
Clone your voice with 10 seconds of audio
Why 10 seconds is enough today (it wasn't 2 years ago)
Until 2023, cloning a voice required anywhere from 30 minutes to several hours of clean studio recordings, reading a specific corpus. Today, models like Kokoro TTS and XTTS v2 do the same job with just 6 to 15 seconds of reference audio, in any reasonably quiet environment.
What changed? Architecture. Modern models separate what you say (content) from how you say it (timbre, prosody, rhythm). A small encoder extracts your "vocal profile" in just a few hundred milliseconds; from there, any text can be synthesized using that profile. The synthesis model already knows how to speak Portuguese, English, or other languages — it's simply "painting" the text with your voice.
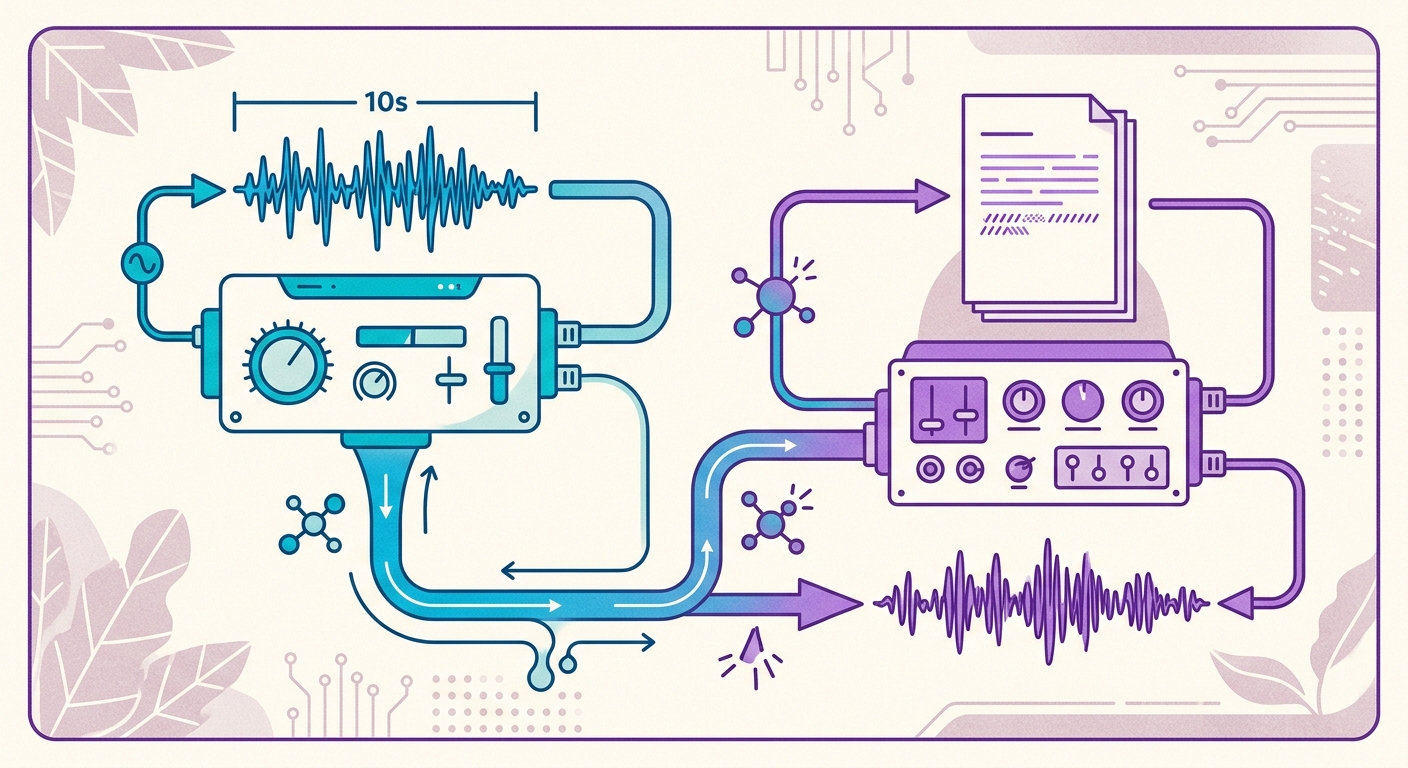
The Brainiall pipeline in practice
At Brainiall, we use a native voice model running on a dedicated GPU, with 54 pre-trained voices across 9 languages — including 3 neural voices in Brazilian Portuguese (pf_dora, pm_alex, pm_santa). To clone a new voice, the flow is:
1. You record 10 seconds of yourself speaking anything in Portuguese (for example, reading this paragraph)
2. The encoder extracts your "voice embedding" — a vector of 512 numbers
3. The synthesizer receives the text you want narrated + your embedding
4. You get an MP3 back in 2–4 seconds (real-time factor < 1, meaning synthesis is faster than the final audio itself)
When it sounds natural, when it still sounds robotic
Sounds great when:
- Your reference audio is clean (low background noise, no echo)
- You speak in a neutral tone, without laughter or extreme interjections
- The text to be narrated is in the same language as the sample
- Sentences are short to medium length (up to 30 words per sentence)
Still struggles when:
- You ask for very specific emotions (explosive anger, crying)
- The text contains many foreign names or rare technical jargon
- The original sample had ambient noise — the model copies the noise along with your voice
- Very long audio (>2 minutes) starts to "drift" prosodically
The ethical limits (important)
Cloning someone's voice without consent is a serious legal and ethical issue. At Brainiall:
- Cloned voices are tied to your account and only you can use them
- We never clone third-party voices from public audio without explicit permission from the owner
- Generated content goes through moderation before delivery (we detect impersonation attempts targeting public figures or politicians)
- You can delete your voice embedding at any time under My Data (LGPD)
Voice cloning has powerful legitimate uses: narrating books in your own voice, creating content in multiple languages while preserving your identity, and accessibility for people who have lost the ability to speak. Use it responsibly.
Try it right now
In the Brainiall chat, click the microphone in the input field, record 10 seconds of anything you'd like to say, then type a text for it to narrate. Cloning itself is free for up to 3 attempts per month. The Pro plan at $29 unlocks 100 images and 10 videos/month, plus all 54 ready-made voices — many of which already sound more natural than an amateur cloned voice.