
Detect toxicity in comments with AI
The Perspective apocalypse: what happened
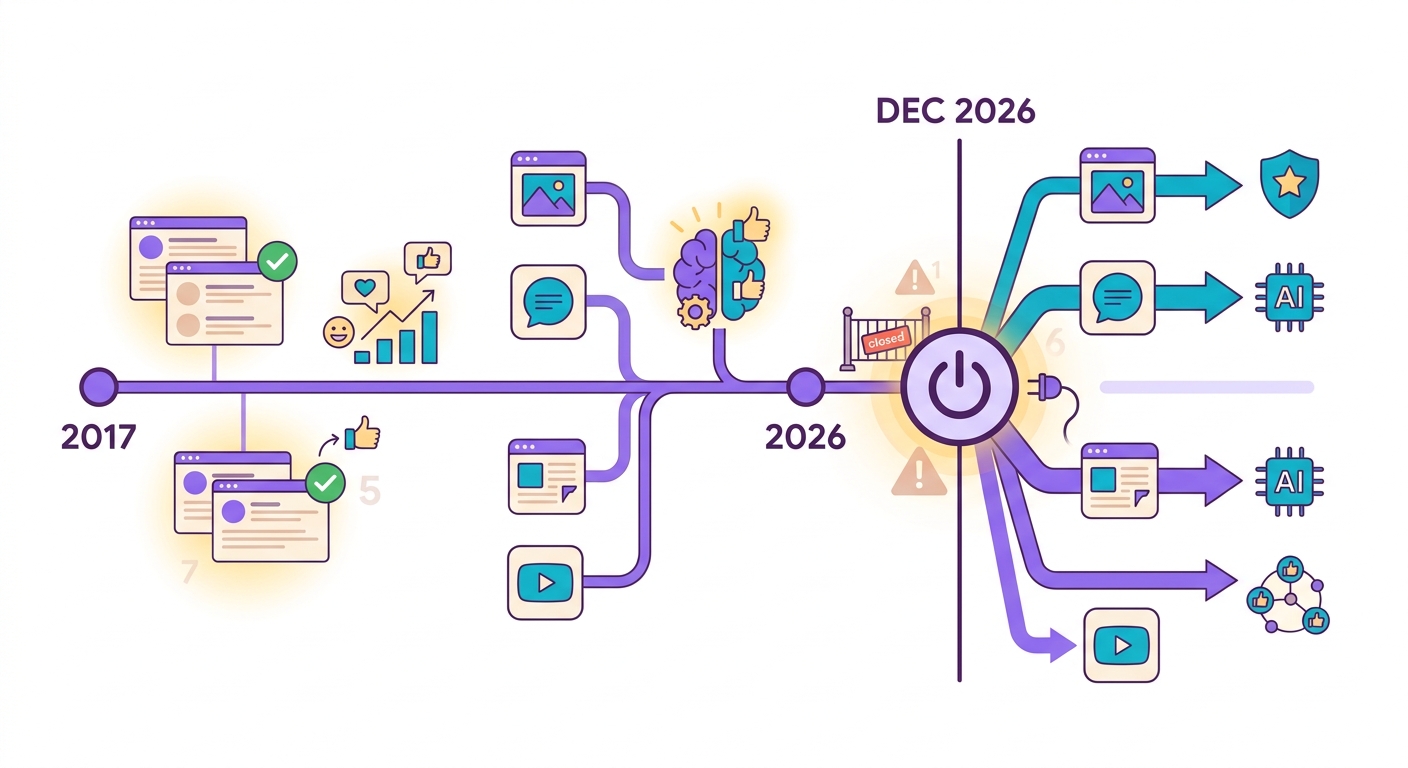
In October 2024, Google announced that the Perspective API — the world's most widely used free toxicity detection service — would be discontinued in December 2026. Platforms that depended on it (Reddit, The New York Times, The Guardian, thousands of forums) have 2 years to migrate.
The problem: Perspective was free. Commercial alternatives like Azure Content Safety and AWS Comprehend charge starting at $1 per 1,000 analyses. For a large forum with 100k comments/day, that adds up to $3k/month just for moderation.
Brainiall offers moderation with Detoxify + Unitary models running on local ONNX (CPU), costing less than $0.0002 per analysis — 100x cheaper.
The 7 categories that matter
Detoxify classifies text across 7 dimensions with a score from 0 to 1:
1. Toxicity: general insults, aggressiveness
2. Severe toxicity: threats, extreme hate
3. Obscene: profanity and crude language
4. Threat: threats of physical violence
5. Insult: direct personal attacks
6. Identity hate: discrimination based on group identity (race, gender, religion)
7. Sexual explicit: sexually explicit content
Your policy sets the thresholds. A common example: block if severe_toxicity > 0.5 OR identity_hate > 0.6 OR threat > 0.3. Isolated profanity (obscene > 0.8) typically gets a warning rather than a block.
The challenge with non-English languages
Detoxify was trained on English. It performs at 95%+ on English comments. In other languages, accuracy can drop to 75–85% — regional expressions and slang (many of which are not offensive) can confuse the model.
At Brainiall, we use an additional layer: a hybrid classifier that combines:
- Multilingual Detoxify (70% of the decision)
- A language-specific word list (20%)
- A small LLM (Gemma 3 or similar) for borderline cases (10%)
This brings accuracy up to 92%+ while keeping latency under 80ms.
When AI gets it dangerously wrong
- Sarcasm: "I just loved how you ruined my life, thanks!" — positive score, but the text is hostile
- Legitimate satire: humorous political criticism can be flagged as an attack
- Medical context: "I'm going to kill this patient with all this work" (an exhausted healthcare worker) — false positive flag
- Quotations: an article quoting a racist post in order to criticize it gets analyzed as if it were the racist content itself
- Code-switching: mixing languages and emojis can confuse the model
Practical solution: combine the automatic score with soft-moderation (asking for confirmation before publishing) instead of a hard-block for borderline cases.
Integrating into your platform
Recommended flow:
1. User types a comment → fetch POST /api/toxicity with { text }
2. API returns { toxicity, severe, threat, insult, identity_hate, obscene, sexual }
3. Your code decides: block, warn, or approve
4. If warn, show "Please review — this may offend some users" before publishing
5. For blocks, log the event + notify human moderation
Don't rely on 100% automated moderation. Always maintain a human review queue for borderline cases.
Try it right now
In the Brainiall chat, ask "analyze the toxicity of this comment: [paste here]". Or use the API at the /api/nlp/toxicity route. The Pro plan includes 10,000 analyses/month; the Business plan adds a priority queue and batch processing for millions of entries.