 10MB por archivo. El plan Pro a US$5.99 permite una carga generosa; el plan Business incluye procesamiento en batch + retención por 30 días.